NeurIPS2020《Object-Centric Learning with Slot Attention》&GRU
文章目录
- 前置知识
- 正文
Code: https://github.com/google-research/google-research/tree/master/slot_attention
Slides: https://slideslive.com/38930703
前置知识
1)RNN、LSTM、GRU串讲
先从RNN讲起,RNN是一种用来处理时间序列数据的神经网络,原始RNN的每一个节点可以用以下函数来形式化。
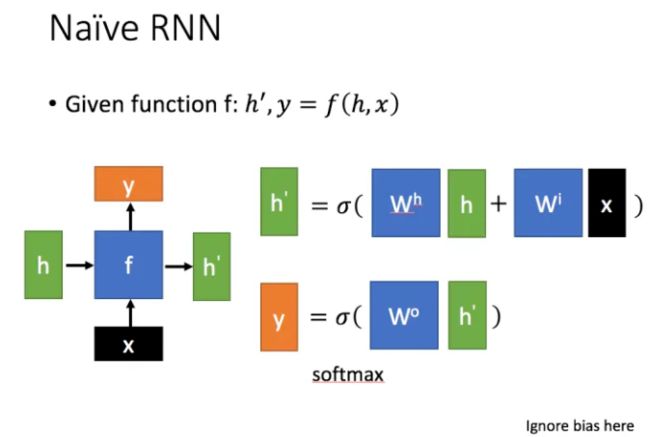
每个节点的输入有两个:上个节点的状态 h h h和当前节点的输入 x x x;产生的输出也有两个:当前节点状态 h ′ h' h′和当前节点的输出 y y y,首先输出当前节点的状态 h ′ h' h′,再根据当前节点状态 h ′ h' h′生成当前节点的输出 y y y(一般是将 h ′ h' h′通过线性层进行维度映射后,再使用softmax进行分类)。σ是sigmoid函数。也就是说当前时刻的状态 h ′ h' h′,与上个时刻状态 h h h和当前时刻的输入 x x x都有关。
当时间步较大时,RNN会出现梯度消失和梯度爆炸问题,因此在实际中,RNN较难捕捉时间序列中时间步距离较大的依赖关系。为了缓解这个问题,LSTM(Long short-term memory,长短时记忆)和GRU(Gate Recurrent Unit,门控循环单元)应运而生,它们属于门控循环神经网络,都属于RNN的一种,但相比于RNN在长序列中有更好的表现。
LSTM提出的最早,在1994年就被提出。它与RNN的区别如下,相对于相比RNN只有一个传递状态
h t h^t ht ,LSTM有两个传输状态,一个 c t c^t ct(cell state,有的也叫"记忆细胞"),和一个 h t h^t ht(hidden state)。注意:RNN中的 h t h^t ht 相等于LSTM中的 c t c^t ct)。
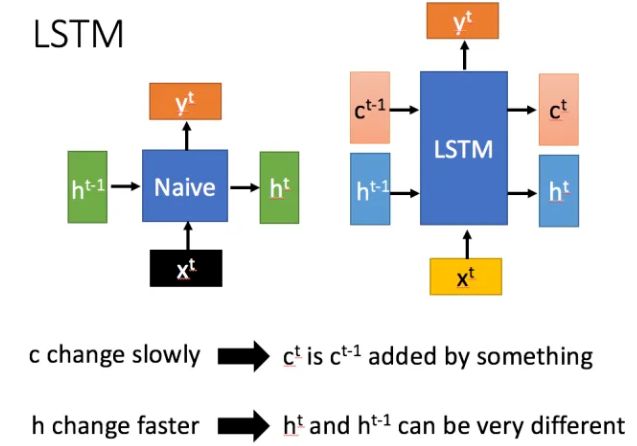
为了实现这样设计,LSTM引入了三个门:输入门 z i {z}^i zi(input gate)、遗忘门 z f {z}^f zf(forget gate)和输出门 z o {z}^o zo(output gate),以及一个候选记忆细胞 c ^ t \hat{c}^t c^t(在下图中记作z,作用是记录当前阶段的输入信息)。它们的计算如下,其中门用sigmoid函数将数据转换为0~1之间的数值来充当门控信号,候选记忆细胞使用tanh函数将输入信息放缩在-1到1之间。
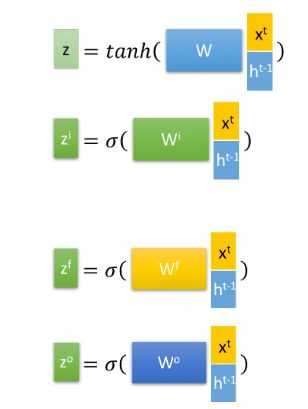
结构内部细节如图:

图中使用的是Hadamard Product,也就是操作矩阵中对应的元素相乘。对于上个阶段的状态 h t − 1 h^{t-1} ht−1和当前阶段的输入 x t x^t xt,首先计算出三个门控信号,以及一个候选记忆细胞z(或 c ^ t \hat{c}^t c^t)来记录输入信息。
- 忘记阶段: 对于上个阶段的记忆细胞 c t − 1 c^{t-1} ct−1,首先通过遗忘门 z f {z}^f zf与其相乘,进行选择性遗忘,也就是“忘记不重要的,记住重要的”。
- 选择记忆阶段: 当前阶段的输入信息被整合进了候选记忆细胞z(或 c ^ t \hat{c}^t c^t)内,我们令输入门 z i {z}^i zi与其相乘,将其中重要的信息保存下来,不重要的去除。
- 输出阶段: 有两个输出。
- 将遗忘后的上个阶段记忆细胞 c t − 1 c^{t-1} ct−1,与记忆后的当前阶段的候选记忆细胞z( c ^ t \hat{c}^t c^t)相加,就得到了当前阶段的记忆细胞 c t c^{t} ct
- 有了当前阶段的记忆细胞 c t c^{t} ct后,使用tanh对其进行缩放,再令输出门 z o {z}^o zo与其相乘,目的是对输出进行选择,就得到了用于输出的当前阶段状态 h t h^{t} ht。与RNN一样,最后同过线性层进行维度映射后,再通过非线性变换得到当前阶段的输出 y t y^{t} yt
总的来讲,LSTM就是在RNN中引入了门控机制,通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息。但是LSTM因为引入了很多内容,导致参数变多,使得难以训练。因此,GRU在2014年被提出,它在很多情况下可以取得与LSTM同样的效果,但是训练起来却更加的简单。
GRU的输入输出结构与原始RNN一模一样。它的内部结构如下。
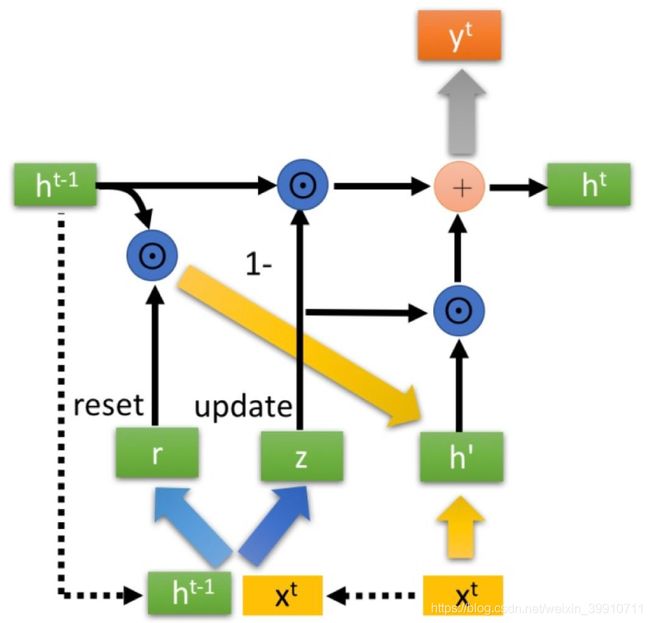
GRU引入了两个门:重置门r(reset gate)和更新门z(update gate),以及一个候选隐藏状态 h ′ h' h′的概念。 对于上个阶段的状态 h t − 1 h^{t-1} ht−1和当前阶段的输入 x t x^{t} xt,首先通过下面公式计算两个门控信号。
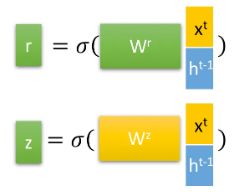
重置门r(reset gate)的作用是将上个阶段的状态 h t − 1 h^{t-1} ht−1进行重置,得到 h t − 1 ′ h^{t-1'} ht−1′。然后将重置后的 h t − 1 ′ h^{t-1'} ht−1′与当前阶段的输入 x t x^{t} xt拼接起来,再一样的通过tanh函数得到当前阶段的候选隐藏状态 h ′ h' h′,它表示当前阶段的输入信息(个人认为,GRU的候选隐藏状态 h ′ h' h′对应于LSTM中的候选记忆细胞 c ^ t \hat{c}^t c^t)。

