ShuffleNet V2 迁移学习对花数据集训练
目录
1. shufflenet v2 介绍
2. 四条轻量化网络的基本准则
2.1 输入输出通道个数相同的时候,内存访问量MAC最小
2.2 分组卷积的分组数过大会增加MAC
2.3 碎片化操作会并行加速并不友好
2.4 element-wise 操作带来的内存和耗时不可以忽略
2.5 轻量化网络特点总结
3. shufflenet v2 网络
4. train 过程
5. utils 函数
6. 预测
7. 用命令行进行训练
shufflenetv1、v2的下载:shufflenet V1和V2 基于花数据集的分类
1. shufflenet v2 介绍
shufflenet v2 论文中提出衡量轻量级网络的性能不能仅仅依靠FLOPs计算量,还应该多方面的考虑,例如MAC(memory access cost),还应该比较在不同的硬件设备下的性能等等

因此,基于多方面的考虑。shufflenet v2 通过大量的实验和测试总结了轻量化网络的四个准则,然后根据这四条准则搭建了shufflenet v2网络

- 输入输出通道个数相同的时候,内存访问量MAC最小
- 分组卷积的分组数过大会增加MAC
- 碎片化操作会并行加速并不友好
- element-wise 操作带来的内存和耗时不可以忽略
2. 四条轻量化网络的基本准则
2.1 输入输出通道个数相同的时候,内存访问量MAC最小
计算FLOPs和MAC可以参考这个:聊聊神经网络结构以及计算量和内存使用
如下,这里的卷积都是1*1卷积,因为1*1卷积占了大部分运算,并且BN层的存在,这里没有了bias。并且这里是same卷积,因此输出的size = 输入的size
所以这里的FLOPs = hwc1*1*1*c2 =hwc1c2= B(这里用B表示),
同样,MAC = hw*c1(输入特征图) + 1*1*c1*c2(1*1权重)+hw*c2(输出特征图) = hw(c1+c2)+c1c2
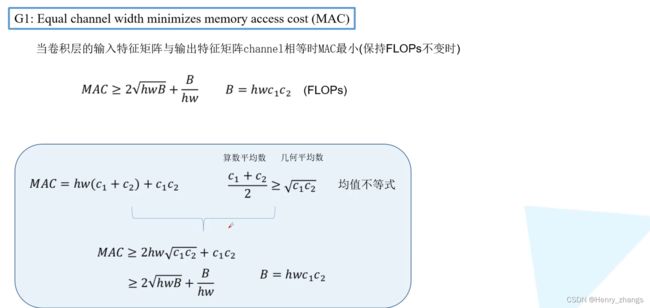
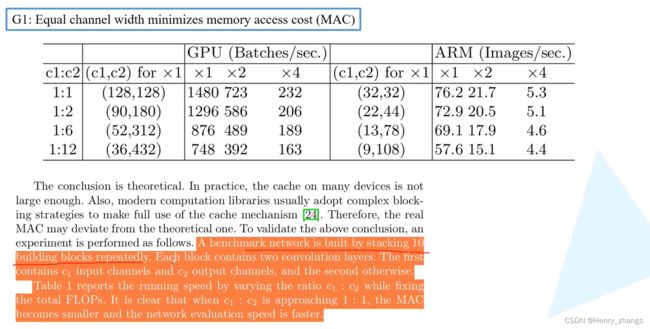
通过test,可以证明结论的正确性
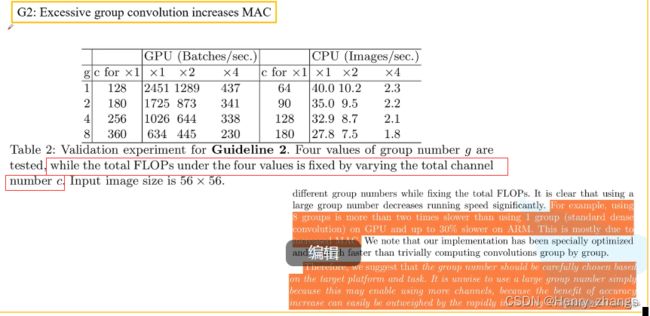
2.2 分组卷积的分组数过大会增加MAC
如下,计算公式和2.1 一样。因此这里的分组数(g)越大,MAC消耗的内存越大
注:这里虽然B也和g有关系,但是这里是控制变量的思想。因为分组卷积的分组越大,那么所需要的参数就会越小(num = kernel_size * c1 *c2 / g),所以FLOPs会变小,那么为了保证FLIOPs在同一基准上,这里要增加c2,也就是卷积核的个数,这样就能保证MAC只和g有关
分组卷积的好处就是g可以减少网络的参数,这里一开始轻量化网络减少参数的目的。那么g的变大,可以让参数越来越少,那么为了不让网络进入欠拟合,所以需要增加卷积核的个数,这样提取到的特征图会增多,让网络的性能变得更好。
然后假如g == input channel 的话,就变成mobilenet v1里面dw卷积了,反而进入了mobilenet v1的缺陷当中,所以g不能太大,也不能太小

如图,通过改变channel个数保证相同的FLOPs
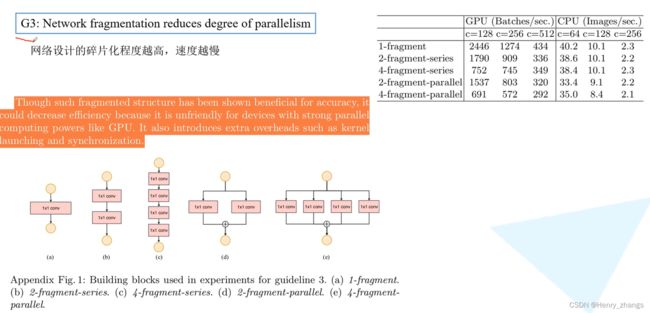
2.3 碎片化操作会并行加速并不友好
如下,所以串行的网络比并行的速度要快
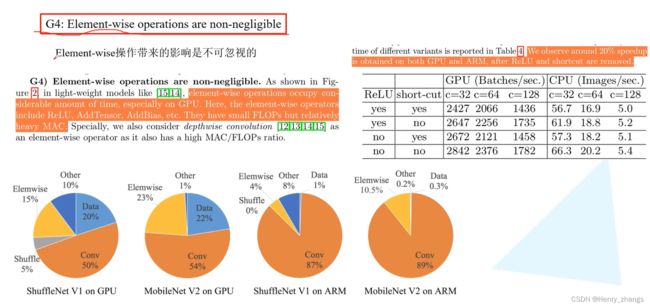
2.4 element-wise 操作带来的内存和耗时不可以忽略
所以ReLU这样element-wise的操作要尽量减少
2.5 轻量化网络特点总结

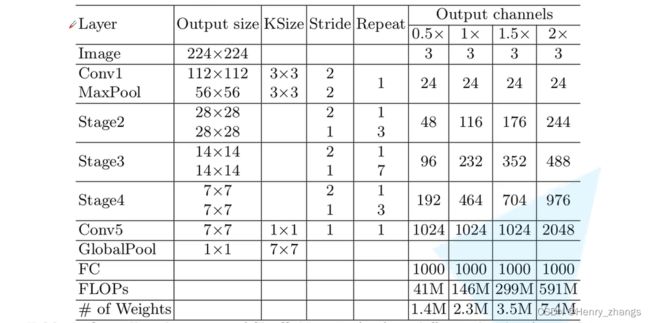
3. shufflenet v2 网络
shufflenet v2 网络的结构如下
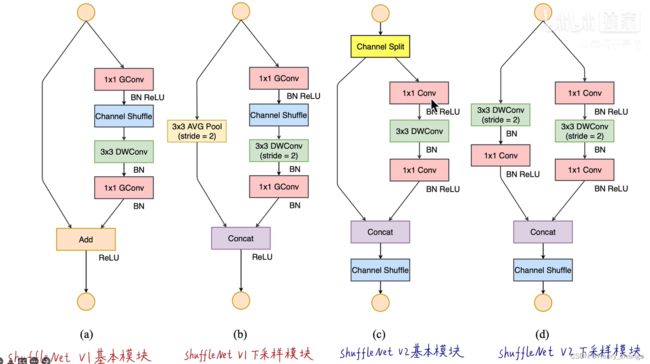
如下是shufflenet v1 和shufflenet v2的bottleneck
值得注意的是,shufflenet v2采用了channel split的方法,在stride =1的时候,进行channel split(这里是等半分)。然后一半从左边直接连下来,一半进行右边连下来。所以最近的操作是concat,这样,channel split和concat的channel是相同的
如果stride =2的话,就不用channel split了。两边都采用stride = 2进行size减半,然后channel也减半。这样最后再concat的话,也能保证channel是相同的
完整网络代码:
from typing import List, Callable
import torch
from torch import Tensor
import torch.nn as nn
# 通道重排
def channel_shuffle(x: Tensor, groups: int) -> Tensor:
batch_size, num_channels, height, width = x.size() # 分离通道信息
channels_per_group = num_channels // groups # 划分组
x = x.view(batch_size, groups, channels_per_group, height, width) # 变为矩阵的形式
x = torch.transpose(x, 1, 2).contiguous() # 矩阵转置
