【深度】北大王奕森:对抗机器学习的鲁棒、隐私和架构
第九届国际学习表征大会(ICLR 2021)是深度学习领域的国际顶级会议。在正式会议召开之前,青源Seminar于2月19日-21日成功召开了ICLR 2021 中国预讲会。回放链接:hub.baai.ac.cn/activity/details/131
本文介绍北京大学智能科学系助理教授王奕森在预讲会上的报告:「Adversarial Machine Learning on Robustness, Privacy and Architecture」。报告中,王奕森介绍了其团队近年来从对抗性机器学习的视角出发,对模型的鲁棒性、隐私保护、模型架构等问题的研究工作。
整理:熊宇轩
审校:贾伟
近年来,机器学习技术得到了长足的发展,该技术已经被广泛应用于图像分类、语音识别、目标检测、医学诊断、无人驾驶等领域。
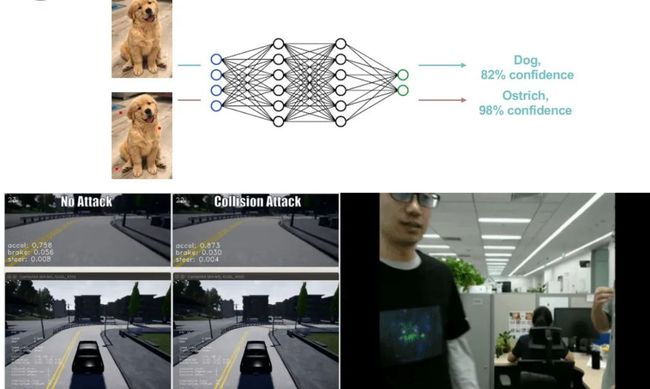
图 1:机器学习系统存在的问题——对抗样本
但是,在实际应用场景下,机器学习技术仍然存在一些不足。如图 1 所示,在正常情况下,神经网络模型能将包含「狗」的图像正确分类。然而,如果我们对红色亮点所在的像素点进行一些修改,尽管人还是可以对该图像进行正确分类,但是神经网络模型则可能将该图片错误分类为「鸵鸟」。
而在更加敏感的领域中,这种模型鲁棒性差的现象则会造成更严重的影响。例如,在自动驾驶领域中,道路中的阴影可能会使汽车错误判断路线,导致汽车「撞墙」;而在视频监控领域中,人衣服上的图案则有可能使模型无法检测到有人的出现,从而使监控画面中的人「隐身」。我们将上述使机器学习系统失效的数据称为「对抗样本」。
为了更加合理、安全地使用机器学习系统,我们需要重新思考机器学习系统工作的方式,可以将机器学习存在对抗样本的问题视为一种机器学习解决方案的「压力测试」。

图 2:对抗性样本示例
就数字空间的白盒对抗样本而言,模型的训练实际上是一个经验风险最小化(ERM)的过程,而对抗性攻击则要求我们反过来在某种限制条件下最大化损失函数。为了保证对抗性样本 和正常样本 无法轻易被人类区分开来,因此我们要求二者的 L-p 范数上界为某个较小的值 。例如,在 CIFAR-10 数据集上,我们往往采取 8 个像素点上的扰动,即。针对上述对抗性攻击,我们通常有两种常用的优化方式:(1)Fast Gradient Sign Method(FGSM):无穷范数情况下的最速下降(2)Projected Gradient Descent(PGD):迭代化的 FGSM。

图 3:对抗训练
为了让模型更加鲁棒,一个直观的想法是:将对抗样本加入到训练过程中(即对抗训练)。如图 3 所示,对抗性训练是一种最小最大优化(minmax)过程,内层的最大化过程被用于生成对抗样本(注:这是一种带约束的优化问题),而外层的最小化过程则使用内层最大化部分生成的对抗样本进行 ERM 模型训练。
01
用于提升模型鲁棒性的对抗性学习

图 4:最大化过程的收敛评分
直观地说,我们认为内层最大化过程的优化结果对外层 ERM 训练的结果具有很大的影响。然而,目前仍然缺乏有效的度量指标衡量内层优化过程的效果。
为此,王奕森博士团队在 ICML 2019 发表了论文「On the Convergence and Robustness of Adversarial Training」,提出了名为「一阶稳定条件」(FOSC)的内层最大化过程的优化效果度量指标,它可以帮助 Danskin 定理更好地成立。

