《C++Primer 第五版》——第十一章 关联容器
《C++Primer 第五版》——第十一章 关联容器
- 11.1 使用关联容器
-
-
- 使用 map
- 使用 set
-
- 11.2 关联容器概述
-
- 11.2.1 定义关联容器
-
- 初始化 multimap 或 multiset
- 11.2.2 关键字类型的要求
-
- 有序容器的关键字类型
- 使用关键字类型的比较函数
- 11.2.3 pair 类型
-
- 创建pair对象的函数
- 11.3 关联容器操作
-
- 11.3.1 关联容器迭代器
-
- set 的迭代器是 const 的
- 遍历关联容器
- 关联容器和算法
- 11.3.2 添加元素
-
- 向 map 添加元素
- 检测 insert 的返回值
- 展开递增语句
- 向 multiset 或 multimap 添加元素
- 11.3.3 删除元素
- 11.3.4 map 的下标操作
-
- 使用下标操作的返回值
- 11.3.5 访问元素
-
- 对 map 和 unordered_map 使用 find 代替下标操作
- 在 multimap 或 multiset 中查找元素
- 另一种不同的,面向迭代器的解决方法
- equal_range 函数
- 11.3.6 一个单词转换的 map
-
- 单词转换程序word_transform
- 建立转换映射buildMap
- 生成转换文本transform
- 11.4 无序容器
-
-
- 使用无序容器
- 管理桶
- 无序容器对关键字类型的需求
-
关联容器和顺序容器有着根本的不同:
关联容器中的元素是按关键字来保存和访问的。与之相对,顺序容器中的元素是按它们在容器中的位置来顺序保存和访问的。
虽然关联容器的很多行为与顺序容器相同,但其不同之处反映了关键字的作用。
关联容器支持高效的关键字查找和访问。两个主要的 关联容器(associative-container) 类型分别是 map 和 set 。
map中的元素是一些 关键字-值(key-value) 对:关键字起到索引的作用,值则表示与索引相关联的数据。 字典则是一个很好的使用map的例子:可以将单词作为关键字,将单词释义作为值。set中每个元素只包含一个关键字;set支持高效的关键字查询操作——检查一个给定关键字是否在set中。例如,在某些文本处理过程中,可以用一个set来保存想要忽略的单词。
标准库提供8个关联容器,如下表所示。这8个容器间的不同体现在三个维度上:
标准库中的每个关联容器
- 或者是一个
set,或者是一个map;- 或者要求不重复的关键字,或者允许重复关键字;
- 按顺序保存元素,或无序保存。
允许重复关键字的容器的名字 中都包含单词 multi ;不保持关键字按顺序存储的容器的名字 都以单词 unordered_ 开头。
因此关联容器类型 unordered_multiset 是一个允许重复关键字,元素无序保存的集合,而一个 set 则是一个要求不重复关键字,有序存储的集合。无序容器使用哈希函数来组织元素。
- 类型
map和multimap定义在头文件 map 中;- 类型
set和multiset定义在头文件 set 中;- 其它的4个无序容器则定义在头文件 unordered_map 和 unordered_set 中。
| 关联容器类型 | |
|---|---|
| 按关键字有序保存元素 | |
| map | 关联数组;保存关键字-值对 |
| set | 关键字即值,即只保存关键字的容器 |
| multimap | 关键字可重复出现的map |
| multiset | 关键字可重复出现的set |
| 无序集合 | |
| unordered_map | 用哈希函数组织的 map |
| unordered_set | 用哈希函数组织的 set |
| unordered_multimap | 哈希组织的 map ;关键字可以重复出现 |
| unordered_multiset | 哈希组织的 set ;关键字可以重复出现 |
map、set、multimap和multiset的底层数据结构是红黑树,unordered_map、unordered_set、unordered_multimap和unordered_multiset的底层数据结构是哈希表,具体细节见《STL源码剖析》
11.1 使用关联容器
map 是 关键字-值对 的集合。例如,可以将一个人的名字作为关键字,将其电话号码作为值。我们称这样的数据结构为“将名字映射到电话号码”。 map 类型通常被称为 关联数组(associative array) 。关联数组与“正常”数组类似,不同之处在于其下标不必是整数。在 map 中是通过一个关键字而不是位置来查找值 。
比如,给定一个名字到电话号码的 map ,我们可以使用一个人的名字作为下标来获取此人的电话号码。
与之相对, set 就是关键字的简单集合。当只是想知道一个值是否存在时, set 是最有用的。
例如,一个企业可以定义一个名为bad_checks的 set 来保存那些曾经开过空头支票的人的名字。在接受一张支票之前,可以查询bad_checks来检查顾客的名字是否在其中。
使用 map
一个经典的使用关联数组的例子是单词计数程序,它读取输入并报告每个单词出现多少次:
// 统计每个单词在输入中出现的次数
map<string, size_t> word_count; // string到size_t的空map
string word;
while (cin >> word)
++word_count[word]; // 提取word的计数器并将其加1
for (const auto &w : word_count)// 对map中的每个元素
// 打印结果
cout<< w.first << " occurs " << w.second
<< ((w.second > 1) ? " times" : " time") << endl;
类似顺序容器,关联容器也是模板。 为了定义一个 map ,我们必须指定关键字和值的类型。在此程序中, map 保存的每个元素中,关键字是 string 类型,值是 size_t 类型。当对word_count进行下标操作时,我们使用一个 string 作为下标,获得与此 string 相关联的 size_t 类型的计数器。
while循环每次从标准输入读取一个单词。它使用每个单词对word_count进行下标操作。如果word还未在 map 中,下标运算符会创建一个新元素,其关键字为word,值为0。不管元素是否是新创建的,我们将其对应的值加1。
一旦读取完所有输入,范围for语句就会遍历 map ,打印每个单词和对应的计数器。
当从 map 中提取一个元素时,会得到一个 pair 类型的对象。简单来说, pair 是一个模板类型,保存两个名为 first 和 second 的(public)数据成员。 map 所使用的 pair 用数据成员 first 保存关键字,用 second 成员保存对应的值。
C++既有 类模板(class template) ,也有 函数模板 ,其中
vector是一个类模板。只有对C++有了相当深入的理解才能写出模板,后面在第16章才会学习如何自定义模板。
模板本身不是类或函数,相反可以将模板看作为编译器生成类或函数编写的一份说明。 编译器根据模板创建类或函数的过程称为 实例化(instantiation)。 当使用模板时,需要程序员指出编译器应把类或函数实例化成何种类型。
对于类模板来说,程序员通过提供一些额外信息来指定模板到底实例化成什么样的类,需要提供哪些信息由模板决定。提供信息的方式总是这样——即,在模板名字后面跟一对尖括号
<>,在括号内添加信息。
使用 set
上一个示例程序的一个合理扩展是:忽略常见单词,如"the"、“and”、"or"等。我们可以使用 set 保存想忽略的单词,只对不在集合中的单词统计出现次数:
//统计输入中每个单词出现的次数
map<string,size_t> word_count; //string 到 size_t的空map
//想忽略的单词
set<string> exclude = { "The", "But", "And", "Or", "An", "A",
"the", "but", "and", "or", "an", "a"};