x = x.view(batch_size, -1, height, width) # 还原shuffle后通道信息,flatten
return x
# bottleneck
class InvertedResidual(nn.Module):
def __init__(self, input_c: int, output_c: int, stride: int):
super(InvertedResidual, self).__init__()
if stride not in [1, 2]: # stride 只能为1或者2
raise ValueError("illegal stride value.")
self.stride = stride
assert output_c % 2 == 0 # channel split,这里是对半分
branch_features = output_c // 2
# 当stride为1时,input_channel应该是branch_features的两倍
# python中 '<<' 是位运算,可理解为计算×2的快速方法
assert (self.stride != 1) or (input_c == branch_features << 1)
if self.stride == 2: # 下采样模块,左边branch
self.branch1 = nn.Sequential(
self.depthwise_conv(input_c, input_c, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(input_c),
nn.Conv2d(input_c, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features), # 维度要降一半,为了和右边concat
nn.ReLU(inplace=True)
)
else: # 正常模块,左边channel split直接过去
self.branch1 = nn.Sequential()
self.branch2 = nn.Sequential( # 无论哪个模块,右边的branch是类似的
nn.Conv2d(input_c if self.stride > 1 else branch_features, branch_features, kernel_size=1,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
@staticmethod # depthwise 卷积,不是组卷积!!,MobileNet V1深度可分离卷积的dw卷积
def depthwise_conv(input_c: int,
output_c: int,
kernel_s: int,
stride: int = 1,
padding: int = 0,
bias: bool = False) -> nn.Conv2d:
return nn.Conv2d(in_channels=input_c, out_channels=output_c, kernel_size=kernel_s,
stride=stride, padding=padding, bias=bias, groups=input_c)
def forward(self, x: Tensor) -> Tensor:
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1) # channel split
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
# shufflenet v2
class ShuffleNetV2(nn.Module):
def __init__(self,
stages_repeats: List[int],
stages_out_channels: List[int],
num_classes: int = 1000,
inverted_residual: Callable[..., nn.Module] = InvertedResidual):
super(ShuffleNetV2, self).__init__()
if len(stages_repeats) != 3:
raise ValueError("expected stages_repeats as list of 3 positive ints")
if len(stages_out_channels) != 5:
raise ValueError("expected stages_out_channels as list of 5 positive ints")
self._stage_out_channels = stages_out_channels
input_channels = 3 # 图像维度是3
output_channels = self._stage_out_channels[0]
self.conv1 = nn.Sequential( # 最初的Conv1
nn.Conv2d(input_channels, output_channels, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
input_channels = output_channels
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # MaxPool