图 5:收敛理论
通过使用 FOSC,我们发现当内层最大化过程优化到一定精度后(),就可以保证外层的最小化过程能够找到鲁棒的解,对抗性训练可以收敛到某个一阶稳定性点,当足够小时,我们可以通过对抗训练找到一个鲁棒的模型,其参数为。

图 6:为什么我们需要 FOSC?
下面,我们将说明提出 FOSC 指标的必要性。
当我们最大化内层 Loss 函数时,其值会逐渐上升至「平台」期。那么,Loss 上升至「平台」期是否意味着我们找到了非常好的解呢?
如图 6(a) 和图 6(b) 所示,我们发现「Step Size」和「Step Number」的取值对模型鲁棒性有较大的影响,而损失函数的分布几乎一样。因此,我们无法直接根据「损失函数不变」这一现象判断是否找到了较好的对抗样本。
如图 6(c) 和图 6(d) 所示,对于 FOSC 而言,模型鲁棒性越高则 FOSC 的值越小。因此,FOSC 对于最终模型的鲁棒性而言是一种更加可靠的标志。

图 7:从 FOSC 看对抗训练
此外,我们还可以使用 FOSC 对整个对抗训练的过程进行度量。具体而言,我们分别考察训练 10、60、100 轮三个阶段(即训练的早期、中期、后期)的训练情况。实验结果表明,标准的对抗训练在训练的早期会出现过拟合现象,而在训练后期 FOSC 值会上升,即内层最大化求解的结果变差。
直观地说,为了解决训练早期出现的过拟合现象,我们考虑再训练早期使用较弱的对抗攻击方式(例如,FGSM),从而提升模型的鲁棒性能。如图 7(b) 所示,将早期的对抗攻击方式换为 FGSM 后,可以将鲁棒性有效地提升 1-2 个百分点,这种鲁棒性的提升也可以从如图 7(c) 所示的 FOSC 的分布中反应出来。实际上,这也正是「预热」(Warm-up)技术背后的原理,它是一种得到更好的内层最大化求解结果的方式。
那么,我们是否还可以通过其它的方式得到更好的内层最大化求解结果呢?
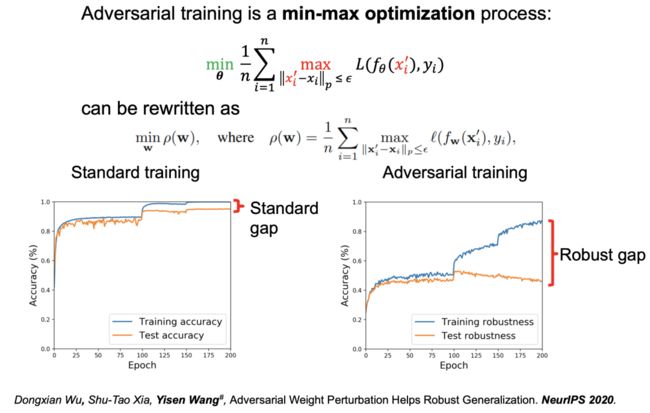
图 8:重新思考鲁棒泛化鸿沟
王奕森博士团队于 NeurIPS 2020 上发表的论文「Adversarial Weight Perturbation Helps Robust Generalization」中从鲁棒泛化的角度重新思考该问题。
首先,我们可以将上述最小最大优化的过程重写为

在标准的训练过程中, 训练时得到的准确率和测试时得到的准确率之间的「泛化误差」(Generalization Gap)较小,而在对抗训练中则会得到较大的「鲁棒性误差」,即训练时的鲁棒性很高而测试时的鲁棒性很低。而我们则试图缩小这种「鲁棒性误差」。

