【C语言深入】深入理解程序的预处理过程
【C语言深入】深入理解程序的预处理过程
- 一、程序的编译环境与执行环境简介
- 二、程序的“翻译”过程
-
- 1、预处理
-
- 1.1、头文件的包含
- 1.2、去注释
- 1.3、替换宏
-
- 先去注释还是先替换宏呢?
- 1.3条件编译
- 2、编译
- 3、汇编
- 4、连接
- 三、C语言与定义符号的介绍和使用
-
- 1、#define定义宏
-
- 1.1、数值常量宏
- 1.2、定义表达式
-
- 怎么解决多条语句问题
- 1.3、#undef
- 1.4、宏能充当注释吗?
一、程序的编译环境与执行环境简介
我们平时所写的每一个.c文件都会经过编译和连接的过程之后才会形成一个可执行程序:
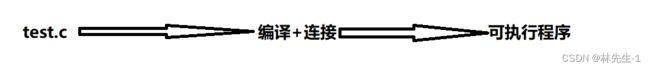
今天我们就来详细的看看编译和连接这两个过程的具体细节。
程序的翻译环境与执行环境
在ANSI C的任何一种实现中,存在两个不同的环境。
第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令。
第2种是执行环境,它用于实际执行代码。
而我们的编译和连接就是在翻译环境中完成的,当.c原文件经过翻译环境后就会形成一个.exe的可执行文件,而这个可执行文件执行所依赖的就是执行环境。

所以在翻译环境中就有这样两个工具:编译器和连接器,分别完成编译和连接的工作。
而我们的每一个.c源文件都会单独经过编译器的编译,编译之后每一个.c源文件都会对应生成一个.obj(windows平台上)的目标文件。最后由连接器把这些目标文件再加上一些链接库连接成一个可执行文件。
具体过程可如下图所示:

编译与连接的再细分
关于编译与连接其实还可以继续细分为很多个小步骤,具体细分如下图所示:

而我们今天主要讲的还是预处理的内容。
二、程序的“翻译”过程
1、预处理
1.1、头文件的包含
我们每次写C程序之前都要先用#include指令来进行一些头文件的包含,这个头文件的包含其实就是在预处理中完成的。
为了验证此过程,我们需要用到gcc编译器,因为如果是其他集成开发环境的话,这个过程是已经被封装好了的。
我这里使用的是VSCode编辑器里搭建的gcc编译器。
比如说我们现在有这样一个.c源文件:
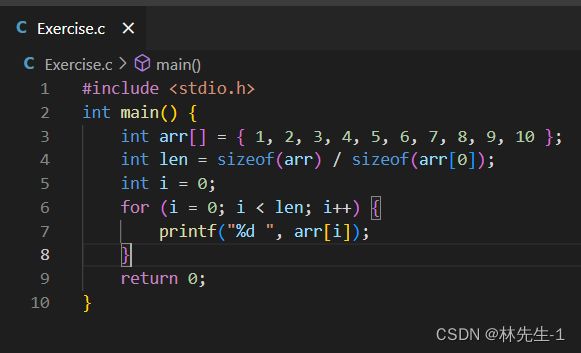
我们可以使用以下指令将预编译的结果重定向到一个文件中去:
![]()
动linux指令的朋友就会知道,-E选项表示的是在预编译完成后就停下,-o选项表示将结果保存到一个文件中。
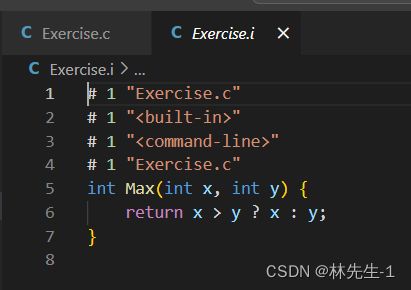
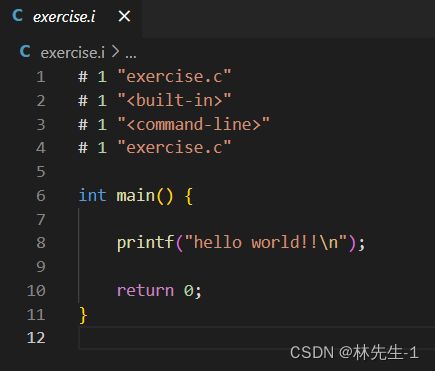
完成后我们就可以打开Exercise.i文件来看看:

打开后我们就会发现里面有一大堆我们看不懂的东西,直到800多行后我们才看见我们自己写的代码:

其实前面那800多行代码就是我们头文件的内容。
而如果我们在代码中并没有引入头文件:

那我们在重定向后的结果中就不会看到那一大堆东西了:
1.2、去注释
预处理阶段要做的第二个工作就是去注释,比如我们可以在我们的代码中写上一条注释:
我们可以看到重定向后的文件中并不会出现这句注释:
![]()

所以在平时写代码的过程中不论我们写了多少注释,其对程序都是没有任何负担的,因为预编译后它们就都全部消失了。
1.3、替换宏
预处理阶段还要做的一件事就是对宏进行替换。
也就是说平时我们用#define定义的各种符号实际上在预编译后就会被全部替换掉,从这也可以理解为什么宏是不可被调试的。
比如我们可以在我们的代码中写上这样的两个宏:

当我们执行完预编译之后就会发现.i文件中的宏就给替换掉了:
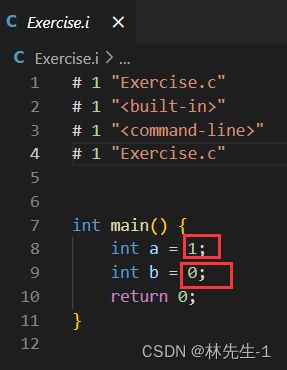
先去注释还是先替换宏呢?
那么在预编译阶段是先去注释还是先替换宏呢?
我们可以设计一下方法来验证这个问题:
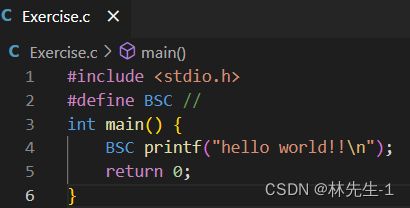
对于这个例子,如果是先替换再在去注释的话,那么预处理的结果应该是先将BSC替换成//,再去注释。那么我们在结果中就将看不到printf这条语句。
但我们的结果却并非如此:
![]()

我们会发现在我们的结果中依然能够看到printf这条语句出现。
所以这恰恰说明了在预处理阶段是先去注释,然后再进行宏替换,因为先去注释,所以BSC的内容就被去掉了,所以BSC的内容就是空。然后在替换BSC的时候,就等于替换了个空,所以我们的结果中还是可以看到printf这条语句的。
1.3条件编译
预处理阶段还需要做的一件工作就是条件编译。
在实际开发中,有时候因为应用场景的不同或平台的不同,我们需要选择性的对一些代码进行编译,对一些代码不进行编译。这时候就需要用到条件编译了。
例如:

我们来看看预编译的结果:
![]()
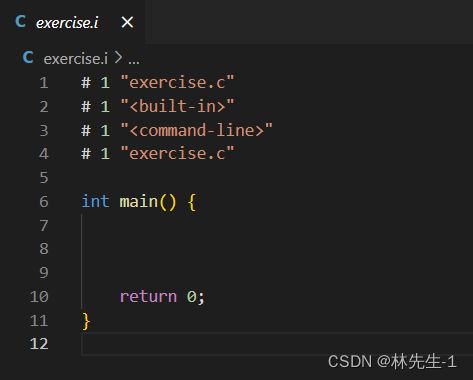
我们会发现,结果里并没有有printf这条语句。
而如果我们把_A给定义上:
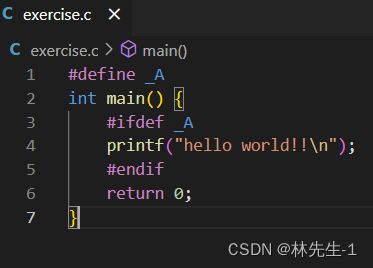
按我们在结果中就可以看到这条语句了:
关于其他的一些关于条件编译的预定义符号会在之后介绍到。
2、编译
如果我们想要观察,就需要用-S的指令,这个指令会生成一个.s的文件,里面就是编译的结果:
![]()
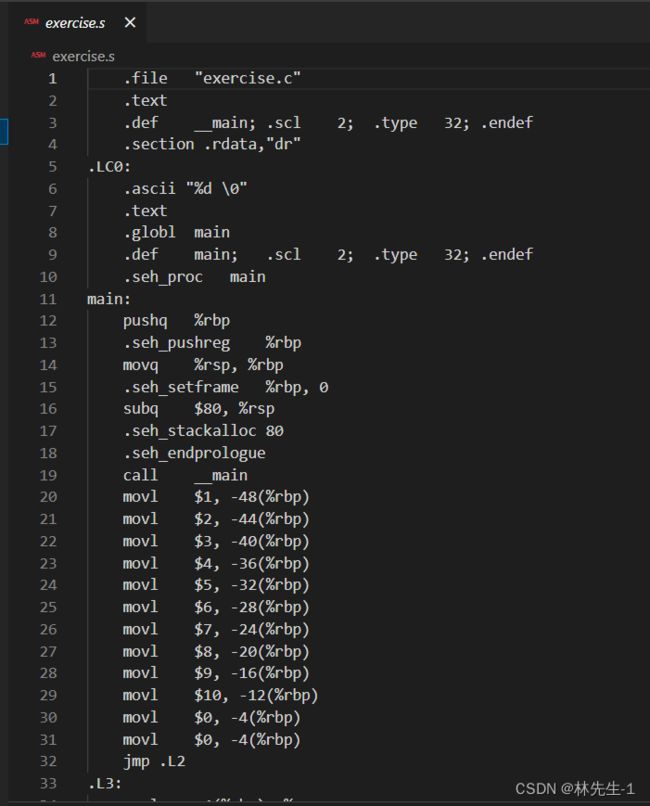
大家应该都看得出,其实.s里放的就是汇编代码。
所以,编译阶段所做的工作就是将C语言代码转化成汇编代码。
而我们上面所列出的语法分析、词法分析……就是在这个转化过程中完成的,但这并不是我们今天的重点。
3、汇编
如果我们想要观察到汇编产生的结果的话,就需要用到-c指令,该指令会生成一个.o的目标文件文件:
![]()