self.stage2: nn.Sequential
self.stage3: nn.Sequential
self.stage4: nn.Sequential
stage_names = ["stage{}".format(i) for i in [2, 3, 4]]
for name, repeats, output_channels in zip(stage_names, stages_repeats,
self._stage_out_channels[1:]):
seq = [inverted_residual(input_channels, output_channels, 2)]
for i in range(repeats - 1):
seq.append(inverted_residual(output_channels, output_channels, 1))
setattr(self, name, nn.Sequential(*seq))
input_channels = output_channels
output_channels = self._stage_out_channels[-1]
self.conv5 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
self.fc = nn.Linear(output_channels, num_classes)
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.conv5(x)
x = x.mean([2, 3]) # global pool
x = self.fc(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
# 定义不同的shuffleNet网络,x1_0 是宽度因子 α 扩大1倍
def shufflenet_v2_x0_5(num_classes=1000):
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 48, 96, 192, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_0(num_classes=1000):
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 116, 232, 464, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_5(num_classes=1000):
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 176, 352, 704, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x2_0(num_classes=1000):
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 244, 488, 976, 2048],
num_classes=num_classes)
return model
4. train 过程
训练过程做了更改
import os
import math
import argparse
import torch
import torch.optim as optim # 优化器
from torchvision import transforms # 预处理
import torch.optim.lr_scheduler as lr_scheduler # 自适应学习率
from model import shufflenet_v2_x1_0
from torchvision.datasets import ImageFolder # 数据加载
from torch.utils.data import DataLoader # 数据载入
from utils import get_dataset_path, train_one_epoch, evaluate
# from torchvision.models import shufflenet_v2_x1_0 # 查看预训练权重
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
train_images_path,test_images_path=get_dataset_path(args.data_path) # 获取训练集+测试集
# 预处理
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"test": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 数据集
train_dataset = ImageFolder(root=train_images_path,transform=data_transform['train'])
val_dataset = ImageFolder(root=test_images_path,transform=data_transform['test'])
# 数据的个数
num_train = len(train_dataset)
num_val = len(val_dataset)