最后,GRU的核心就是使用更新门z对状态进行更新,使用如下公式:

右边前半部分对应"遗忘阶段",对上个阶段的状态 h t − 1 h^{t-1} ht−1进行选择性遗忘,右边后半部分对应"记忆阶段",对当前阶段的输入信息 h ′ h' h′进行选择性记忆。 这里,GRU使用一个门控z就同时可以进行遗忘和选择记忆,而LSTM则要使用多个门控。
门控信号z的范围是(0,1),越接近1,代表”记忆“下来的数据越多,而越接近0则代表”遗忘“的越多。此外,可以看到,遗忘(1-z)和记忆(z)是联动的,对之前的状态信息遗忘了多少,就会对当前的输入信息记录多少,以保持一种“恒定”的状态。
参考:人人都能看懂的LSTM、人人都能看懂的GRU、动手学深度学习
正文
Slot Attention要做的事是:从 CNN 的 feature map 中聚类/抽象出 set of slots。对slot的理解是"each slot can store (and bind to) any object in the input"。

Slot Attention module的算法如下:

inputs 即图像 NxD 的 feature map,slots 是 K 个 slot 的表征,可以理解为 DETR 的 object queries,只不过这里多了个高斯先验,即slot的初始化是从高斯分布中进行采样。
Slot attention启发与K-means聚类,二者的区别如下:

slot attention 循环内的每一个步骤,与一层 transformer decoder layer 做的事情并没有太大区别。每一步都传入来自 CNN 的 feature map,以及上一次循环更新过的 slots,这个 slots 可以理解为上一层 transformer decoder 传过来的 slots/object/queries/tgt/,随便叫什么。因此,Slot Attention module 即去除 self-attention 层的,参数共享的多层 transformer decoder。
Slot-attention与Transformer decoder的一个重要区别就是“attention的归一化维度不同”:slot attention 沿 slot 维度归一化,换言之对于每个 pixel,各 slot 对其 attention 之和为 1(即所有slots 互斥的瓜分各个 pixel,这也是论文中“the slots compete for input keys”所想表达的意思);而 transformer decoder 的 cross attention 沿 inputs 维度归一化,即每个 slot 对 inputs 中各 pixel 的 attention 之和为 1,这时slot 之间是互不相关的。
Ablation中表明,GRU是一个trick,可以获得性能上的提升,但是提升的效果不是特别的明显。slot attention的一个缺点是该方法需要提前知道物体的数量,不知道近期有没有工作对此进行改进。
如果任务是set prediction,那么slot attention其实与DETR并无大的差别。DETR中每个 query 数量也是指定的,并且也是针对性的检测特定位置的物体。因此,DETR中的query其实可以看作是slot。Slot attention的作者认为DETR 直接将 slots 当做参数进行优化,可能会影响泛化性能,但其实在大规模数据集下,这样可能是有好处的。
参考:https://zhuanlan.zhihu.com/p/344979830