(iTPN) Integrally Pre-Trained Transformer Pyramid Networks论文解读
Integrally Pre-Trained Transformer Pyramid Networks论文地址: https://arxiv.org/pdf/2211.12735.pdf,代码地址: https://github.com/sunsmarterjie/iTPN
本文的突出贡献为提出了将一起预训练(Integrally Pre-Train)的backbone和neck迁移至下游任务的方法和mask feature modeling。
一、概述
当前自监督工作的问题:当前自监督学习的问题为上下游任务的差距(gap)导致的迁移困难。由于当前的工作仅迁移预训练得到的backbone(如下图所示),这导致了backbone不能良好地生成多尺度的特征图,下游任务neck需要从随机初始化的数值开始训练,可能导致neck训练较慢,且无法良好地处理backbone得到的特征。

本文的创新点
针对上述问题,在辅助任务(proxy task)中使用neck,并将一起预训练的backbone和neck迁移至下游任务,下游任务中只有head的参数需从随机初始化开始训练,如下图所示。

为了更好地训练特征金字塔(本文以特征金字塔作为neck),提出了MFM(masked feature modeling),从而提高了预训练的重建能力和下游任务的识别准确率。
本文使用知识蒸馏的教师模型获得每一层backbone所对应的特征图(feature map)。
通过moving-averaged backbone训练未经处理的原始图片,可获得每一层backbone所对应的特征图(feature map),即intermediate target。
也可以通过使用已经过预训练的backbone:CLIPhttps://arxiv.org/abs/2103.00020间接获得intermediate target。
成绩
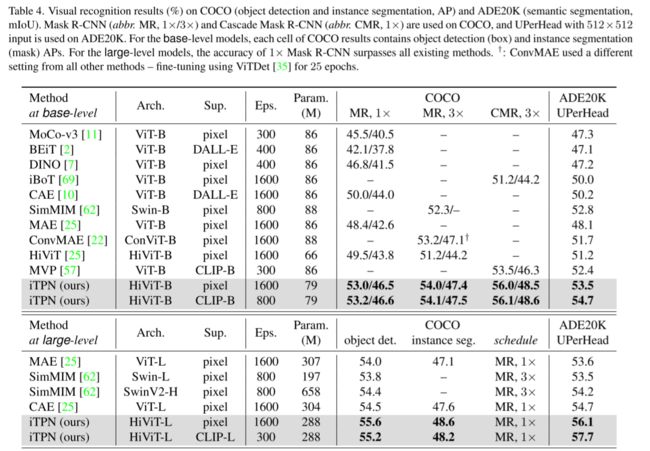
base/large-level iTPN在coco数据集上取得53.2%/55.6% box AP,在ADE20K上取得54.7%/57.7% mIoU,极大地超过了现有的方法。
base/large-level iTPN在ImageNet-1K数据集上取得86.2%/87.8%top-1 classification accuracy,超过之前最好的记录0.7%/0.5%。
iTPN的好处
在预训练过程中重建错误较低
在下游任务中收敛速度更快,这体现了iTPN能够缩小预训练任务和下游任务的差距。
仅使用联合预训练的backbone也能提升性能
二、方法
本文使用MIM(mask feature modeling,参见https://arxiv.org/pdf/2111.06377.pdf)的辅助任务(proxy task)、使用具有层级架构的hivit作为backbone,改进了特征金字塔(feature pyramid network)作为neck。为了更好地介绍MFM,首先介绍backbone和neck的结构。
backbone
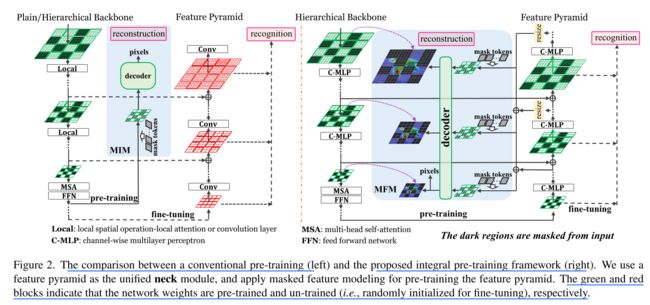
hivit的优点:vision transformer的衍生网络包括plain vit(如vithttps://arxiv.org/abs/2010.11929)和hierarchical vit如swin transformerhttps://arxiv.org/pdf/2103.14030.pdf),二者各有优缺点,而hivit集中了二者的优势。hierarchical vit相比于plain vit能通过空间的尺度变化,获得多尺度特征图,更好的提取图片特征。但是现有的hierarchical vit(如swin transformer)不适合做MIM任务。如下图所示,基于plain vit的MAE仅使用visible patch所得的token作为encoder输入,而基于hierarchical vit的SimMIM使用了visible token和masked token作为encoder输入,这导致了基于hierarchical vit的MIM任务运算量较大。hivit结构仅使用visible patch所得的token作为encoder输入,从而减小计算开销,适合应用于MIM任务,此外,hivit也继承了hierarchical vit的多尺度特征提取能力。
hivit的网络结构:
hivit论文指出,‘local inter-unit operations’ (例如,Swin中的shifting-windowself-attentions)的全局理解能力不如global intra-unit operations, 并没有提高下游任务的性能,只有层级架构(hierachical design)提高了网络的特征提取能力,因此,hivit舍弃了local inter-unit operations。以iTPN中使用的hivit-B为例展示网络结构,其中每层的channel数、stage中block的个数可根据需要调整。