图 9:从 Weight loss lands 的视角观察泛化误差
受标准训练过程的启发,我们知道当「Weight loss landscape」(loss 随 weight 的变化情况)越平缓时,标准的泛化误差则越小。因此,我们试图探究是否可以将这一性质迁移到对抗训练中来。
在这里,我们借鉴了 Hao Li 等人于 NeurIPS 2018 年上发表的论文中提出的可视化方法,从而绘制损失函数的变化情况。其中,我们会向训练好的模型中加入一定的扰动,并查看损失函数分布变化,从而得到「Weight loss landscape」。
通过直观的思考,我们很自然地联想到在对抗训练环境下将标准训练中的替换为提前生成好的对抗样本,然后通过类似于标准训练中的方式,绘制出「Weight loss landscape」。然而这种方法并不可行,我们无法得到「Weight loss landscape 越平缓则鲁棒性误差越小」这一结论。
通过分析,我们发现上述方法之所以不可行是由于绘制损失函数变化情况的方式不正确。由于我们对模型进行了扰动,而对抗样本的生成高度依赖于当前的模型,因此对抗样本的生成应该也随之变化(即在扰动过程中实时生成对抗样本)。
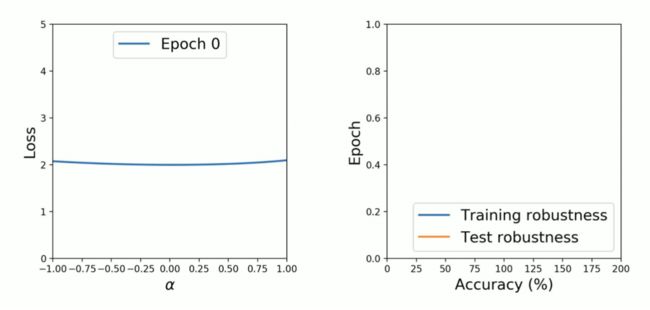
图 10:Weight loss landscape 与泛化误差变化情况
在绘制出正确的损失函数变化情况后,我们观察到:在对抗训练的早期,泛化误差较小,「Weight loss landscape」较为平缓;而在训练的后期,泛化误差较大,「Weight loss landscape」较为尖锐。
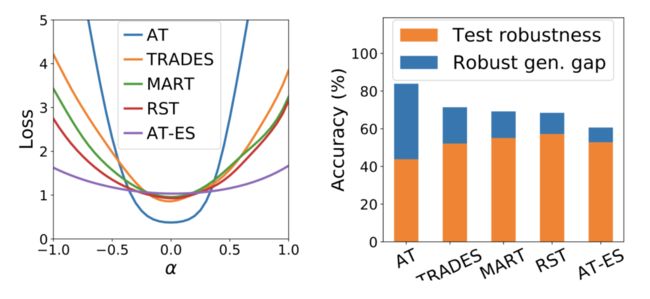
图 11:不同训练方式下损失函数与「Weight loss landscape」的关系
如图 11 所示,我们针对不同的对抗训练方式绘制出了其损失函数变化情况。实验结果表明,「Weight loss landscape」越平缓则泛化误差越小。
从 PAC-Bayesian 边界的角度来看,公式
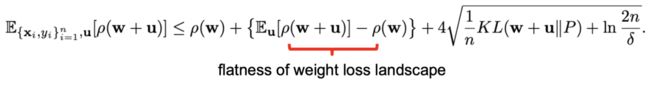
中的第二项恰好代表了「Weight loss landscape」的平坦程度。因此,我们可以将这一项显式地加入到训练的目标函数中,即将求期望操作替换为最大化操作(期望恒小于最大值),新的目标函数可以写作:

此时,我们将原先的「min-max」问题替换为了「min-max-max」优化问题,从而为原先的「min-max」问题得到更好的解。直观地说,对于输入的扰动得到了每个样本的局部最差值,而对于模型权值的扰动则为多个样本得到了全局最差值。

图 12:对抗性权值扰动可以带来普遍的鲁棒性提升
通过引入上述对抗性权值扰动方法,可以使各种对抗训练的变种面对各种攻击方式有普遍的鲁棒性提升。此外,近年来预训练技术在人工智能的各个领域大行其道。然而,我们发现在不使用预训练技术的情况下,仅仅对目标函数进行一些本质的改进也可以获得与使用预训练技术相当的性能,而将对抗性权值扰动与预训练技术相结合还可以进一步提升模型性能。

