opecv入门:K近邻算法
K近邻算法
机器学习算法是从数据中产生模型,也就是进行学习的算法,我们提供经验给算法,它可以根据经验产生模型, 面对新的情况时,模型就会给我们提供判断(预测)结果。从数据中学得模型的过程称为学习或者训练,在训练过程中使用的数据称为训练数据,每个样本称为训练样本,训练样本所组成的集合称为训练集。
如果希望获取一个模型,除了数据还有给样本贴上对应的标签,例如,((个子高、腿长、体重轻),好苗子)就是拥有标签的样本,称为样例。
学得模型后,为了测试模型得效果还有对其进行测试,被测试得样本就是测试样本,输入测试样本时,不提供标签(目标类别),而是由模型决定样本得标签(属于那个类),比较测试样本预测得标签与实际样本标签之间的差别,就可以计算出模型的精确度。。。这就是机器学习嘛。。
大多数机器学习算法都来源于生活实践,K 近邻算法就是最简单的机器学习算法之一。。。主要用于将对象划分到已知类中,例如,教练选运动员,选择个子高,腿长,轻等特征的候选人,这些人的特征核运动员的特征很相近。。
理论基础
K近邻算法本质就是将指定对象根据已知特征值分类,例如,通过年龄特征判断老人和孩子。在实际场景中,会有多个特征维度。例如,为一段视频分类,判断时乒乓球还是足球比赛。
首先定义两个特征,一个是 挥手动作,一个是踢脚动作 ,统计特定时间内这两个动作的次数,发现:乒乓球中挥手动作远多于踢脚动作,足球中,踢脚远多于挥手。
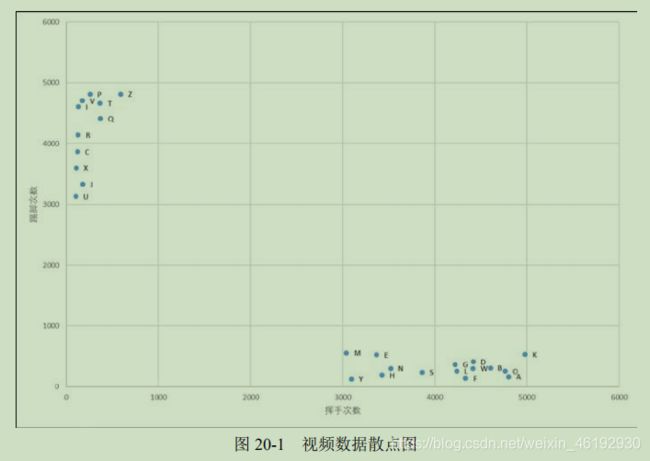
每个点对应一个样本,可以发现数据点呈现聚集特征:
- 乒乓球比赛视频中的数据点聚集在 x 轴坐标为[3000, 5000],y 轴坐标为[1,500]的区域。
- 足球比赛视频中的数据点聚集在 y 轴坐标为[3000, 5000],x 轴坐标为[1,500]的区域。
此时,有一个视频,挥手2000,踢脚100次,绘制在上图中,可以发现测试视频的位置离乒乓球最近,就可以判断这个视频是乒乓球比赛视频。
这个例子中非黑即白,实际的分类数据中参数是非常多的,为了提高算法可靠性,会取 k 个近邻点,这K 个点中属于哪一类的较多,就将当前待识别点分为哪一类,为了方便 k 值通常取奇数,这是为了防止两边一样的情况。
例如,两个双胞胎A 和 B ,要判断一个图形T 上的人是哪个,采用K 近邻算法实现的具体步骤:
- 收集两人的照片各100张
- 确定几个用来识别人物的特征,并使用这些特征标记两人的照片,例如根据某4个特征,每张照片可以表示为 [156,43,33,245] 这种形式(即一个样本点),通过上述方式获得A 的100张照片的数据集 FA, B 的数据集 FB。此时数据集 FA,FB 中的元素都是上述特征值的形式,每个集合各有100个这样的特征值,总之就是数值标识照片,得到各自的数值特征集 FA, FB。
- 计算图形T 的特征,用特征值表示图形T ,例如可能是 ,[111.222.333.444]
- 计算图像T 的特征值与 FA , FB 中各特征值之间的距离,
- 找出产生其中 k 个最短距离的样本的(离T 最近的 K 个邻居),统计 K 个样本点中属于 FA 和属于FB 的样本点的个数。哪个多就是哪个人。。。。
以上就是K 近邻算法的基本思想,很简单对不对。。。让计算机还要算啊算,人一眼基本就看出来了,,果然还是人类比较厉害些。。
计算
计算机的 感觉 是通过逻辑计算和数值计算实现的,所以我们要对计算机要处理的对象进行数值化处理,将其量化为具体的值以便后续处理。典型的就是取某几个固定的特征,然后将这些特征量化。例如,人脸识别中,根据人脸部器官的的形状描述以及它们之间的距离特征来获取有助于分类的特征数据,这些特征数据可能包括特征点的距离,曲率和角度等。这样就可以将人脸图像表示为类似 [1,2,3,4] 这样的数据形式了。
K 近邻算法在获取各个样本的特征值后,计算待识别样本的特征值与各个已知分类的样本特征值之间的距离,然后找出 k 个最邻近的样本,根据这些最邻近样本中占比最高的样本所属的分类,来确定识别样本的分类。
归一化
对于简单的情况,直接计算与特征值的距离(差值)即可,例如,,警察通过技术手段获知嫌疑人的身高为 180 cm,缺一根手指;受害人身高为 173cm,十指健全。此时,前来投案的甲、乙二人都宣称自己是受害人。
这时有多个参数,将这些参数构成列表(数组)进行综合判断,因此嫌疑人的特征值 (180,9)受害人(175,10)。然后可以对 甲,乙两人判断,
- 甲 身高 175,缺一根手指,特征值(175,9) 与嫌疑人特征值的距离 = (180-175) + (9-9) = 5,与受害人特征值的距离= (175-173) + (10-9) = 3,此时甲的特征值与受害人更接近,判定甲为受害人