# 获取数据集
train_loader = DataLoader(train_dataset,batch_size=args.batch_size,shuffle=True,num_workers=2)
val_loader = DataLoader(val_dataset,batch_size=args.batch_size,shuffle=False,num_workers=4)
# 加载模型
model = shufflenet_v2_x1_0(num_classes=args.num_classes).to(device)
# 加载预训练权重
if args.weights != "":
if os.path.exists(args.weights):
weights_dict = torch.load(args.weights, map_location=device)
load_weights_dict = {k: v for k, v in weights_dict.items()
if model.state_dict()[k].numel() == v.numel()}
missing_keys, unexpected_keys = model.load_state_dict(load_weights_dict, strict=False) # 载入除了最后一层
else:
raise FileNotFoundError("not found weights file: {}".format(args.weights))
# 是否冻结权重
if args.freeze_layers:
for name, para in model.named_parameters():
if "fc" not in name: # 冻结除了fc层的参数
para.requires_grad=False
param = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.SGD(param, lr=args.lr, momentum=0.9, weight_decay=4E-5)
# 自动梯度更新
lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
# 训练
best_acc = 0.0
for epoch in range(args.epochs):
# train
loss_all = train_one_epoch(model=model, optimizer=optimizer, data_loader=train_loader, device=device, epoch=epoch, batch=args.batch_size)
scheduler.step() # 自适应学习率下降
# test
acc_all = evaluate(model=model, data_loader=val_loader, device=device)
print("[epoch :%d],train loss:%.4f ,test accuracy: %.4f" % (epoch, loss_all / num_train, acc_all / num_val))
if acc_all > best_acc: # 保留最后的权重
best_acc = acc_all
torch.save(model.state_dict(),'./shuffleNet_V2.pth')
if __name__ == '__main__':
# 可以用命令行设定参数
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=5,help='classifier number')
parser.add_argument('--epochs', type=int, default=10,help='train epochs')
parser.add_argument('--batch-size', type=int, default=16,help='batch size')
parser.add_argument('--lr', type=float, default=0.01,)
parser.add_argument('--lrf', type=float, default=0.1)
parser.add_argument('--data-path', type=str,default="./flower_data") # 数据集路径
parser.add_argument('--weights', type=str, default='./shufflenetv2_x1-5666bf0f80.pth',help='initial weights path') #预训练权重
parser.add_argument('--freeze-layers', type=bool, default=True) # 冻结参数
parser.add_argument('--device', default='cuda')
opt = parser.parse_args()
'''
opt :
Namespace(num_classes=5, epochs=10, batch_size=16, lr=0.01, lrf=0.1,
data_path='./flower_data', weights='./shufflenetv2_x1-5666bf0f80.pth',
freeze_layers=True, device='cuda')
'''
print('start training.....')