string word;
while (cin >> word)
//只统计不在exclude中的单词
if (exclude.find(word) == exclude.end())
++word_count[word] ;//获取并递增word的计数器
与其他容器类似, set 也是模板。为了定义一个 set ,必须指定其元素类型,本例中是 string 。与顺序容器类似,可以对一个关联容器的元素进行列表初始化。集合exclude中保存了12个我们想忽略的单词。
此程序与前一个程序的重要不同是,在统计每个单词出现次数之前,我们检查单词是否在忽略集合中,这是在if语句中完成的:
//只统计不在exclude中的单词
if(exclude.find(word) == exclude.end())
标准库算法 find 调用返回一个迭代器。如果给定关键字在 set 中,迭代器指向该关键字。否则, find 返回尾后迭代器。在此程序中,仅当word不在exclude中时我们才更新word的计数器。
11.2 关联容器概述
关联容器(有序的和无序的)都支持第9章中介绍的普通容器操作。
关联容器不支持顺序容器的位置相关的操作,例如 push_front 或 push_back 。
原因是——关联容器中元素是根据关键字存储的,所以以上这些操作对关联容器没有意义。而且,关联容器也不支持构造函数或插入操作这些接受一个元素值和一个数量值的操作。
除了与顺序容器相同的操作之外,关联容器还支持一些顺序容器不支持的操作(参见11.7节)和类型别名。此外,无序容器还提供一些用来调整哈希性能的操作 (参见11.4节)。
关联容器的迭代器都是双向的(参见10.5.1节)。
11.2.1 定义关联容器
如前所示,当定义一个 map 时,必须既指明关键字类型又指明值类型;而定义一个 set 时,只需指明关键字类型,因为 set 中没有值。
每个关联容器都定义了一个默认构造函数,它创建一个指定类型的空容器。 我们也可以将关联容器初始化为另一个同类型容器的拷贝,或是从一个值范围来初始化关联容器,只要这些值可以转化为容器所需类型就可以。在新标准下,我们也可以对关联容器进行值初始化:
map<string, size_t> word_count; //空容器
//列表初始化
set<string> exclude = { "the", "but", "and", "or", "an", "a",
"The", "But", "And", "or", "An", "A"};
//三个元素; authors将姓映射为名
map<string, string> authors = {{ "Joyce","James"},
{"Austen", "Jane"},
{"Dickens", "Charles"}};
与以往一样,初始化器必须能转换为容器中元素的类型。
- 对于
set,元素类型就是关键字类型。 - 对于
map,元素类型就是pair<关键字类型, 值类型>类型。在每个花括号中,关键字是第一个元素,值是第二个。因此,map将关键字映射到值。
当初始化一个 map 时,必须提供关键字类型和值类型。我们将每个 关键字-值对 包围在花括号中:{key, value},以此来指出它们一起构成了 map 中的一个元素。
初始化 multimap 或 multiset
一个 map 或 set 中的关键字必须是唯一的。即,对于一个给定的关键字,只能有一个元素的关键字等于它。容器 multimap 和 multiset 没有此限制,它们都允许多个元素具有相同的关键字。
例如,在我们用来统计单词数量的 map 中,每个单词只能有一个元素。另一方面,在一个词典中,一个特定单词则可具有多个与之关联的词义。
下面的例子展示了具有唯一关键字的容器与允许重复关键字的容器之间的区别。首先,我们将创建一个名为ivec的保存 vector ,它包含20个元素:0到9每个整数有两个拷贝。我们将使用此 vector 初始化一个 set 和一个 multiset :
// 定义一个有20个元素的vector,保存0到9每个整数的两个拷贝
vector<int> ivec;
for (vector<int>::size_type i = 0; i != 10 ; ++i){
ivec.push_back(i);
ivec.push_back(i); // 每个数重复保存一次
}
// iset包含来自ivec的不重复的元素; miset包含所有20个元素
set<int> iset(ivec.cbegin(), ivec.cend());
multiset<int> miset(ivec.cbegin(), ivec.cend());
cout << ivec.size() << endl; // 打印出20
cout << iset.size() << endl; // 打印出10
cout << miset.size() << endl; // 打印出20
即使我们用整个ivec容器来初始化iset,它也只含有10个元素:对应ivec中每个不同的元素。另一方面,miset有20个元素,与ivec中的元素数量一样多。
11.2.2 关键字类型的要求
关联容器对其关键字类型有一些限制。 对于无序容器中关键字的要求,随后介绍。对于有序容器—— map 、 multimap 、 set 以及 multiset ,关键字类型必须已经定义元素比较的方法。
默认情况下,标准库的关联容器使用关键字类型的 < 运算符来比较两个关键字。
在集合类型中,关键字类型就是元素类型,比如 set ;在映射类型中,关键字类型是元素的第一部分的类型,比如 map 。
Note:
传递给排序算法的可调用对象必须满足与关联容器中关键字一样的类型要求。
有序容器的关键字类型
可以向一个算法提供程序员自己定义的比较操作,也可以提供自己定义的操作来代替关键字上的 < 运算符。 所提供的操作必须在关键字类型上定义一个 严格弱序(strict weak ordering),可以将严格弱序看作“小于等于”。
虽然实际定义的操作可能是一个复杂的函数,但是无论怎样定义比较函数,它必须具备如下基本性质:
- 两个关键字不能同时“小于等于”对方;如果k1“小于等于”k2,那么k2绝不能“小于等于”k1。 如果k1“小于等于”k2,且 k2“小于等于”k3,那么k1必须“小于等于”k3。(传递性)
- 如果存在两个关键字,任何一个都不“小于等于”另一个,则称这两个关键字是“等价”的。如果k1“等价于”k2,且k2“等价于”k3,那么k1必须“等价于”k3。(传递性)
如果两个关键字是等价的,那么容器将它们视作相等来处理。
- 特别的是对于
map,容器中不能存在多个等价的关键字。 - 当使用
map的关键字当作某些操作时,只能有一个元素与多个“相等”的关键字关联,而我们可以用其中任意一个来访问其对应的值。
Note:
在实际编程中,重要的是,如果一个类型定义了“行为正常”的
<运算符,则它可以用作关键字类型。
使用关键字类型的比较函数
用来组织一个容器中元素的操作的类型也是该容器类型的一部分。为了指定使用自定义的操作,必须在定义关联容器类型时,提供此操作的类型。 如前所述,用尖括号指出要定义哪种类型的容器,自定义的操作类型必须在尖括号中紧跟着元素类型给出。
在尖括号中出现的每个类型,就仅仅是一个类型而已。当创建一个容器(对象)时,才会以构造函数参数的形式提供真正的比较操作(比较操作需要的类型,必须与在尖括号中指定的类型相吻合)。
例如,我们不能直接定义一个Sales_data的 multiset ,因为Sales_data没有 < 运算符。但是,可以定义一个名叫compareIsbn函数来定义一个 multiset ,因为此函数在Sales_data对象的ISBN成员上定义了一个严格弱序。函数compareIsbn应该像下面这样定义:
bool compareIsbn(const Sales_data &lhs, const Sales_data &rhs){
return lhs.isbn() < rhs.isbn();
}
为了使用程序员自己定义的操作,在定义 multiset 时必须提供两个类型:关键字类型,以及比较操作的类型——应该是一种函数指针类型,可以指向对应的操作(在这里是compareIsbn)。当定义此容器类型的对象时,需要提供想要使用的操作的指针。
