[论文解析]FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model
![[论文解析]FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model_第1张图片](http://img.e-com-net.com/image/info8/50b74f8dc17f4fc0b883239e8411c3ac.jpg)
Paper: https://arxiv.org/abs/2303.09833
Code:https://github.com/vvictoryuki/FreeDoM
Overview
3. Preliminaries
3.1. Score-based Diffusion Models

score function:
![]()
3.2. Conditional Score Function
rewritte conditional score function :

The first term can be estimated using the pre-trained unconditional score estimator s(,t)
The secoind term is the critical part of constructing conditional diffusion models. We can interpret the second term as a correction gradiant., pointing xt to a hyperplane in the data space, where all data are compatible with the given condition c.
3.3. Energy Diffusion Guidance
A flexible and straightforward way is resorting to the energy function [50, 21] as follows:

where λ \lambda λ denotes the positive temperature coefficient and Z>0 denotes a normalizing constant, computed as Z =
![]()
where C denotes the domain of the given conditions.
ε ( c , x t ) \varepsilon(c,x_t) ε(c,xt) is an energy function that mesures the compatibility between the condition c and the noisy image xt… its value will be smaller when xt is more compatible with c.
Therefore, the correction gradient can be implemented with the following:
![]()
which is referred to as energy guidance.
Finally, we get the conditional sampling:
![]()
![]()
The proposed FreeDoM method.
4.1. Approximate Time-Dependent Energy
Existing classifier-based methods [10, 29, 50, 23] choose time-dependent distance measuring functions Dφ(c, xt, t) to approximate the energy functions as follows:
![]()
where φ defines the pre-trained parameters. Dφ(c, xt, t)computes the distance between the given condition c and noisy intermediate results xt.
a straightforward way is to approximate Dφ(c, xt, t) using Dθ (c, x0), formulated as:

during the sampling process, it is infeasible to get the clean image x0 corresponding to an intermediate noisy result xt, so we need to approximatex0. Considering the expectation of p(x0|xt) [6]:


we can approximate the time-dependent energy function of noisy data xt:

the approximated sampling process can be written as:
![]()
![[论文解析]FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model_第2张图片](http://img.e-com-net.com/image/info8/d24d4ad9a93a4b699c16fb9420922f6a.jpg)
4.2. Efficient Time-Travel Strategy
Our experiments demonstrate that the time travel strategy is effective in solving the poor guidance problem (shown in Fig. 2(b)).
![[论文解析]FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model_第3张图片](http://img.e-com-net.com/image/info8/dad0f4946011482e8a9b767a657b889d.jpg)
Figure 2: Comparison of results generated before and after using the time-travel strategy. The prompt is “orange”. We can see that the results in (a) do not match the given conditions. After using the time-travel strategy, we get better results in (b).
In Fig. 3, we try to analyze this phenomenon by dividing the sampling process into three stages.
![[论文解析]FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model_第4张图片](http://img.e-com-net.com/image/info8/6decc332fc1d4ea1ad6f688bdd40a469.jpg)
Figure 3: Demonstration of the importance of different sampling stages. Most of the semantic content is generated during the semantic stage, so we only employ the time-travel strategy in this stage to achieve an efficient version of FreeDoM. The shown images are x0|t generated by diffusion models pre-trained on the ImageNet data domain.
![[论文解析]FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model_第5张图片](http://img.e-com-net.com/image/info8/d2249ac976a34474b86d1585b5e0d0ad.jpg)
4.3. Construction of the Energy Function
Single Condition Guidance.
To incorporate in specific applications, we use the distance measuring function conforming to the following structure to construct the energy function:
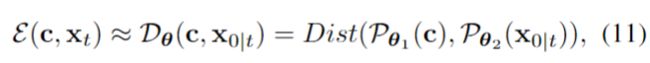
Multi Condition Guidance
In these multicondition cases, assume that the given conditions are denoted as {c1, · · · , cn}, we can approximately construct the energy function as :
![[论文解析]FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model_第6张图片](http://img.e-com-net.com/image/info8/b38f9088c1ef45ad996df1841e6547b7.jpg)
Guidance for Latent Diffusion.
In this case, the intermediate resultsxt are latent codes rather than images. We can use the latent decoder to project the generated latent codes to images and then use the same algorithm in the image domain.
4.4. Specific Examples of Supported Conditions
![[论文解析]FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model_第7张图片](http://img.e-com-net.com/image/info8/2ea1fc70a2dc43c187ee4d2f76ddc7b3.jpg)
Figure 4: Practical usage of face parsing maps. We can limit the gradient of the energy function to update the image only in the target semantic region indicated by the mask so that other regions remain unchanged while editing.
5. Experiments
5.2. Qualitative Results
Single Condition.
![[论文解析]FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model_第8张图片](http://img.e-com-net.com/image/info8/6dbac4ab9f7142f68518512d96e399a0.jpg)
Figure 5: Qualitative results of using a single condition for human face images. The included conditions are: (a) text; (b) face parsing maps; © sketches; (d) face landmarks; (e) IDs of reference images. Zoom in for best view.
![[论文解析]FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model_第9张图片](http://img.e-com-net.com/image/info8/3678b321de724d318af07fe16a95c010.jpg)
Figure 6: Qualitative results of using a single condition for ImageNet images. Pre-trained diffusion models are: (a) unconditional ImageNet diffusion model; (b) classifierbased ImageNet diffusion model.
Multiple Conditions.
![[论文解析]FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model_第10张图片](http://img.e-com-net.com/image/info8/a84035c10cdf4fdc84f6fbe0401981d3.jpg)
Figure 7: Qualitative results of using multiple conditions.Pre-trained models are: (a) and (b): unconditional human face diffusion model; © and (d): unconditional ImageNet diffusion model.
Training-free Guidance for Latent Domain.
![[论文解析]FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model_第11张图片](http://img.e-com-net.com/image/info8/970470f967f348c8b136257cf1b86927.jpg)
Part (d)-(f) show that training-free guidance can work with other training-required conditional diffusion models, like Stable Diffusion [33] and ControlNet [49], to achieve a more sophisticated control mechanism. The conditions of scribbles in (d), human poses in (e), and prompt texts in (f) are controlled by the training-required interfaces provided by ControlNet and Stable Diffusion. Training-free energy functions control the conditions of face IDs from the reference images in (e) and style images in (d) and (f)
5.3. Further Studies
![[论文解析]FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model_第12张图片](http://img.e-com-net.com/image/info8/efc5f1ed5bb44249abff382395dfb5aa.jpg)
Figure 8: Comparison between FreeDoM and TediGAN [46] in three conditional image synthesis tasks: (a) segmentation maps to human faces; (b) sketches to human faces; © text prompts to human faces. Zoom in for best view.
![[论文解析]FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model_第13张图片](http://img.e-com-net.com/image/info8/26e7a94b9d21422d973df1bd02bddb33.jpg)
Table 1: We compare FreeDoM with the training-required method TediGAN [46] in three image conditional synthesis tasks. We compute the distance with given conditions and FID to judge the performance. The comparison shows that FreeDoM generates images matching given conditions better and having a comparable or better image quality.
![[论文解析]FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model_第14张图片](http://img.e-com-net.com/image/info8/97b160437c6e458a94c9285ff83854b5.jpg)
Figure 9: Comparison between FreeDoM and UGD [2] in style-guided generation. The UGD results are taken from the original paper. The number in the lower right corner of each image represents its distance with the provided style image (smaller is better), which is calculated using the method described in Sec. 4.4. FreeDoM offers obvious advantages in image quality and in the degree of statisfaction of the conditions.
![[论文解析]FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model_第15张图片](http://img.e-com-net.com/image/info8/2ef0e727fa6644b99865f24c60051b66.jpg)
Figure 10: Demonstration of the effect of different learning rates from small scale to large scale. (a): unconditional ImageNet diffusion models with prompt “orange”; (b): unconditional human face diffusion models with a face ID from the reference image.
6. Conclusions & Limitations
We propose a training-free energy-guided conditional diffusion model, FreeDoM, to address a wide range of conditional generation tasks without training. Our method uses off-the-shelf pre-trained time-independent networks to approximate the time-dependent energy functions. Then, we use the gradient of the approximated energy to guide the generation process. Our method supports different diffusion models, including image and latent diffusion models.
In future work, we aim to explore even more energy functions for a broader range of tasks.
Despite its merits, our FreeDoM method has some limitations:
- The time cost of the sampling is still higher than the training-required methods because each iteration adds a derivative operation for the energy function, and the timetravel strategy introduces more sampling steps.
- It is difficult to use the energy function to control the fine-grained structure features in the large data domain.
- Eq. 12 deals with multi-condition control and assumes that the provided conditions are independent, which is not necessarily true in practice. When conditions conflict with each other, FreeDoM may produce subpar generation results.