图 13:如何考虑原本就分类错误的样本?
接下来,我们将分析外层最小化过程对于鲁棒性的影响。
首先,内层的最大化过程的作用是生成对抗样本,而对抗样本仅仅定义在分类正确的样本上(即通过扰动使模型原本可以正确分类的样本会被错误分类)。那么,我们如何考虑原本就无法分类正确的样本呢?
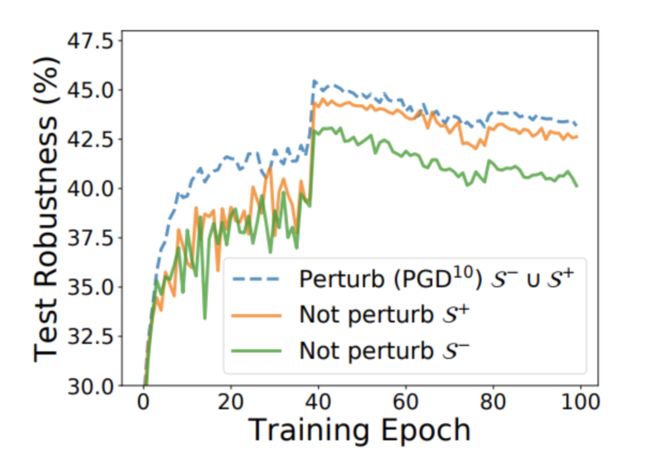
图 14:分类正确的样本 vs. 分类错误的样本
在王奕森博士团队于 ICLR 2020 上发表的论文「Improving Adversarial Robustness Requires Revisiting Misclassified Examples」中,他们探讨了分类正确/错误的样本对模型最终的鲁棒性的影响。在本文中,我们对其中一部分样本进行扰动,而不扰动另一部分样本。实验结果表明,原本分类错误的样本对于最终模型的鲁棒性有很大的影响。

图 15:进一步考虑最大化过程、最小化过程
此外, 如上文所述,求解最大化过程的结果只需要满足较高的精度即可,不同的内层最大化技术对于模型的鲁棒性影响甚微;而不同的外层最小化技术(是否加入正则项)对于模型的鲁棒性有很大的影响。

图 16:Misclassification aware adversarial risk(MART)
至此,我们在对抗性风险(Adversarial risk)中分别考虑分类正确和分类错误的样本,从而得到了如图 16 所示的「感知误分类的对抗性风险」(Misclassification aware adversarial risk)。
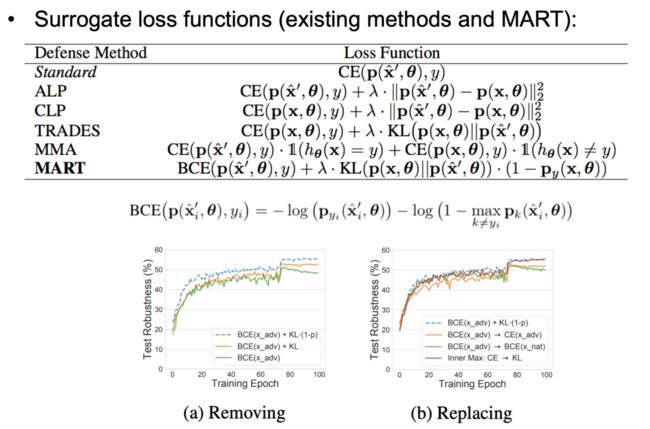
图 17:MART
为了使训练过程可以正常工作,我们使用替代损失函数替换上文中的指示函数,最终得到 MART 的损失函数为一个增强交叉熵(BCE)损失和重新加权的 KL 散度损失函数之和。在重加权项中,若样本被分类错误,我们将赋予该样本更大的权重。直观地说,分类错误的样本通常位于决策边界附近,而决策边界的对抗样本应该对决策边界的调整作用较大,因此我们着重考虑误分类样本。在如图 17 所示的消融实验中,我们考虑了 MART 中不同构成元素对模型鲁棒性的影响,从而确定了如图 17 所示的 MART 损失函数的最终形式。
02
用于隐私保护的对抗性机器学习