- 同理 ,乙身高为 178 cm,十指健全,乙的特征值为(178, 10)。经过计算判定乙为嫌疑人。
当然我们知道上述过程是错误的,,因为身高,手指数量应该有不同的权重,所以计算与特征值的距离时要充分考虑不同参数之间的权重。通常我们要对参数进行处理,让所有参数具有相等的权重。
一般来说,进行归一化就行,就是使用特征值除以所有特征值中的最大值(或最大值与最小值之差),例如上例中,归一化特征 =(身高/最高身高 180,手指数量/10)
经过归一化,嫌疑人的特征值为(180/180, 9/10) = (1, 0.9),受害人的特征值为(173/180, 10/10) = (0.96, 1)
甲:甲的特征值为(175/180, 9/10)=(0.97, 0.9)。甲与嫌疑人特征值的距离= (1-0.97) + (0.9-0.9) = 0.03。甲与受害人特征值的距离= (0.97-0.96) + (1-0.9) = 0.11。同理乙,判定为受害人。
距离计算
上例中,计算距离就是单纯的相减,也亏没有出现负数。。。通常我们计算绝对值的和 = |185-170|+|75-80| = 15+5 = 20。这种用绝对值之和表示的距离称为 曼哈顿距离。。讲究
当然我们计算平方和在开平方更好,,就是我们广泛使用的欧式距离。
手写数字识别原理
以手写数字识别为例进行介绍多特征维度的情况。
- 特征值提取
将数字图像划分成很多小块,图中每个数字分为 5行 4列,共20个小块,此时每个小块由很多像素点构成,我们假设每个小块大小为 100 X 100 像素。计算每个小块内有多少黑色的像素点,不同数字图像中每个小块内黑色像素点的数量是不一样的,正是这种不同,使我们能用该数量作为特征表示每一个数字。
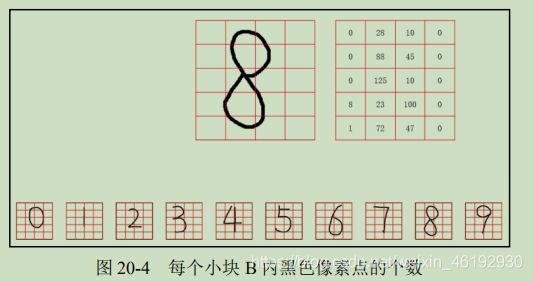
为了处理方便,将得到的特征值排成一行,写为数组形式 [ 0,28,10,0,0,88,0,45,0,125,10,0,8,23,100,0,1,72,47,0],当然python不用转成这样,可以直接处理数组嘛。。

- 数字识别
数字识别要做的就是比较待识别图像与图像集中的哪个图像最近,这里使用欧式距离最短

为了偷懒,将图像集减少到两个,将特征值简化为四个 (4个子块),然后计算距离
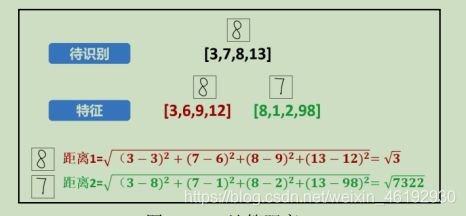
- 识别
根据计算的距离,识别为8.上面介绍的 k 近邻算法只考虑最近的一个邻居的情况。相当于 k=1 的情况。实际操作中,为了提高可靠性,需要选用大量的特征值。例如,每个数字都选用不同的形态的手写体 100个。对这10个数字,共有1000幅特征图像,识别数字时,分别计算待识别图像与这些特征图像之间的距离,这时可以将 k 调整为稍大的值,例如 k=11,然后看看其最近的11 个邻居分别属于哪些特征图像。例如,8个属于数字6 的图像,2个属于8,1个属于9,那就是6了。
自定义函数手写数字识别
opencv 中提供函数 cv2. KNearest() 实现K 近邻算法,
- 数据初始化
对程序中要用到的数据进行初始化,涉及的数据主要有路径信息,图像大小,特征值数量,用来储存所有特征值的数据等。这里共有100幅特征值,特征图像的行数,列数可以通过程序读取,这里采用 50 X 50,图片是人家的脑补链接
num=100 # 共有特征值的数量
row=50 # 特征图像的行数
col=50 # 特征图像的列数
a=np.zeros((num,row,col)) # a 用来存储所有特征的值
- 读取特征图像,十个数字每个十个特征图像,采用循环完成读取
n=0 # n 用来存储当前图像的编号。
for i in range(0,10):
for j in range(1,11):
a[n,:,:]=cv2.imread('num\\'+str(i)+'_'+str(j)+'.bmp',0)
n=n+1
- 提取特征图像的特征值
提取特征时,可以计算每个子块内黑色像素点的个数,也可以计算白色像素点的个数。这里选择白色(像素值为255)的个数。
feature=np.zeros((num,round(row/10),round(col/10))) # feature 存储所有样本的特征值
for ni in range(0,num):
for nr in range(0,row):
for nc in range(0,col):
if a[ni,nr,nc]==255: # 遍历,白色值就加1.特征值是 5 X 5 的
feature[ni,int(nr/10),int(nc/10)]+=1
f=feature #简化变量名称
- 计算待识别图像的特征值,跟上面一样
- 计算待识别图像与特征值图像之间的距离。