在本例中,我们提供一个指向compareIsbn的函数指针:
// bookstore中的元素以ISBN的顺序进行排列
// 在这里提供给<>操作的类型,然后在构造函数中传入函数的指针
multiset<Sales_data, decltype(compareIsbn)*> bookstore(compareIsbn);
multiset<Sales_data, decltype(compareIsbn)*> bookstore(&compareIsbn); // 等价
此处使用 decltype 关键字来指出自定义操作的类型。需要记住:当用 decltype 来获得一个函数指针类型时,必须加上一个 * 来指出我们要使用一个给定函数类型的指针。
用compareIsbn来初始化bookstore对象,这表示当我们向bookstore添加元素时,通过调用compareIsbn来为这些元素排序。即,bookstore中的元素将按它们的ISBN成员的值排序。可以用compareIsbn代替&compareIsbn作为构造函数的参数,因为当我们使用一个函数的名字时,在需要的情况下它会自动转化为一个指针(参见6.7节)。当然,使用&compareIsbn的效果也是一样的。
11.2.3 pair 类型
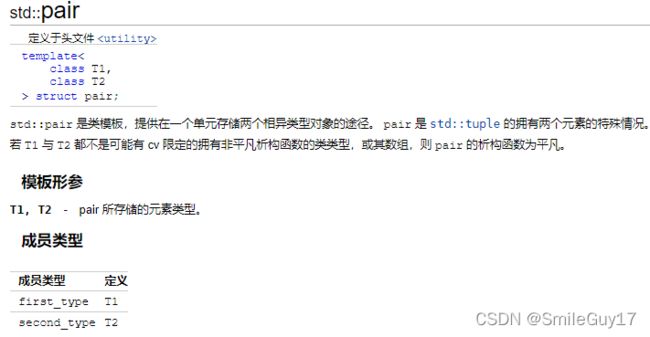
有一个名为 pair 的标准库类型,它定义在头文件 utility 中。
一个 pair 保存两个数据成员。 类似容器, pair 是一个用来生成特定类型的模板。当创建一个 pair 时,我们必须提供两个类型名, pair 的数据成员将具有对应的类型。 pair 的两个数据成员的类型不要求一样:
pair<string, string> anon; // 保存两个string
pair<string, size_t> word_count;// 保存一个string和一个size_t
pair<string, vector<int>> line; // 保存string和vectoranon是一个包含两个空 string 的 pair ,word_count 中的 size_t 成员值为0,而 string 成员被初始化为空。line保存一个空 string 和一个空 vector 。
既可以用 pair 的默认构造函数对数据成员进行值初始化。也可以为 pair 的每个成员提供初始化器:
pair<string, string> author{"James", "Joyce"};
这条语句创建一个名为author的 pair 对象,两个成员被初始化为"James"和"Joyce"。
与其他标准库类型不同, pair 的数据成员是 public 的。两个成员分别命名为 first 和 second 。可以用普通的成员访问符号来访问它们。
例如,上面的单词计数程序的输出语句中我们就是这么做的:
//打印结果
cout << w.first << " occurs " << w.second
<< ((w.second > 1) ? " times" : " time") <<endl;
此处,w是指向 map 中某个元素的引用。 map 的元素类型是 pair 。在这条语句中,我们首先打印关键字——元素的 first 数据成员,接着打印计数器—— second 数据成员。标准库只定义了有限的几个 pair 操作,下表列出了这些操作。
| pair 上的操作 | |
|---|---|
| pair< T1, T2 > p; | p 是一个 pair 对象,两个类型分别为 T1 和 T2 的成员都进行了值初始化 |
| pair< T1, T2 > p(v1, v2) | p 是一个成员类型为 T1 和 T2 的 pair ; first 和 second 成员分别用 v1 和 v2 进行初始化 |
| pair< T1, T2 > p = {v1,v2}; | 等价于 pair< T1, T2 > p(v1, v2) |
| make_pair(v1,v2) | 返回一个用 v1 和 v2 初始化的 pair 。 pair 的类型从 v1 和 v2 的类型推断出来。 该函数定义于头文件 utility 中 |
| p.first | 返回 p 的名为 first 的(公有)数据成员 |
| p.second | 返回 p 的名为 second 的(公有)数据成员 |
| p1 relop p2 | 关系运算符( < 、 > 、 <= 、 >= )按字典序定义: 例如,当 p1.first < p2.first 或 !(p2.first < p1.first) && p1.second < p2.second 成立时, p1 < p2 为 true。关系运算利用元素的 < 运算符来实现 |
| p1 == p2 | 当数据成员 first 和 second 分别相等时,两个 pair 对象相等。相等性判断利用 first 和 second 的类型的 == 运算符实现 |
| p1 != p2 | |
创建pair对象的函数
想象有一个函数需要返回一个 pair 。在C++11标准下,函数可以返回一个 {} 初始化器列表,此时程序员可以用返回值对 临时量 进行列表初始化(参见6.3.2节):
这里可能接触到了复制消除。
pair<string, int> process(vector<string> &v){
// 处理v
if(!v.empty())
return {v.back(), v.back().size()}; // 返回一个{}列表来初始化临时量
else
return pair<string, int>(); // 隐式构造返回值
}
若v不为空,我们返回一个由v中最后一个 string 及其大小组成的 pair 。否则,隐式构造一个空 pair 对象,并返回它。
在较早的C++版本中,不允许用花括号包围的初始化器来返回 pair 这种类型的对象,必须显式构造返回值:
if (!v.empty())
return pair<string,int>(v.back(), v.back().size());
我们还可以用 make_pair 来生成 pair 对象,此 pair 的两个类型来自于 make_pair 的参数:
if (!v.empty())
return make_pair(v.back(), v.back().size());
11.3 关联容器操作
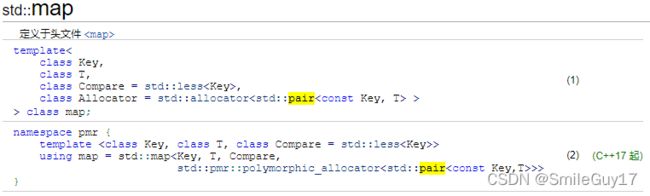
除了第9章的容器库概览中列出的类型,关联容器还定义了下表中列出的类型。这些类型表示容器关键字和值的类型。
| 关联容器额外的类型别名 | |
|---|---|
| key_type | 此容器类型的关键字类型 |
| mapped_type | 每个关键字关联的值类型。只适用于 map 、 mutimap 、 unordered_multimap 和 unordered_map |
| value_type | 容器元素的类型 对于 set ,与 key_type 相同 对于 map ,为 pair< const key_type, mapped_type > |
对于 set 类型, key_type 和 value_type 是一样的——set中保存的值就是关键字。
在一个 map 中,元素是 关键字-值对 。即,每个元素是一个 pair 对象,它包含一个关键字和一个关联的值。因为这些 pair 的关键字部分是 const 的,所以不能改变一个元素的关键字:
![]()
set<string>::value_type vl; // v1是一个string
set<string>::key_type v2; // v2是一个string
map<string, int>::value_type v3; // v3是一个pair与顺序容器一样, 使用作用域运算符 :: 来访问一个关联容器类型的成员 。
比如访问 map 的一个类型别名 map
11.3.1 关联容器迭代器
当解引用一个关联容器迭代器时,我们会得到一个类型为容器的 value_type 的值的引用。对 map 而言, value_type 是一个 pair 类型,其数据成员 first 保存 const 的关键字,数据成员 second 保存值:
// 获得指向word_count中一个元素的迭代器
auto map_it = word_count.begin();
// *map_it是指向一个pair对象的引用
cout << map_it->first; // 打印此元素的关键字
cout << " " <<map_it->second; // 打印此元素的值
map_it->first = "new key"; // 错误:关键字是const的
++map_it->second; // 正确:我们可以通过迭代器改变元素
Note:
必须记住,一个
map的value_type是一个pair,我们可以改变pair的second数据成员的值,但不能改变关键字成员first的值。
set 的迭代器是 const 的
虽然 set 类型同时定义了两种迭代器类型, iterator 和 const_iterator 类型,但这两种类型都只允许只读访问 set 中的元素。 与不能改变一个 map 元素的关键字一样,一个 set 中的关键字也是 const 的。可以用一个 set 迭代器来读取容器中元素的值,但不能修改:
set<int> iset = {0,1,2,3,4,5,6,7,8,9} ;
set<int>::iterator set_it = iset.begin();
if (set_it != iset.end()) {
*set_it = 42; // 错误:set中的关键字是只读的
cout<< *set_it <<endl; // 正确:可以读关键字
}
遍历关联容器
map 和 set 类型都支持的 begin 和 end 操作。
与往常一样,我们可以用这些函数获取迭代器,然后用迭代器来遍历容器。例如,我们可以编写一个循环来打印本文初的中单词计数程序的结果,如下所示:
// 获得一个指向首元素的迭代器
auto map_it = word_count.cbegin();
// 比较当前迭代器和尾后迭代器
while (map_it != word_count.cend()) {
//解引用迭代器,打印关键字-值对
cout << map_it->first << " occurs "
<< map_it->second << " times" << endl;
++map_it; // 递增迭代器,移动到下一个元素
}
Note:
当使用一个迭代器遍历一个
map、multimap、set或multiset时,迭代器按关键字升序遍历元素。
关联容器和算法
通常不对关联容器使用泛型算法。关键字是 const 这一特性意味着不能将关联容器传递给修改或重排容器元素的算法,因为这类算法需要向元素写入值 ,而 set 类型中的元素是 const 的, map 中的元素是 pair ,其第一个成员 first 是 const 的。
关联容器可用于只读取元素的算法。但是,很多这类算法都要搜索序列。由于关联容器中的元素不能通过它们的关键字进行(快速)查找,因此对其使用泛型搜索算法几乎总是个坏主意。
例如,我们将在第11章中看到,关联容器定义了一个名为 find 的成员函数,它通过一个给定的关键字直接获取元素。我们可以用泛型 find 算法来查找一个元素,但此算法会进行顺序搜索。使用关联容器定义的专用的 find 成员会比调用泛型 find 快得多。
在实际编程中,如果程序员真要对一个关联容器使用算法:
- 要么是将它当作一个源序列。 例如,可以用泛型
copy算法将元素从一个关联容器拷贝到另一个序列。 - 要么当作一个目的位置。 例如,可以调用
inserter将一个插入器绑定(参见10.4.1节)到一个关联容器。通过使用inserter,我们可以将关联容器当作一个目的位置来调用另一个算法。
11.3.2 添加元素
关联容器的 insert 成员函数向容器中添加一个元素或一个元素范围。 由于 map 和 set (以及对应的无序类型)包含不重复的关键字,因此插入一个已存在的元素对容器没有任何影响:
vector<int> ivec = { 2,4,6,8,2,4,6,8 }; // ivec有8个元素
set<int> set2; // 空集合
set2.insert(ivec.cbegin(), ivec.cend()); // set2有4个元素
set2.insert({1,3,5,7,1,3,5,7}); // set2又加入4个元素,现在已有8个元素
关联容器的成员函数 insert 有两个版本,分别接受一对迭代器,和一个初始化器列表。 这两个版本的行为类似对应的构造函数——对于一个给定的关键字,只有第一个带此关键字的元素才被插入到容器中。
| 关联容器 insert 操作 | |
|---|---|
| c.insert(v) | v 是 value_type 类型的对象; args 用来构造一个元素。 对于 map 和 set ,只有当元素的关键字不在容器 c 中时才插入(或构造)元素。这两个成员函数返回一个 pair ( std::pair< iterator, bool > ),它包含一个迭代器,指向具有指定关键字的元素,以及一个指示插入是否成功的 bool 值。 对于 multimap 和 multiset ,这两个成员总会插入(或构造)给定元素,并返回一个指向新元素的迭代器。 |
| c.emplace(args) | |
| c.insert(b, e) | b 和 e 是迭代器,表示一个 c::value_type 类型值的范围; il 是这种值的花括号列表。函数返回 void 。 对于 map 和 set ,只插入关键字不在 c 中的元素。对于 multimap 和 multiset ,则会插入范围中的每个元素。 |
| c.insert(il) | |
| c.insert(p, v) | 类似 insert(v) 或 emplace(args) ,但将迭代器 p 作为一个提示,指出从哪里开始搜索新元素应该存储的位置。返回一个迭代器,指向具有给定关键字的元素 |
| c.emplace(p, args) | |
向 map 添加元素
对一个 map 进行 insert 操作时,必须记住元素类型是 pair 。通常,对于想要插入的数据,并没有一个现成的 pair 对象。可以在成员函数 insert 的参数列表中创建一个 pair :
//向word_count插入word的4种方法
//也是四种创建一个pair对象的方式
word_count.insert({word, 1});
word_count.insert(make_pair(word, 1));
word_count.insert(pair<string,size_t>(word, 1));
word_count.insert(map<string,size_t>::value_type(word, 1)); // 与上一句相同
如我们所见,在标准C++11下,创建一个 pair 最简单的方法是在参数列表中使用花括号初始化。

也可以调用 make_pair 或显式构造 pair 。最后一个 insert 调用中的参数:
map<string, size_t>::value_type(s, 1)
构造一个恰当的 pair 类型,并构造该类型的一个新对象,插入到 map 中。
检测 insert 的返回值
成员函数 insert 或 emplace 返回的值依赖于容器类型和参数。 对于不包含重复关键字的容器,添加单一元素的 insert 和 emplace 版本返回一个 pair ,告诉我们插入操作是否成功。
pair 的 first 成员是一个迭代器,指向具有给定关键字的元素; second 成员是一个 bool 值,指出元素是插入成功还是已经存在于容器中。
- 如果关键字已在容器中,则
insert什么事情也不做,且返回值pair对象中的bool值为false。 - 如果关键字不存在,元素被插入容器中,且
bool值为true。
作为一个例子,我们用 insert 重写单词计数程序:
// 统计每个单词在输入中出现次数的一种更烦琐的方法
map<string, size_t> word_count; // 空的 map 容器word_count
string word;
while (cin >> word) {
// inserts an element with key equal to word and value 1;