图 18:如何使私有数据无法被机器学习模型利用
如今,我们每个人都是网络空间的参与者,我们上传到网络中的图像、文本等数据可能会被他人收集起来训练深度神经网络模型。然而,我们往往并没有授权给某些公司将这些数据用作商业用途,因而存在一定的隐私泄露隐患。
在王奕森博士团队于 ICLR 2021 上发表的论文「Unlearnable Examples:Making Personal Data Unexploitable」中,他们探究了如何在隐私数据被上传到网络空间中之前,对这些数据进行相应的「加密」操作,从而实现隐私保护的目的。在本文中,他们试图对人脸图像数据进行修改,使深度学习模型无法利用该样本进行训练,而人类仍然可以正确识别图像。

图 19:生成无法学习的样本
实际上,「不可学习样本」与「对抗样本」的生成方式是相反的。对抗样本是通过在测试阶段最大化加入扰动后的损失函数获得的,而我们反过来可以通过在训练阶段最小化加入噪声后的损失函数(使其趋近于 0)获得不可学习样本,从而使模型无法进行学习。

图 20:生成不可学习样本
具体而言,我们可以将生成不可学习样本的过程形式化定义为一个「min-min」的两层优化目标,从而找到能够最小化误差的噪声。首先,我们需要训练一个参数为的模型;接着,我们将基于当前的模型生成误差最小化噪声。其中,误差分为类层次上的噪声和样本层次上的噪声。
通过这种方式获得的噪声具有迁移能力,我们可以将在 CIFAR-10 上生成的噪声迁移到 CIFAR-100 数据集上。此外,人类视觉无法区分出这种噪声对样本的修改,而机器使用不可学习样本训练得到的损失函数则为 0。

图 21:实验结果
实验结果表明,针对测试时的准确率指标而言,无论是加入随机噪声还是误差最大化噪声(对抗噪声)都无法使模型丧失学习能力,而加入误差最小化噪声则可以使样本不可被学习(测试时得到的准确率非常低)。如图 21 下方的表格所示,在不同的数据集上,向各种模型中添加类层次和样本层次上的噪声均可以得到不可学习的样本,模型预测准确率极低,可以起到保护隐私的效果。
03
模型架构与鲁棒性的关系