d=np.zeros(100)
for i in range(0,100):
d[i]=np.sum((of-f[i,:,:])*(of-f[i,:,:]))
数组d 中的索引对应各特征图像的编号。例如 d[mn] 表示待识别图像与 数字 m 的第 n 各特征图像的距离
- 获取k 个最短距离及其索引
实现方式就是,每次找出最短距离及其索引值,然后将该最小值替换为最大值,重复上述 K次,得到 k 个最短距离对应的索引。。。好像学 c 的时候讲过来。。。
d=d.tolist()
temp=[]
Inf = max(d)
#print(Inf)
k=7
for i in range(k):
temp.append(d.index(min(d))) # 注意得到的是索引,,
d[d.index(min(d))]=Inf
- 识别
根据计算出来的k 个最小值的索引,将索引值整除10就可以获得对应数字。
s='num\\' # 图像所在的路径
num=100 # 共有特征值的数量
row=50 # 特征图像的行数
col=50 # 特征图像的列数
a=np.zeros((num,row,col)) # a 用来存储所有特征的值
n=0 # n 用来存储当前图像的编号。
for i in range(0,10):
for j in range(1,11):
a[n,:,:]=cv2.imread('num\\'+str(i)+'_'+str(j)+'.bmp',0)
n=n+1
feature=np.zeros((num,round(row/10),round(col/10))) # feature 存储所有样本的特征值
for ni in range(0,num):
for nr in range(0,row):
for nc in range(0,col):
if a[ni,nr,nc]==255:
feature[ni,int(nr/10),int(nc/10)]+=1
f=feature #简化变量名称
of=cv2.imread('test3.bmp',0) # 加载测试图像
o=np.zeros((round(row/10),round(col/10)))
for nr in range(0,row):
for nc in range(0,col):
if of[nr,nc]==255:
o[int(nr/10),int(nc/10)]+=1
print(o.shape)
d=np.zeros(100)
for i in range(0,100):
d[i]=np.sqrt(np.sum((o-f[i,:,:])*(o-f[i,:,:])))
d=d.tolist()
temp=[]
Inf = max(d)
k=7
for i in range(k):
temp.append(d.index(min(d)))
d[d.index(min(d))]=Inf
temp=[int(i/10) for i in temp]
r=np.zeros(10)
for i in temp:
r[int(i)]+=1
print('当前的数字可能为:'+str(np.argmax(r)))
这个没有用到cv2. KNearest() 函数,虽然麻烦但可以很好的帮助理解过程,,不过有一说一识别的正确率是真的低。。。
K近邻模块的基本使用
我们不用编写那么麻烦的代码,只要用自带的模块函数就行。

上述两组数据中,位于左下角的一组数据,其 x、y 坐标值都在(0, 30)范围内。位于右上角的数据,其 x、y 坐标值都在(70, 100)范围内。
根据上述分析,创建两组数据,每组包含 20 对随机数(20 个随机数据点):
- rand1 = np.random.randint(0, 30, (20, 2)).astype(np.float32)
- rand2 = np.random.randint(70, 100, (20, 2)).astype(np.float32)
- 然后为两组随机数分配标签,第一组rand1,标签为0.第二组,标签为1。
- 生成一对值作为测试,test = np.random.randint(0, 100, (1, 2)).astype(np.float32)
rand1 = np.random.randint(0, 30, (20, 2)).astype(np.float32)
rand2 = np.random.randint(70, 100, (20, 2)).astype(np.float32)
# 将 rand1 和 rand2 拼接为训练数据
trainData = np.vstack((rand1, rand2))