// if word is already in word_count, insert does nothing
auto ret = word_count.insert({word, 1});
if (!ret.second) // word was already in word_count
++ret.first->second; // increment the counter
}
展开递增语句
在这个版本的单词计数程序中,递增计数器的语句很难理解。通过添加一些括号来反映出运算符的优先级,会使表达式更容易理解一些:
++((ret.first)->second); // 与 ++ret.first->second; 等价的表达式
下面我们一步一步来解释此表达式:
- ret保存insert返回的值,是一个pair。
- ret.first是pair的第一个成员,是一个map迭代器,指向具有给定关键字的元素。
- ret.first->解引用此迭代器,提取map中的元素,元素也是一个pair。
- ret.first->second map 中元素的值部分。
- ++ret.first->second递增此值。
再回到原来完整的递增语句,它提取匹配关键字word的元素的迭代器,并递增与我们试图插入的关键字相关联的计数器。
如果读者使用的是旧版本的编译器,或者是在阅读新标准推出之前编写的代码,ret的声明和初始化可能复杂些:
pair<map<string, size_t>::iterator, bool> ret =
word_count.insert(make_pair(word, 1));
应该容易看出这条语句定义了一个 pair ,其第二个数据成员的类型为 bool 类型。第一个类型是一个在 map 类型上定义的 iterator 类型。
向 multiset 或 multimap 添加元素
我们的单词计数程序依赖于这样一个事实:一个给定的关键字只能出现一次。这样,任意给定的单词只有一个关联的计数器。我们有时希望能添加具有相同关键字的多个元素。
例如,可能想建立作者到他所著书籍题目的映射。在此情况下,每个作者可能有多个条目,因此我们应该使用 multimap 而不是 map 。由于一个 multi 关联容器中的关键字不必唯一,在这些类型上调用 insert 总会插入一个元素 :
multimap<string, string> authors;
//插入第一个元素,关键字为Barth,John
authors.insert({"Barth,John", "Sot-weed Factor"});
//正确:添加第二个元素,关键字也是Barth,John
authors.insert({"Barth,John", "Lost in the Funhouse"));
对允许重复关键字的容器,接受单个元素的 insert 操作只返回一个指向新元素的迭代器。这里无须返回一个 bool 值,因为 insert 操作总是向这类容器中加入一个新元素。
11.3.3 删除元素
关联容器定义了三个版本的成员函数 erase ,如下表所示。与顺序容器一样,可以通过传递给 erase 一个迭代器或一个迭代器对来删除一个元素或者一个元素范围。这两个版本的 erase 与对应的顺序容器的操作非常相似:指定的元素被删除,函数返回 void 。
| 从关联容器中删除元素 | |
|---|---|
| c.erase(k) | 从 c 中删除每个与 k 相等的关键字所属的元素。 返回一个 size_type 值,指出删除的元素的数量 |
| c.erase(p) | 从 c 中删除迭代器 p 指定的元素。 p 必须指向 c 中一个真实元素,不能等于 c.end() (即 p 不能是尾后迭代器)。 返回一个指向 p 之后元素的迭代器,若 p 指向 c 中的尾元素,则返回 c.end() |
| c.erase(b, e) | 删除迭代器对 b 和 e 所表示的范围 {b,e) 中的元素。 返回指向最后一个被删除元素之后的迭代器(即 e 指向的元素),换句话说,返回 e |
关联容器提供一个额外的 erase 操作,它接受一个 key_type 参数。此版本删除所有匹配给定关键字的元素(如果存在的话),返回实际删除的元素的数量。我们可以用此版本在打印结果之前从word_count中删除一个特定的单词:
//删除一个关键字,返回删除的元素数量
if (word_count.erase(removal_word))
cout << "ok: " << removal_word << " removed\n";
else
cout << "oops: " << removal_word << " not found!\n";
对于保存不重复关键字的容器, erase 的返回值总是0或1。若返回值为0,则表明想要删除的元素并不在容器中。对允许重复关键字的容器,删除元素的数量可能大于1:
auto cnt = authors.erase("Barth, John");
11.3.4 map 的下标操作
map 和 unordered_map 容器提供了下标运算符和一个对应的 at 成员函数 ,如下表所示。
| map 和 unordered_map 的下标操作 | |
|---|---|
| c[k] | 返回关键字为 k 的元素;如果 k 不在 c 中,添加一个关键字为k的元素,对其进行值初始化 |
| c.at(k) | 访问关键字为 k 的元素,带参数检查;若 k 不在 c 中,抛出一个 out_of_range 异常 |
set 、 multiset 、 unordered_set 和unordered_multiset类型不支持下标[]操作,因为 set 中没有与关键字相关联的“值”。元素本身就是关键字,因此“获取与一个关键字相关联的值”的操作就没有意义了。
不能对一个 multimap 或一个 unordered_multimap 进行下标操作,因为这些容器中可能有多个值与一个关键字相关联。
类似之前用过的其他下标运算符, map 或 unordered_map 的下标运算符接受一个索引(即关键字),获取与此关键字相关联的值。
但是,与其他下标运算符不同的是: 如果关键字并不在 map 中,会为它创建一个元素并插入到 map 或 unordered_map 中,新元素关键字的关联值将进行值初始化。
例如,如果我们编写如下代码
map<string, size_t> word_count; //empty map
//插入一个关键字为Anna的元素,关联值进行值初始化;然后将1赋予它
word_count["Anna"] = 1;
将会执行如下操作:
- 在word_count中搜索关键字为Anna的元素,未找到。
- 将一个新的关键字-值对插入到word_count中。关键字是一个
const string,保存Anna。值进行值初始化,在本例中意味着值为0。 - 提取出新插入的元素,并将值1赋予它。
由于下标运算符可能插入一个新元素,程序员只可以对非 const 的 map 或 unordered_map 使用下标操作。
Note:
对一个
map或unordered_map使用下标操作,其行为与内置数组或vector的下标操作不相同:
使用一个不在容器中的关键字作为下标,会添加一个具有此关键字的元素到map或unordered_map中。
使用下标操作的返回值
map 或 unordered_map 的下标运算符与之前用过的其他下标运算符的另一个不同之处是: 其返回类型。
- 通常情况下,解引用一个迭代器所返回的类型与下标运算符返回的类型是一样的。
- 但对
map或unordered_map则不一样。当对一个map或unordered_map进行下标操作时,会获得一个mapped_type对象;但当解引用一个map或unordered_map迭代器时,会得到一个value_type对象。
与其他下标运算符相同的是 , map 或 unordered_map 的下标运算符返回一个左值。由于返回的是一个左值,所以我们既可以读也可以写元素:
cout << word_count["Anna"]; //用Anna 作为下标提取元素;会打印出1
++word_count["Anna"]; //提取元素,将其增1