main(opt) # 运行主函数
print('finish training!!!')
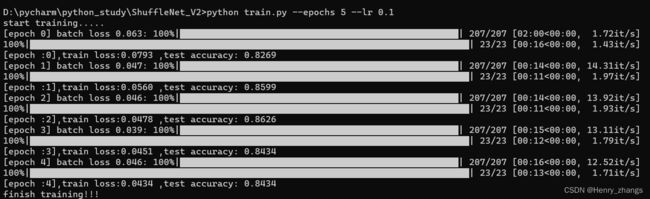
这里的argparse,就是用来可以用命令行运行的,-- 是为了保证可以乱序输入

训练过程如下:
start training.....
[epoch 0] batch loss 0.093: 100%|██████████| 207/207 [01:21<00:00, 2.54it/s]
100%|██████████| 23/23 [00:15<00:00, 1.49it/s]
[epoch :0],train loss:0.0975 ,test accuracy: 0.5082
[epoch 1] batch loss 0.089: 100%|██████████| 207/207 [00:23<00:00, 8.97it/s]
100%|██████████| 23/23 [00:13<00:00, 1.69it/s]
[epoch :1],train loss:0.0914 ,test accuracy: 0.6264
[epoch 2] batch loss 0.08: 100%|██████████| 207/207 [00:15<00:00, 13.00it/s]
100%|██████████| 23/23 [00:11<00:00, 2.06it/s]
[epoch :2],train loss:0.0861 ,test accuracy: 0.6703
[epoch 3] batch loss 0.081: 100%|██████████| 207/207 [00:15<00:00, 13.61it/s]
100%|██████████| 23/23 [00:12<00:00, 1.91it/s]
[epoch :3],train loss:0.0820 ,test accuracy: 0.7500
[epoch 4] batch loss 0.079: 100%|██████████| 207/207 [00:15<00:00, 13.45it/s]
100%|██████████| 23/23 [00:13<00:00, 1.77it/s]
[epoch :4],train loss:0.0788 ,test accuracy: 0.7390
[epoch 5] batch loss 0.079: 100%|██████████| 207/207 [00:16<00:00, 12.42it/s]
100%|██████████| 23/23 [00:12<00:00, 1.81it/s]
[epoch :5],train loss:0.0763 ,test accuracy: 0.7582
[epoch 6] batch loss 0.076: 100%|██████████| 207/207 [00:17<00:00, 12.07it/s]
100%|██████████| 23/23 [00:12<00:00, 1.78it/s]
[epoch :6],train loss:0.0748 ,test accuracy: 0.7830
[epoch 7] batch loss 0.072: 100%|██████████| 207/207 [00:19<00:00, 10.39it/s]
100%|██████████| 23/23 [00:13<00:00, 1.66it/s]
[epoch :7],train loss:0.0735 ,test accuracy: 0.7857
[epoch 8] batch loss 0.073: 100%|██████████| 207/207 [00:17<00:00, 11.84it/s]
100%|██████████| 23/23 [00:13<00:00, 1.71it/s]
[epoch :8],train loss:0.0726 ,test accuracy: 0.8077
[epoch 9] batch loss 0.074: 100%|██████████| 207/207 [00:22<00:00, 9.36it/s]
100%|██████████| 23/23 [00:14<00:00, 1.56it/s]
[epoch :9],train loss:0.0723 ,test accuracy: 0.7940
finish training!!!
