hadoop3.2.4 集群环境搭建
本文介绍hadoop3.2.4集群环境搭建看本文之前最好先看看伪分布式的
搭建文章链接如下,因为有些问题是伪分布式的时候遇到的,这里就不重复展示解决办法了。
链接:伪分布式搭建
文章目录
- 前言
- 一、准备机器
- 二、linux环境准备工作
-
- 2.1 修改主机名
- 2.2 停止并且禁用防火墙
- 2.3 配置机器之间的免密登录
-
- 2.3.1 生成公钥私钥
- 2.3.2 拷贝公钥到需要免密登录机器
- 2.3.3 测试免密登录
- 三、hadoop配置文件修改
-
- 3.1修改core-site.xml
- 3.2 修改hdfs-site.xml文件
- 3.3 修改mapred-site.xml文件
- 3.4 修改 yarn-site.xml文件
- 3.5 修改workers文件
- 3.6 配置文件拷贝到其他机器上
- 四、启动集群
-
- 4.1 在hadoop1上启动hdfs
- 4.2 hadoop2上启动yarn
- 五、运行测试demo
-
- 5.1 计算圆周率demo
- 六、启动脚本
- 七、关键配置说明
-
- 7.1yarn-site.xml 中
- 7.2 hdfs-site.xml,确定secodarynamenode程序位置
- 7.3确定yarn启动的节点是hadoop2。core-site.xml
- 7.4 workers文件的配置,
- 八、总结
前言
实际运用中,hadoop的搭建一定是集群部署方式,所以这里搭建了下集群部署方式,也熟悉hadoop的集群搭建。
一、准备机器
这次搭建,准备了三台虚拟机,分别是
hadoop1 192.168.184.129
hadoop2 192.168.184.130
Hadoop3 192.168.184.131
三台虚拟机相互要能ping通,我这里使用的是虚拟机用的nat网络配置,可以看我另一篇文章有说如何配置。nat虚拟网络配置
节点的部署规划如下
| Hadoop1 | hadoop2 | hadoop3 | |
|---|---|---|---|
| hdfs | NameNode DataNode | SecondaryNameNode DataNode | DataNode |
| yarn | NodeManager | NodeManager ResourceManager | NodeManager |
二、linux环境准备工作
以下操作需要在三台机器都进行操作,
2.1 修改主机名
Vi /etc/hostname```
修改主机名分别为hadoop1、hadoop2、hadoop3
添加ip映射主机名
Vi /etc/hosts
192.168.184.129 hadoop1
192.168.184.130 hadoop2
192.168.184.131 hadoop3
2.2 停止并且禁用防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
2.3 配置机器之间的免密登录
免密登录的原理图如下,
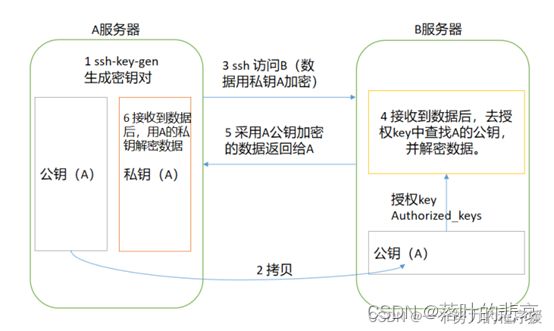
2.3.1 生成公钥私钥
ssh-keygen -t rsa
2.3.2 拷贝公钥到需要免密登录机器
然后进入 cd .ssh 目录
可以看到有两个文件
cd .ssh

分别是私钥和公钥,拷贝公钥到hadoop2、hadoop3
执行
ssh-copy-id hadoop2
ssh-copy-id hadoop3
2.3.3 测试免密登录
ssh hadoop2
ssh hadoop3
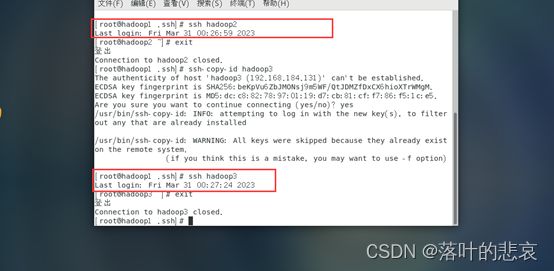
如果不需要输入密码则修改成功,同理,在hadoop2、hadoop3上设置到另外两台机器免密登录。这里就不展示了,一样的操作。
三、hadoop配置文件修改
在安装目录的 etc/hadoop目录下修改以下文件。
3.1修改core-site.xml
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.184.129:8020</value>
</property>
<!-- 设置Hadoop本地保存数据路径 注意这个目录不存在会导致启动不起来-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/tools/hadoop-3.2.4/data</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
3.2 修改hdfs-site.xml文件
<!-- 设置SecondNameNode进程运行机器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.184.130:9868</value>
</property>
3.3 修改mapred-site.xml文件
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.184.129:10020</value>
</property>
<!-- MR程序历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.184.129:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
3.4 修改 yarn-site.xml文件