cout << word_count["Anna"];//提取元素并打印它;会打印出2
Note:
与
vector与string不同,map或unordered_map的下标运算符返回的类型,与解引用map或unordered_map的迭代器得到的类型不同。
11.3.5 访问元素
关联容器提供多种查找一个指定元素的方法,如下表所示。
| 在一个关联容器中查找元素的操作 | |
|---|---|
| 成员函数 lower_bound 和 upper_bound 不适用于无序(multi)容器。 | |
| 下标和 at 操作只适用于非 const 的 map 和 unordered_map 。 | |
| c.find(k) | 如果 c 中存在关键字为 k 的元素,则返回一个迭代器,它指向第一个关键字为 k 的元素; 若 k 不在容器中,则返回尾后迭代器 |
| c.count(k) | 返回关键字等于 k 的元素的数量。 对于不允许重复关键字的容器,返回值永远是0或1。 |
| c.lower_bound(k) | 返回一个迭代器,指向第一个关键字不小于 k 的元素。 若找不到这种元素,则返回尾后迭代器 |
| c.upper_bound(k) | 返回一个迭代器,指向第一个关键字大于 k 的元素。 若找不到这种元素,则返回尾后迭代器 |
| c.equal_range(k) | 返回一个迭代器 pair ,表示关键字等于 k 的元素的范围。第一个数据成员指向首个不小于 key 的元素,第二个数据成员指向首个大于 key 的元素。。 若无元素不小于 k ,则将尾后迭代器 c.end() 作为第一元素的值返回。类似地,若无元素大于 k ,则将尾后迭代器 c.end() 作为第二元素的值返回。 |
- 如果程序员所关心的只不过是一个特定元素是否已在容器中,可能
find是最佳选择。 - 对于不允许重复关键字的容器,可能使用
find还是count没什么区别。但对于允许重复关键字的容器,count还会做更多的工作:- 如果元素在容器中,
count还会统计有多少个元素有相同的关键字。 - 如果不需要计数,最好使用
find:
- 如果元素在容器中,
set<int> iset = {0,1,2,3,4,5,6,7,8,9 };
iset.find(1) ;//返回一个迭代器,指向key == 1的元素
iset.find(11);//返回一个迭代器,其值等于iset.end()
iset.count(1); //返回1
iset.count(11) ; //返回0
对 map 和 unordered_map 使用 find 代替下标操作
对 map 或 unordered_map 类型,下标运算符提供了最简单的提取元素的方法。但是,如我们所见,使用下标操作有一个严重的副作用:如果关键字还未在 map 或 unordered_map 中,下标操作会插入一个具有给定关键字的元素。这种行为是否正确完全依赖于我们的预期是什么。
例如,单词计数程序依赖于这样一个特性:使用一个不存在的关键字作为下标,会插入一个新元素,其关键字为给定关键字,其值为0。也就是说,下标操作的行为符合我们的预期。但有时,我们只是想知道一个给定关键字是否在
map或unordered_map中,而不想改变map或unordered_map。这样就不能使用下标运算符来检查一个元素是否存在,因为如果关键字不存在的话,下标运算符会插入一个新元素。在这种情况下,应该使用find:if (word_count.find("foobar") == word_count.end()) cout << "foobar is not in the map" << endl;
在 multimap 或 multiset 中查找元素
在一个不允许重复关键字的关联容器中查找一个元素是一件很简单的事情——元素要么在容器中,要么不在。但对于允许重复关键字的容器来说,过程就更为复杂:在容器中可能有很多元素具有给定的关键字。
如果一个 multimap 或 multiset 中有多个元素具有给定关键字,则这些元素在容器中会相邻存储。
例如,给定一个从作者到著作题目的映射,我们可能想打印一个特定作者的所有著作。可以用三种不同方法来解决这个问题。最直观的方法是使用 find 和 count :
string search_item("Alain de Botton");//要查找的作者
auto entries = authors.count(search_item);//元素的数量
auto iter = authors.find(search_item) ;//此作者的第一本书
//用一个循环查找此作者的所有著作
while(entries) {
cout << iter->second <<endl; //打印每个题目
++iter;//前进到下一本书
--entries;//记录已经打印了多少本书
}
首先调用 count 确定此作者共有多少本著作,并调用 find 获得一个迭代器,指向第一个关键字为此作者的元素。for 循环的迭代次数依赖于 count 的返回值。特别是,如果 count 返回0,则循环一次也不执行。
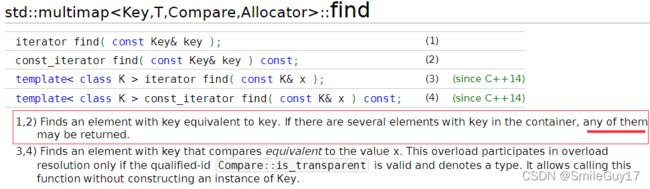
注意:
find并不保证返回相同键值中的固定一个,而是返回其中任何一个。所以上面例子中采用迭代器自增的方法来遍历是错误的做法。 cppreference资料
Note:
当程序员遍历一个
multimap或multiset时,需要保证可以得到序列中所有具有给定关键字的元素。
另一种不同的,面向迭代器的解决方法
我们还可以用有序关联容器的成员函数 lower_bound 和 upper_bound 来解决此问题。这两个操作都接受一个关键字,返回一个迭代器。
如果要查找的关键字存在容器中,
lower_bound返回指向第一个“不小于”给定关键字的元素的迭代器,如果找不到这种元素,则返回尾后迭代器;upper_bound返回指向最后一个匹配给定关键字的元素之后的位置的迭代器。如果找不到这种元素,则返回尾后迭代器。
因此,用相同的关键字调用 lower_bound 和 upper_bound 会得到一个迭代器范围,表示所有具有该关键字的元素的范围(也是左闭合区间)。
当然,这两个操作返回的迭代器可能是容器的尾后迭代器。如果我们查找的元素具有容器中最大的关键字,则此关键字的 upper_bound 返回尾后迭代器。如果关键字不存在,且该关键字大于容器中任何关键字,则 lower_bound 返回的也是尾后迭代器。
Note:
lower_bound返回的迭代器可能指向一个具有给定关键字的元素,但也可能不指向。如果关键字不在容器中,则lower_bound会返回关键字的第一个安全插入点——不影响容器中元素顺序的插入位置。
使用这两个操作,我们可以重写前面的程序:
// authors和search_item的定义,与前面的程序一样 // beg和end表示对应此作者的元素的范围 for (auto beg = authors.lower_bound(search_item), end = authors.upper_bound(search_item); beg != end; ++beg) cout << beg->second << endl; //打印每个题目对
lower_bound的调用将beg定位到第一个与关键字search_item匹配的元素(如果存在的话)。如果容器中没有这样的元素,beg将指向第一个关键字大于search_item的元素,有可能是尾后迭代器。
upper_bound调用将end指向最后一个匹配指定关键字的元素之后的元素。这两个操作并不报告关键字是否存在,重要的是它们的返回值可作为一个迭代器范围。
如果没有元素与给定关键字匹配,则
lower_bound和upper_bound会返回相等的迭代器——都指向给定关键字的插入点,能保持容器中元素顺序的插入位置。
假定有多个元素与给定关键字匹配,beg将指向其中第一个元素。我们可以通过递增beg来遍历这些元素。end中的迭代器会指出何时完成遍历——当beg等于end时,就表明已经遍历了所有匹配给定关键字的元素了。
由于这两个迭代器构成一个范围,我们可以用一个 for 循环来遍历这个范围。循环可能执行零次,如果存在给定作者的话,就会执行多次,打印出该作者的所有项。如果给定作者不存在,beg和end相等,循环就一次也不会执行。否则,我们知道递增beg最终会使它到达end,在此过程中我们就会打印出与此作者关联的每条记录。
