自动化测试学习(四)-selenium的安装和8种定位方法

目录
一、环境准备
1.浏览器下载
2.浏览器驱动下载
3.下载selenium
二、Selenium定位元素的8种方法(以百度首页为例)
1.id定位
2.name定位
3.class name定位
4.tag name定位
5.link text定位
6.partial link text定位
7.xpath定位
8.css selector定位
一、环境准备
1.浏览器下载
Selenium支持多平台(windows、linux、MAC)、多浏览器(ie、firefox、chrome)、多语言(Java、Python、C#),缺点是必须依赖第三方浏览器,所以首先需要下载浏览器,这里推荐Google,兼容性比较好。
Chrome浏览器下载地址:Google Chrome 网络浏览器
2.浏览器驱动下载
Selenium是通过后台驱动的方式来驱动浏览器,所以要下载浏览器驱动
2.1 查看浏览器版本:点击右上角三个点–>帮助–>关于Google Chrome 2.2 驱动下载地址:http://chromedriver.storage.googleapis.com/index.html,找到对应的版本点击下载,下载之后为压缩包,进行解压即可。
2.2 驱动下载地址:http://chromedriver.storage.googleapis.com/index.html,找到对应的版本点击下载,下载之后为压缩包,进行解压即可。

2.3 驱动配置
- 将驱动解压放在python的安装目录下
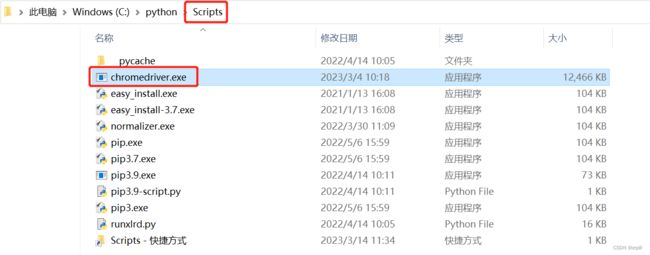
- 测试是否配置成功
在cmd输入chromedriver --version,如果显示浏览器驱动的版本信息则驱动配置成功![]()
3.下载selenium
- 在cmd输入pip install selenium
-
测试是否安装成功,使用以下脚本
from selenium import webdriver
import time as t
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("https://www.baidu.com/")
t.sleep(3)
driver.quit()
二、Selenium定位元素的8种方法(以百度首页为例)
1.id定位
查看方法:①在浏览器直接按F12,选择Elements ②鼠标右键-->检查
属性是唯一的
find_element(By.ID, 'kw')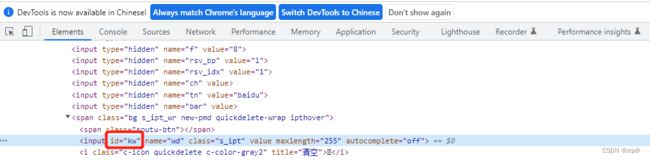
2.name定位
不是唯一的,如果存在多个相同属性,默认定位到第一个
find_element(By.NAME,'wd')
3.class name定位
不是唯一的,如果存在多个相同属性,默认定位到第一个
find_element(By.CLASS_NAME, 's_ipt')
4.tag name定位
标签不是唯一的,如果存在多个相同属性,默认定位到第一个(不建议使用)
find_element(By.TAG_NAME, 'input')
5.link text定位
文字完全匹配, 常用于a标签
find_element(By.LINK_TEXT,'新闻')
6.partial link text定位
文字部分匹配,适用于文字比较长的场景,方法同link text
find_element(By.PARTIAL_LINK_TEXT,'闻')7.xpath定位
可以通过id,neme,class等元素定位

鼠标放在该行右键-->Copy-->Copy XPath,即可复制xpath
①xpath通过id定位://*[@id="kw"]
find_element(By.XPATH,'//*[@id="kw"]')②xpath通过name定位://*[@name="wd"]
find_element(By.XPATH,'//*[@name="wd"]')③xpath通过class定位://*[@class="s_ipt"]
find_element(By.XPATH,'//*[@class="s_ipt"]')8.css selector定位
css是一种语言,定位方式比Xpath更快,功能比较强大,后面单独写一篇。
鼠标放在该行右键-->Copy-->Copy selector,即可复制selector
三种常规方式:
①若用id定位,则用 #:#kw
find_element(By.CSS_SELECTOR,'#kw')②若用class定位,则用 . :.s_ipt
find_element(By.CSS_SELECTOR,'.s_ipt')③用标签定位:input,若有多个相同属性,可用层级关系,用>表示
find_element(By.CSS_SELECTOR,'span>input')一边学习,一边总结,如有问题,欢迎大家指正!
下一篇:自动化测试学习(五)-selenium的基本操作