而这个.o文件其实是一个二进制文件,所以汇编阶段所做的工作就是将汇编代码转化成二进制文件。
最后这些.o文件就会被连接器连接起来,形成一个可执行文件。
4、连接
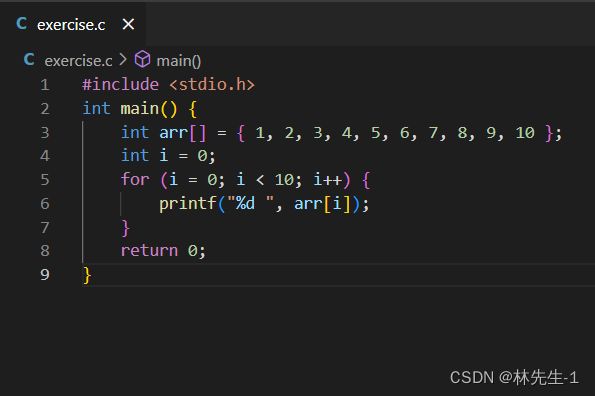
我们的最终目的就是生成可执行文件,所指令就是直接用gcc编译即可:
![]()
然后就会生成一个可执行文件a.exe:

我们可以直接运行a.exe文件:

三、C语言与定义符号的介绍和使用
1、#define定义宏
1.1、数值常量宏
我们在编写程序的时候,总会遇到一些常量会被大量的重复使用,如果某一天我们需要对这些常量进行修改,那就得修改所有的地方,太麻烦了。
所以,我们就有了数值常量宏。
我们使用#define指令来定义数值常量宏:
#define MAX 1
当我们需要使用的时候,直接将宏赋值给变量即可:
int a = MAX;
这样如果以后我们需要对使用宏的地方就行修改,就可以直接修改宏的值即可,这大大增强了我们代码的灵活性和可维护性。
1.2、定义表达式
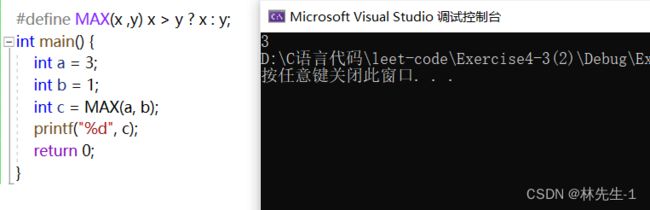
我是我们也可用#define来定义一些带参数的表达式,这些表达式宏使用起来核函数非常类似,也是可以传递参数的,例如求最大值如果用宏来解决看起来就比用函数来解决轻松得多:
#define MAX(x, y) X > y ? x : y
使用起来也可以完全像使用函数一样使用:
但宏与函数的最大不同在于红是完全替换的,而函数不是,这也导致使用宏可能会出现一个在函数中不可能出现的问题,那就是操作符的优先及问题,最典型的一个例子就是我们使用宏来定义一个求平方的表达式:
#define SQUARE(x) x * x
如果我们的参数值是一个单独的数字或者变量,那就不会出什么问题:
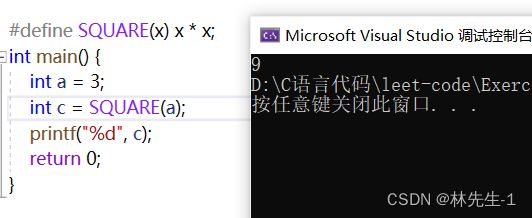
但只要参数变成了表达式,那就大有可能出问题了:
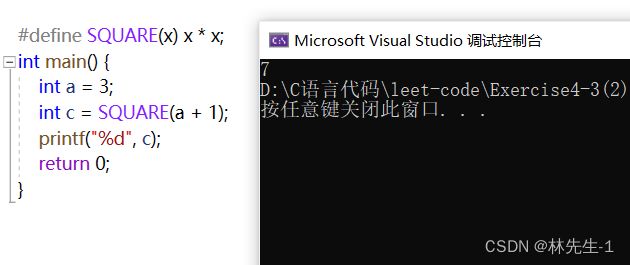
答案并不是4 * 4 = 16,这是因为宏是完全替换的,替换后就变成了a + 1 * a + 1 ,那其结果当然就是7了。
解决此问题的方法其实很简单,既然想要参数是一个整体,那就让它成为一个整体就行了,怎么办呢?
不要吝啬括号就行了:
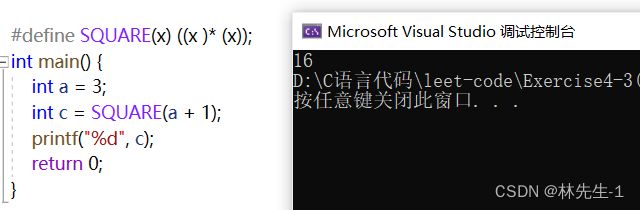
怎么解决多条语句问题
但宏定义的表达式还有一个更难解决的问题,那就是当表达式是多条语句时候。例如我现在想定义一个宏,来对两个变量进行初始化,那我们就可以这样写:
#define INIT(x, y) a = 0; \
b = 0;
这样写在大多数情况下使用是没有问题的,但有一种情况例外,那就是如下的情况:

这样写就会发现代码在编译时就已经报错了,原因想必大家也都知道,如果if和else后面不加大括号的话,那就只能执行一条语句,而宏又是完全替换的,这就相当于在if后面插入了两条语句。所以这里的报错就应该是else未能找到匹配的if:
![]()
那这个问题应该怎么解决呢?
一个最直接的方法就是在if和else语句后面都加上大括号:

但这样的解决方案并不是最好的,这是因为每个人的编码习惯是不一样的,虽然if和else语句后面添加大括号是一种很好的编码规范。但并不是每个人都能做到,特别是一些刚学编程不久的小白。
所以这种方法的通用性不高。
有人可能就会想到可以给宏本身带上大括号:

但如我们看到的一样,也报错了,究其原因也还是因为宏是完全替换的,这样子替换后那就变成了在一个大括号后面加上了分号了,而这种语法是非法的。
那人有偶要说了:那不要在INIT(x,y)后面加上分好不就得了?
哎,这不就是再跟语法相抗衡吗?我们编写程序的习惯和语法都是在每一个语句结束机上分号,要是这样干,那写出来的代码不就很奇怪了吗?
那这个问题到底该怎么解决呢?我们要如何在C语言当中写一个可容纳大块代码的宏呢?
其实这个问题适用最终解决方案的,那就是使用do{}while(0)结构。(要注意while后面一定不能加分号)
这样就可以在do后的大括号里写多条语句了:

这样我们就看不到任何报错了。
1.3、#undef
#undef就是用来取某个宏的定义的,用法很简单,如下图:

当我们对MAX定以后在取消定义,如果再使用,那就会直接报错。
1.4、宏能充当注释吗?
那么宏能充当注释吗?
我想聪明的朋友心里已经有答案了。上面就已经验证过,在预处理阶段去注释是发生在宏替换之前的,也就是说不管你想让宏的内容是"//“形式的注释或者”/**/"形式的注释,他们都在宏替换之前被清除了。所以这样定义的就都等于空白。
所以结论是,宏不能充当注释。