Note:
如果
lower_bound返回尾后迭代器,则给定关键字一定不在容器中。
equal_range 函数
解决此问题的最后一种方法是三种方法中最直接的:不必再调用 upper_bound 和 lower_bound ,直接调用所有关联容器的共有成员函数 equal_range 即可。此函数接受一个关键字,并返回一个 pair ,它的两个成员都是迭代器。
- 若关键字存在 ,则第一个迭代器指向首个不小于关键字的元素,第二个迭代器指向最后一个匹配关键字的元素之后的位置。
- 若未找到匹配元素 ,若无元素不小于关键字,则将尾后迭代器作为第一数据成员返回。类似地,若无元素大于关键字,则将尾后迭代器作为第二元素返回。
可以用 equal_range 来再次修改我们的程序:
// authors和search_item的定义,与前面的程序一样 // pos 保存迭代器对,表示与关键字匹配的元素范围 for (auto pos = authors.equal_range (search_item); pos.first != pos.second; ++pos.first) cout<< pos.first->second << endl;//打印每个题目此程序本质上与前一个使用
upper_bound和lower_bound的程序是一样的。
不同之处就是,没有用局部变量beg和end来保存元素范围,而是使用了equal_range返回的pair。此pair的成员first保存的迭代器与lower_bound返回的迭代器是一样的, 成员second保存的迭代器与upper_bound的返回值是一样的。因此,在此程序中, pos.first 等价于beg, pos.second 等价于end。
11.3.6 一个单词转换的 map
我们将以一个程序结束本节的内容,它将展示一个 map 对象的创建、搜索以及遍历。
这个程序的功能是这样的:给定一个
string,将它转换为另一个string。
程序的输入是两个文件:
- 第一个文件保存的是一些规则,用来转换第二个文件中的文本。每条规则由两部分组成:一个可能出现在输入文件中的单词和一个用来替换它的短语。表达的含义是,每当第一个单词出现在输入中时,我们就将它替换为对应的短语。
- 第二个输入文件包含要转换的文本。
如果单词转换文件的内容如下所示:
brb be right back k okay? y why r are u you pic picture thk thanks! 18r later我们希望转换的文本为
where r u y dont u send me a pic k thk 18r则程序应该生成这样的输出:
where are you why dont you send me a picture okay? thanks! later
单词转换程序word_transform
我们的程序将使用三个函数。
- 函数word_transform管理整个过程。它接受两个
ifstream参数:
- 第一个参数应绑定到单词转换文件,
- 第二个参数应绑定到我们要转换的文本文件。
- 函数buildMap会读取转换规则文件,并创建一个
map,用于保存每个单词到其转换内容的映射。- 函数transform接受一个
string,如果存在转换规则,返回转换后的内容。
我们首先定义word_transform函数。最重要的部分是调用buildMap和transform:
void word_transform(ifstream &map_file, ifstream &input)
{
auto trans_map = buildMap(map_file); // 1.store the transformations
//2.
string text; // hold each line from the input
while (getline(input, text)) { // 3.read a line of input
istringstream stream(text); // 4.read each word
string word;
bool firstword = true; // controls whether a space is printed
while (stream >> word) {
if (firstword)//5.
firstword = false;
else
cout << " "; // print a space between words
// 6.transform returns its first argument or its transformation
cout << transform(word, trans_map); // print the output
}
cout << endl; // done with this line of input
}
}
- 函数首先调用buildMap来生成单词转换
map,我们将它保存在trans_map中。 - 函数的剩余部分处理输入文件。
- while循环用
getline一行一行地读取输入文件。这样做的目的是使得输出中的换行位置能和输入文件中一样。 - 为了从每行中获取单词,我们使用了一个嵌套的while循环,它用一个
istringstream来处理当前行中的每个单词。 - 在输出过程中,内层 while循环使用一个
bool变量firstword来确定是否打印一个空格。它通过调用transform来获得要打印的单词。 - transform的返回值或者是word中原来的
string,或者是trans_map中指出的对应的转换内容。
建立转换映射buildMap
函数buildMap读入给定文件,建立起转换映射。
map<string, string> buildMap(ifstream &map_file)//1.
{
map<string, string> trans_map; // 保存转换规则
string key; // 要转换的单词
string value; // 替换后的内容
// 读取第一个单词并存入key中,行中剩余内容存入value
while (map_file >> key && getline(map_file, value))
if (value.size() > 1) // 检查是否有转换规则
trans_map[key] = value.substr(1); // 跳过前导空格
else
throw runtime_error("no rule for " + key);
return trans_map;
}
- map_file中的每一行对应一条规则。每条规则由一个单词和一个短语组成,短语可能包含多个单词。
- 我们用
>>读取要转换的单词,存入key中,并调用非成员函数std::getline读取这一行中的剩余内容存入value。 - 由于getline不会跳过前导空格,需要我们来跳过单词和它的转换内容之间的空格。
- 在保存转换规则之前,检查是否获得了一个以上的字符。如果是,调用成员函数
substr来跳过分隔单词及其转换短语之间的前导空格,并将得到的子字符串存入trans_map。 - 注意,我们使用下标运算符来添加关键字-值对。我们隐含地忽略了一个单词在转换文件中出现多次的情况。如果真的有单词出现多次,循环会将最后一个对应短语存入trans_map。
- 当while循环结束后,trans_map中将保存着用来转换输入文本的规则。
生成转换文本transform
函数transform进行实际的转换工作。其参数是需要转换的 string 的引用和转换规则 map 。如果给定 string 在 map 中,transform返回相应的短语。否则,transform直接返回原 string :
const string &transform(const string &s, const map<string, string> &m)
{
// the actual map work; this part is the heart of the program
auto map_it = m.find(s);//1.