5. utils 函数
一些工具函数:
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
import sys
import json
import numpy as np
import torch
from tqdm import tqdm
import matplotlib.pyplot as plt
# 返回数据集的目录
def get_dataset_path(root: str):
train_images_path = os.path.join(root,'train') # 训练集
val_images_path = os.path.join(root,'test') # 测试集
return train_images_path, val_images_path
# 绘制图像
def plot_data_loader_image(data_loader,net,device):
model = net.to(device)
imgs,labels = next(iter(data_loader)) # 获取一批数据
imgs = imgs.to(device)
json_path = './class_indices.json' # 加载 label
assert os.path.exists(json_path), json_path + " does not exist."
json_file = open(json_path, 'r')
classes = json.load(json_file)
with torch.no_grad():
model.eval()
prediction = model(imgs) # 预测
prediction = torch.max(prediction, dim=1)[1]
prediction = prediction.data.cpu().numpy()
plt.figure(figsize=(12, 8))
for i, (img, label) in enumerate(zip(imgs, labels)):
x = np.transpose(img.data.cpu().numpy(), (1, 2, 0)) # 图像
x[:, :, 0] = x[:, :, 0] * 0.229 + 0.485 # 去 normalization
x[:, :, 1] = x[:, :, 1] * 0.224 + 0.456 # 去 normalization
x[:, :, 2] = x[:, :, 2] * 0.225 + 0.406 # 去 normalization
y = label.numpy().item() # label
plt.subplot(3, 4, i + 1)
plt.axis(False)
plt.imshow(x)
plt.title('R:{},P:{}'.format(classes[str(y)], classes[str(prediction[i])]))
plt.show()
# 一个epoch的训练,返回训练样本的总损失
def train_one_epoch(model, optimizer, data_loader, device, epoch,batch):
model.train()
loss_function = torch.nn.CrossEntropyLoss() # 损失函数
running_loss = 0 # 保存一个epoch的总损失
loop = tqdm(data_loader, file=sys.stdout)
for images, labels in loop:
images,labels = images.to(device),labels.to(device)
optimizer.zero_grad() # 梯度清零
pred = model(images) # 前向传播
loss = loss_function(pred, labels) # 计算损失
loss.backward() # 反向传播
running_loss += loss.item() # 损失求和
optimizer.step() # 梯度更新
loop.desc = "[epoch {}] batch loss {}".format(epoch, round(loss.item()/batch, 3)) # 显示每个batch的损失,没有mean
return running_loss # 返回一个batch的总损失
# 计算正确率,返回测试集上预测正确的个数
def evaluate(model, data_loader, device):
model.eval()
sum_num = 0 # 用于存储预测正确的样本个数
loop = tqdm(data_loader, file=sys.stdout)
with torch.no_grad():
for images, labels in loop:
images,labels = images.to(device),labels.to(device)
pred = model(images) # forward
pred = torch.max(pred, dim=1)[1] # 计算预测结果
sum_num += torch.eq(pred, labels).sum() # 计算正确个数的总和
return sum_num # 返回整个test集上正确的个数
6. 预测
import torch
from torchvision import transforms
from model import shufflenet_v2_x1_0
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
from utils import plot_data_loader_image
# 预处理
transformer = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# 加载模型
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
model = shufflenet_v2_x1_0(num_classes=5)
model.load_state_dict(torch.load('./shuffleNet_V2.pth'))
# 加载数据
testSet = ImageFolder(root='./flower_data/test',transform=transformer)
testLoader = DataLoader(testSet, batch_size=12, shuffle=True)
# 可视化结果
plot_data_loader_image(data_loader=testLoader,net=model,device=DEVICE)
结果:
7. 用命令行进行训练
首先需要进行train.py的路径下
定义的help为成为解释参数显示

更改参数并进行训练