<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.184.130</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://192.168.184.129:19888/jobhistory/logs</value>
</property>
<!-- 历史日志保存的时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
3.5 修改workers文件
192.168.184.129
192.168.184.130
192.168.184.131
3.6 配置文件拷贝到其他机器上
scp -r /root/tools/hadoop-3.2.4/etc/hadoop root@hadoop2:/root/tools/hadoop-3.2.4/etc/hadoop
scp -r /root/tools/hadoop-3.2.4/etc/hadoop root@hadoop3:/root/tools/hadoop-3.2.4/etc/hadoop
四、启动集群
注意如果是初次执行启动,需要在每台机器上执行初始化操作
hdfs namenode –format
4.1 在hadoop1上启动hdfs
安装目录我的是/root/tools/hadoop-3.2.4上执行以下操作。
./sbin/start-dfs.sh
启动dfs报错如下
dfs/name is in an inconsistent state: storage directory does not exist or is not accessible
解决:重新格式化namenode
hdfs namenode –format
我的不是这个问题,是路径前面多了一个空格去掉空格即可。
启动成功后访问namenode管理页面
http://192.168.184.129:9870 可以看到三个datanode都起起来了
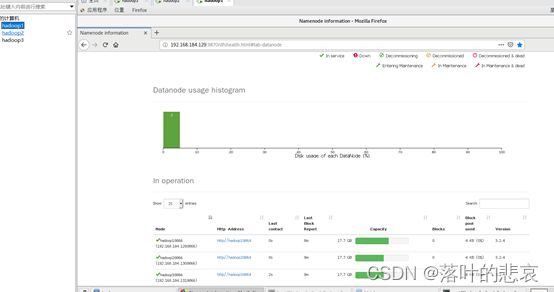
4.2 hadoop2上启动yarn
./sbin/start-yarn.sh
访问resourcemanager管理页面
http://192.168.184.130:8088
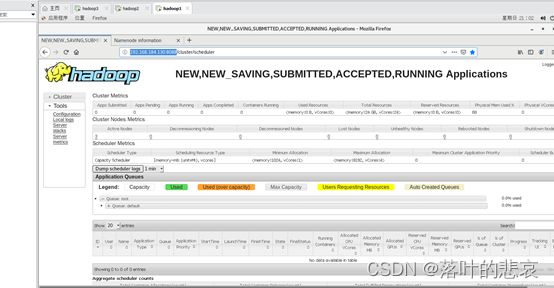
五、运行测试demo
5.1 计算圆周率demo
到 share/mapreduce/目录表执行
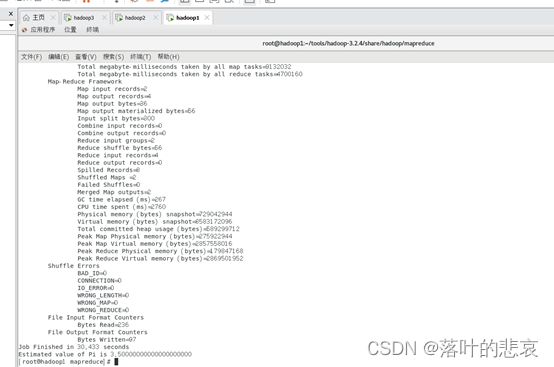
hadoop jar hadoop-mapreduce-examples-3.2.4.jar pi 2 4
结果如图所示
六、启动脚本
启动有点麻烦,写了个脚本,只需要执行一次即可启动,关闭集群。
hadoop.sh,修改文件后需要修改执行权限,
chmod 777 hadoop.sh
#!/bin/bash
# 判断参数个数
if [ $# -ne 1 ];then
echo "need one param, but given $#"
fi
# 操作hadoop
case $1 in
"start")
echo " ========== 启动hadoop集群 ========== "
echo ' ---------- 启动 hdfs ---------- '
ssh hadoop1 "/root/tools/hadoop-3.2.4/sbin/start-dfs.sh"
echo ' ---------- 启动 yarn ---------- '
ssh hadoop2 "/root/tools/hadoop-3.2.4/sbin/start-yarn.sh"
;;
"stop")
echo " ========== 关闭hadoop集群 ========== "
echo ' ---------- 关闭 yarn ---------- '
ssh hadoop1 "/root/tools/hadoop-3.2.4/sbin/stop-yarn.sh"
echo ' ---------- 关闭 hdfs ---------- '
ssh hadoop2 "/root/tools/hadoop-3.2.4/sbin/stop-dfs.sh"
;;
*)
echo "Input Param Error ..."
;;
esac
启动集群,关闭集群
./hadoop.sh start
./hadoop.sh stop
七、关键配置说明
节点关键的配置有,
7.1yarn-site.xml 中
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.184.130</value>
</property>
7.2 hdfs-site.xml,确定secodarynamenode程序位置
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.184.130:9868</value>
</property>
7.3确定yarn启动的节点是hadoop2。core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.184.129:8020</value>
</property>
确定namenode位置也就是,hdfs启动节点是hadoop1
7.4 workers文件的配置,
就是确定datanode和nodemanage所有节点都运行。
八、总结
这里我就没有新建用户来运行hadoop程序,严格来说不能直接用root运行hadoop程序,这里我就懒得弄了,就直接用root运行,用root运行方法前一篇文章有说,可以看看前面的文章。这里展示了从头到尾的集群搭建过程也记录了遇到的问题,如果对你有帮助点个赞吧。