以iTPN使用的hivit-B网络结构为例,hivit分为3个stage,stage1和stage2分别由3个MLP block组成,每个MLP block中含有两个ratio=3的线性层;stage3由24个transformer block组成,每个transformer block包括在vit中使用的global attention block(即MSA)和ratio=4的线性层(即FFN)。hivit的输入为56*56个大小为4*4的patch, 每个patch为128维,经过每个stage进行分辨率的降采样和维度扩张提取特征,最终得到输出。
neck
本文的neck使用了特征金字塔FPN结构,特征金字塔的好处为融合低分辨率语义信息较强的特征图和高分辨率语义信息较弱但空间信息丰富的特征图。
backbone和neck的处理流程:如下图所示,经过掩码的输入图像经过HIVIT的stage1、stage2、stage3分别得到56*56*128,28*28*256,14*14*512维的特征图,stage3的输出特征图作为特征金字塔的输入。特征金字塔的L_i层为L_i+1层经过C-MLP改变维度并且上采样后和HIVIT的L_i层相应元素相加。
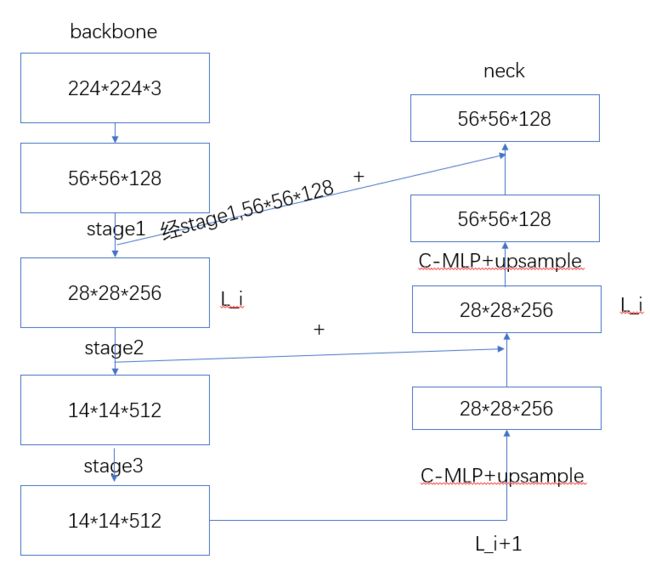
iTPN的预训练流程
如下图的右图所示,经过掩码的输入图像经过HIVIT的stage1、stage2、stage3分别得56*56*128,28*28*256,14*14*512维的特征图,stage3的输出特征图作为特征金字塔的输入。特征金字塔的L_i层为L_i+1层经过C-MLP改变维度并且上采样后和HIVIT的L_i层相应元素相加。将特征金字塔每层的输出缩放至相同大小,输入decoder,重建出mask patch。
MFM(Masked Feature Modeling)
传统的方法仅使用ground truth和预测结果计算loss,如下图所示:

然而,该方法没有充分多尺度特征图,可能导致语义信息和空间信息的损失,因此,本文提出了Masked Feature Modeling以利用多阶段的特征,如下图所示:

则最终的loss的计算公式为: ,在上图中,S=3。
,在上图中,S=3。
但是,原始数据集并没有提供ground truth 多尺度特征图。因此,本文利用知识蒸馏的方法,使用教师模型的backbone来生成ground truth 多尺度特征图,即生成 intermediate targets。本文比较了两种教师模型的backbone:moving-averaged encoder 和another pre-trained model。
moving-averaged encoder(也称pixel-supervised model)
方法:moving-averaged encoder对iTPN的backbone使用exponential moving average (EMA),平均学生模型(iTPN的backbone)的权重,从而生成教师模型backbone。其计算公式为:

由于教师模型backbone和iTPN的backbone hivit网络结构相同,因此可以直接生成多尺度的特征图,即每个stage的输出。
特点:由于权重平均值改善了所有层的输出,而不仅仅是顶层输出,因此目标模型具有更好的中间表示。由于该方法仅使用学生模型的参数,没有使用新的知识。
使用moving-averaged encoder作为教师网络预训练时使用hivit-B/hivit-L的超参数:
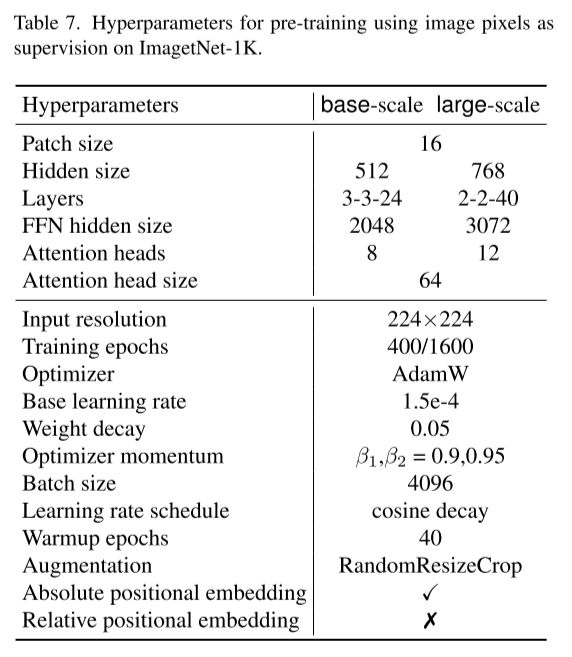
使用moving-averaged encoder作为教师网络fine-tune时使用hivit-B/hivit-L的超参数:

another pre-trained model
本文使用已经训练好的预训练模型CLIP作为教师模型,由于CLIP使用plain vit,不能获得多尺度的特征图,因此本文提出如下方法,即通过预测的多尺度特征图统一成14*14的特征图并相加,和CLIP的输出特征图进行比较,从而得出ground truth特征图:

使用 CLIP model作为教师网络预训练时使用hivit-B/hivit-L的超参数:

使用 CLIP model作为教师网络fine-tune时使用hivit-B/hivit-L的超参数:

三、实验
Settingsand Implementation Details
在预训练中:
(1)预训练数据集:ImageNet-1K
(2)输入形式:使用224*224的图片,分成14*14个16*16的patch
(3)mask ratio:75%(和MAE相同)
(4)optimizer:AdamW
(5)初始学习率:1.5 × 10−4
(6)weight decay 0.05
(7)batch size:4096
(8)学习率的变化:cosine annealing schedule
(9)warm-up epochs:40
(10)对于MFM,若使用方法一moving-averaged model,iTPN预训练轮数分别为400,1600;若使用方法二pretrained CLIP model,预训练轮数分别为300,800,轮数设置基于不同方法的计算开销。
(11)使用64个NVIDIA Tesla-V100 GPUs,1600-epoch pixel-supervised pretraining of iTPN-base/large 花费 75/115 hours
分类任务
基于 ImageNet-1K
Fine-tuning:encoder的最后一层后接入线性分类层,对所有参数进行微调
参数设置

比较:

对于hivit-B,iTPN仅需400轮即可超过MAE、HiViT训练1600/800轮的准确率,说明iTPN的联合训练方法有助于加速下游任务的收敛。
使用CLIP-B作为教师模型仅使用更少的轮数即可超过使用pixel作为教师模型的方法,说明CLIP的特征提取能力更强。
由于分类任务仅使用预训练的backbone,并且取得了比以往的方法更好的效果,说明iTPN联合训练方法能使backbone更好地提取特征。
同样,hivit-L也体现了相同的特性,使用HiViT-L/14、CLIP-L作为教师模型的方法取得了88%的top1准确率。
目标检测和分割任务
由于此时也迁移了预训练的neck,因此取得更好的性能提升。结果如下图所示:
分析
消融实验
关于是否使用iPT和是否使用特征金字塔的比较,说明二者的优势
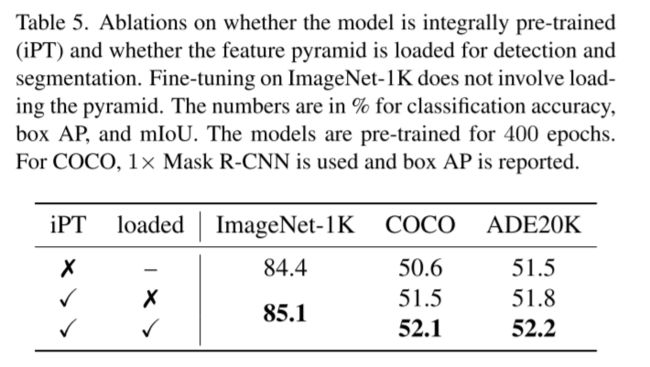
关于是否在特征金字塔中使用C-MLP和是否使用MFM的讨论,说明二者的优势
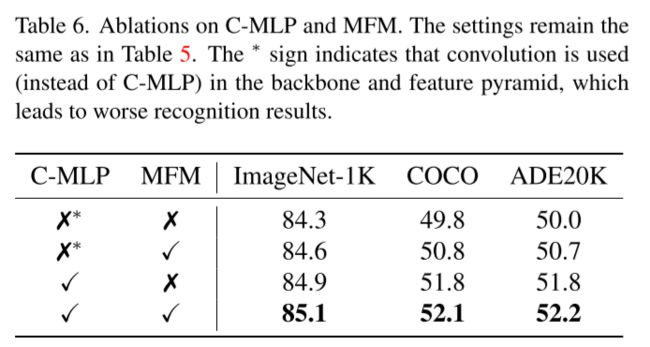
关于C-MLP的讨论将在后文讨论。
可视化

从encoder的特征图可看出,iTPN能够多尺度的提取特征,提取更丰富的信息。
从decoder的特征图可看出,iTPN能够提取不同token的语义关联。
四、补充说明
关于信息泄露的讨论
信息泄露分为inter-layer information leak和intra-layer information leak
inter-layer information leak

倘若在特征金字塔中的每一层都使用随机mask操作,如左图所示,两层mask区域不同,因此前一层的visible patch会泄露信息至后一层的mask patch,该问题的解决方法为保持每一层mask patch的空间对应性,如下图所示:
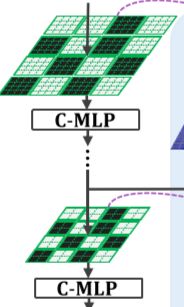
intra-layerinformation leak

若在特征图中使用卷积(如3*3 conv),该卷积可能覆盖了visible patch和maskpatch,因此mask patch很容易通过visible patch重建得出,故造成信息泄露。该问题的解决方法为使用C-MLP( channelwiseMLP)替代卷积,由于C-MLP可视为1*1的卷积,因此不会造成mask patch和visiblepatch的共同输出。
2、模型吞吐量(throughput)

HiViT相比ViT吞吐量更小。
模型复杂度

和MAE相比,iTPN的参数量更小,且FLOPs和MAE相当。
五、参考文献
https://zhuanlan.zhihu.com/p/526036013
https://zhuanlan.zhihu.com/p/598846422
https://blog.csdn.net/StupidAutofan/article/details/121784739
https://blog.csdn.net/shenlanshenyanai/article/details/121935254
https://blog.csdn.net/weixin_44911037/article/details/123033040
https://www.cnblogs.com/lhiker/articles/16153912.html
Zhang X, Tian Y, Xie L, et al. HiViT: A Simpler and More Efficient Design of Hierarchical Vision Transformer[C]//International Conference on Learning Representations.
Liu Z, Ning J, Cao Y, et al. Video swin transformer[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 3202-3211.
Tsung-Yi Lin, Piotr Doll´ar, Ross B. Girshick, Kaiming He, Bharath Hariharan, and Serge J. Belongie. Feature pyramid networks for object detection. In IEEE CVPR, pages 936–944, 2017.
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, pages 8748–8763. PMLR, 2021.