# 数据标签,共两类:0 和 1
# r1Label 对应着 rand1 的标签,为类型 0
r1Label=np.zeros((20,1)).astype(np.float32)
# r2Label 对应着 rand2 的标签,为类型 1
r2Label=np.ones((20,1)).astype(np.float32)
tdLable = np.vstack((r1Label, r2Label))
# 使用绿色标注类型 0
g = trainData[tdLable.ravel() == 0] # 转换为一维数组
plt.scatter(g[:,0], g[:,1], 80, 'g', 'o')
# 使用蓝色标注类型 1
b = trainData[tdLable.ravel() == 1]
plt.scatter(b[:,0], b[:,1], 80, 'b', 's')
# test 为用于测试的随机数,该数在 0 到 100 之间
test = np.random.randint(0, 100, (1, 2)).astype(np.float32)
plt.scatter(test[:,0], test[:,1], 80, 'r', '*')
# 调用 OpenCV 内的 K 近邻模块,并进行训练
knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE, tdLable) # ROW_SAMPLE每个训练样本是一行样本
# 使用 K 近邻算法分类,查找邻居并预测 测试数 的响应。
ret, results, neighbours, dist = knn.findNearest(test, 5) # 5 就是 K
# 显示处理结果
print("当前随机数可以判定为类型:", results)
print("距离当前点最近的 5 个邻居是:", neighbours)
print("5 个最近邻居的距离: ", dist)
# 可以观察一下显示,对比上述输出
plt.show()

K近邻手写数字识别
num=100
row=50
col=50
a=np.zeros((num,row,col))
n=0
for i in range(0,10):
for j in range(1,11):
a[n,:,:]=cv2.imread('num\\'+str(i)+'_'+str(j)+'.bmp',0)
n=n+1
feature=np.zeros((num,round(row/5),round(col/5)))
for ni in range(0,num):
for nr in range(0,row):
for nc in range(0,col):
if a[ni,nr,nc]==255:
feature[ni,int(nr/5),int(nc/5)]+=1
f=feature
# 将 feature 处理为单行形式
train = feature[:,:].reshape(-1,round(row/5)*round(col/5)).astype(np.float32)
# 贴标签,要注意,是 range(0,100)而非 range(0,101)
trainLabels = [int(i/10) for i in range(0,100)]
trainLabels=np.asarray(trainLabels)
#print(*trainLabels) # 打印测试看看标签值
##读取图像值
o=cv2.imread('test.bmp',0) # 读取待识别图像
of=np.zeros((round(row/5),round(col/5))) # 用来存储待识别图像的特征值
for nr in range(0,row):
for nc in range(0,col):
if o[nr,nc]==255:
of[int(nr/5),int(nc/5)]+=1
test=of.reshape(-1,round(row/5)*round(col/5)).astype(np.float32)
# 调用函数识别图像
knn=cv2.ml.KNearest_create()
knn.train(train,cv2.ml.ROW_SAMPLE, trainLabels)
ret,result,neighbours,dist = knn.findNearest(test,k=15)
print("当前随机数可以判定为类型:", result)
print("距离当前点最近的邻居是:", neighbours)
print("最近邻居的距离: ", dist)
调一下k值,分块的大小,三个测试图总算成功了一个。。还是训练集太小了吧。。。Mnist数据集不会用…我的路还很长啊.