图 22:跳跃链接的影响
为了探究模型架构与鲁棒性的关系,在王奕森博士团队于 ICLR 2020 上发表的论文「Skip Connections Matter: On the Transferability of Adversarial Examples Generated with ResNets」中探讨了跳跃链接结构的影响。
在反向传播梯度回传的过程中,我们可以跳过一部分卷积残差模块,只使用跳跃链接。我们发现当跳过的残差模块数量增长到一定程度后,模型的「黑盒」迁移能力会增强,即跳跃链接可以暴露出更多可迁移的信息。
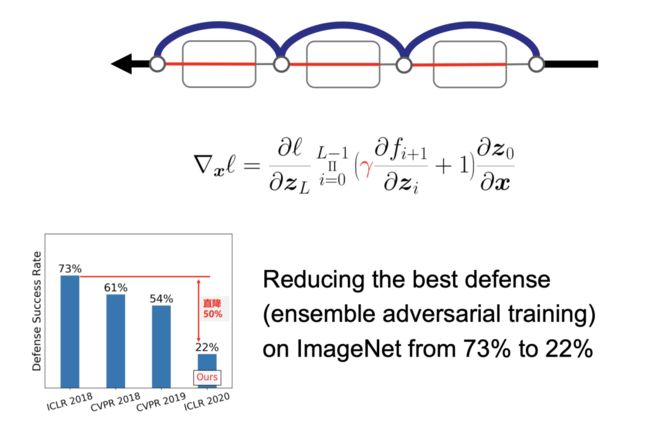
图 23:跳跃梯度方法
基于上述观察结果,我们提出了跳跃梯度方法(SGM),它可以大幅度提升对抗样本的迁移性能(将模型 A 上的对抗样本以较高的攻击成功率应用到模型 B 上)。如图 23 所示,较粗的线条代表较大的梯度,我们在对抗样本梯度回传的过程中通过跳跃链接回传大量的梯度。我们将通过卷积层回传的梯度乘以一个取值范围为 [0,1] 的权重,即缩小通过卷积层回传的梯度(线条更细)。通过实验,我们可以让包括「集成对抗训练」在内的最佳黑盒防御方式在 ImageNet 数据集上的防御成功率会从 73% 降低至 22%。
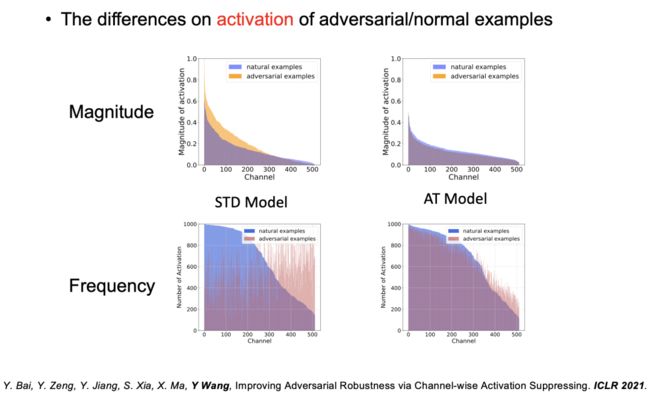
图 24:激活问题
此外,在 ICLR 2021 上发表的论文「Improving Adversarial Robustness via Channel-wise Activation Suppressing」中,王奕森博士团队还观察了标准模型和对抗训练模型的激活函数的幅值和频率。实验结果表明,对于标准模型而言,对抗样本激活的幅值更高,其激活频率也十分均匀。在进行了对抗训练之后,对抗样本激活的幅值被有效减小,模型的鲁棒性得到了提升。然而,此时激活的频率仍然较为平均,即一些不必要的通道将会被激活,这种现象也说明模型鲁棒性仍然存在一些缺陷。

图 25:通道激活抑制
针对上述问题,我们设计了一种通道激活抑制模块(CAS)。以往,我们通常认为每个通道的激活值的重要性是相同的。在这里,我们将考虑通道之间的关系,为不同的通道赋予不同的权值,使不需要被激活的通道被抑制。如图 25 所示,之前各种不同的防御方式(kWTA、SAP、PCL)都没能解决各通道激活值均匀的问题,而本文提出的 CAS 方法则有效抑制了不需要的通道。
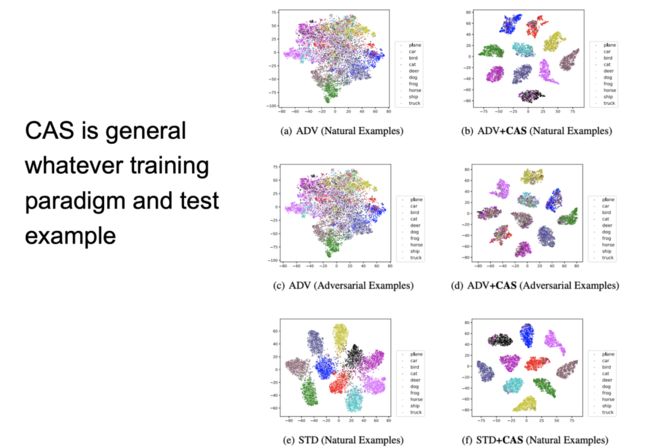
图 26:实验结果
通过实验,我们发现 CAS 方法的通用性很强,无论我们采用对抗训练还是普通训练范式,使用对抗样本还是普通样本,加入了 CAS 模块的模型都可以将各种类别的表征有效地分开。
04
结语

图 27:相关文献
本次演讲涉及的相关论文如图 27 所示,详情请参阅具体论文的叙述。在王奕森博士看来,构建可靠可信的机器学习系统是我们不懈追求的目标!
欢迎对机器学习相关的理论及算法研究,包括对抗学习、图神经网络、弱监督或自监督学习、联邦学习等感兴趣的同学,联系王奕森老师读博或实习!
感兴趣的研究者请入群深入交流!

青源研究组-对抗学习兴趣群

点击左下角“阅读原文”,了解更多!