// if this word is in the transformation map
if (map_it != m.cend())//2.
return map_it->second; // use the replacement word
else
return s; // otherwise return the original unchanged
}
函数首先调用 find 来确定给定 string 是否在 map 中。如果存在,则 find 返回一个指向对应元素的迭代器。否则, find 返回尾后迭代器。
如果元素存在,我们解引用迭代器,获得一个保存关键字和值的 pair ,然后返回其数据成员 second ,即用来替代s的内容。
11.4 无序容器
C++11新标准定义了4个 无序关联容器(unordered associative container) 。
无序关联容器不是使用比较运算符来组织元素,而是使用一个 哈希函数(hash function) 和关键字类型的 == 运算符。
虽然理论上哈希技术能获得更好的平均性能,但在实际中想要达到很好的效果还需要进行一些性能测试和调优工作。因此,使用无序容器通常更为简单(通常也会有更好的性能)。
哈希函数是一个函数对象类
如果一个类将
()运算符重载为成员函数,这个类就称为函数对象类,这个类的对象就是函数对象。 函数对象是一个对象,但是使用的形式看起来像函数调用,实际上也执行了函数调用。
比如:class CAverage { public: double operator()(int a1, int a2, int a3) { return (double)(a1 + a2 + a3) / 3; } // 重载()运算符 };
Tip:
如果关键字类型固有就是无序的,或者性能测试发现问题可以用哈希技术解决,就可以使用无序容器。
使用无序容器
除了哈希管理操作之外,无序容器还提供了与有序容器相同的操作( find 、 insert 等)。
因此,通常可以用一个无序容器替换对应的有序容器,反之亦然。 但是,由于元素未按顺序存储,一个使用无序容器的程序的输出(通常)会与使用有序容器的版本不同。
例如,可以用
unordered_map重写最初的单词计数程序:// count occurrences, but the words won't be in alphabetical order unordered_map<string, size_t> word_count; string word; while (cin >> word) ++word_count[word]; // fetch and increment the counter for word for (const auto &w : word_count) // for each element in the map // print the results cout << w.first << " occurs " << w.second << ((w.second > 1) ? " times" : " time") << endl;此程序与原程序的唯一区别是word_count的类型。输出不按照字典顺序进行排列
管理桶
无序容器的要点:
存储形式: 无序容器在存储上组织为一组桶,其中每个桶保存零个或多个元素。无序容器使用一个哈希函数将元素映射到桶。
访问过程: 为了访问一个元素, 容器首先计算元素的哈希值 ,而这个值指出应该搜索哪个桶。
容器将具有一个特定哈希值的所有元素都保存在相同的桶中。如果容器允许重复关键字,所有具有相同关键字的元素也都会在同一个桶中。
因此,无序容器的性能 依赖于哈希函数的质量和桶的数量和大小。
对于相同的参数,哈希函数必须总是产生相同的结果。理想情况下,哈希函数还能将每个特定的值映射到唯一的桶。 但是,将不同关键字的元素映射到相同的桶也是允许的。当一个桶保存多个元素时,需要顺序搜索这些元素来查找我们想要的那个。 计算一个元素的哈希值和在桶中搜索通常都是很快的操作。但是,如果一个桶中保存了很多元素,那么查找一个特定元素就需要大量比较操作。
无序关联容器的元素在内部不以任何特定顺序排序,而是组织到桶中。 元素被放进哪个桶完全依赖于其 关键字 的哈希值。这允许到单独元素的快速访问,因为哈希值一旦被计算出来,则它指代元素被放进的准确的桶。
无序容器提供了一组管理桶的函数,如下表所示。这些成员函数允许我们查询容器的状态以及在必要时强制容器进行重组。
| 在一个关联容器中查找元素的操作 | |
|---|---|
| 桶接口 | |
| c.bucket_count() | 正在使用的桶的数目 |
| c.max_bucket_count() | 容器能容纳的最多的桶的数目 |
| c.bucket_size(n) | 第 n 个桶中有多少个元素 |
| c.bucket(k) | 关键字为 k 的元素在哪个桶中 |
| 桶迭代 | |
| local_iterator | 可以用来访问桶中元素的迭代器类型 |
| const_local_iterator | 桶迭代器的 const 版本 |
| c.begin(n),c.end(n) | 桶 n 的首元素迭代器 |
| c.cbegin(n),c.cend(n) | 与前两个函数类似,但返回 const_local_iterator |
| 哈希策略 | |
| c.load_factor() | 每个桶的平均元素数量,返回 float 值。 |
| c.max_load_factor() | c试图维护的平均比桶大小,返回 float 值。 c 会在需要时添加新的桶,以使得 load_factor<=max_load_factor |
| c.rehash(n) | 重组存储,使得 bucket_count>=n ,且 bucket_count>size/max_load_factor |
| c.reverse(n) | 重组存储,使得 c 可以保存 n 个元素且不必 rehash |
无序容器对关键字类型的需求
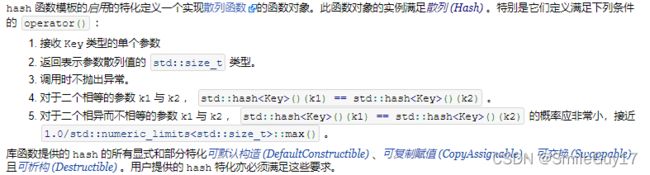
默认情况下,无序容器使用关键字类型的 == 运算符来比较元素。它们还使用一个 hash 类型的对象来生成每个元素的哈希值(其中 Key 是关键字类型)。
由于下面的原因,用户可以直接定义关键字是内置类型(包括指针类型)、 string 还有智能指针类型的无序关联容器:
- C++的标准库为内置类型(包括指针)提供了 hash 模板。还为一些标准库类型,包括
string和智能指针类型(将在12章学习)定义了 hash 。- 标准库的内置类型和一些标准库类型(包括
string和智能指针类型)都定义了==运算符来比较元素。
但是,不能直接定义关键字类型为自定义类类型的无序容器。与其它容器不同,不能直接使用哈希模板,而必须提供用户自己的 hash 模板版本。 后面将在第16章中介绍如何做到这一点。
我们不使用默认的 hash ,而是使用另一种方法:类似于为有序关联容器重载关键字类型的默认比较操作(参见11.2.2节)。为了能将Sale_data用作关键字,我们需要提供函数来替代
==运算符和哈希值计算函数。
我们从定义这些重载函数开始:size_t hasher(const sales_data &sd) { return hash<string>(0)(sd.isbn()); } bool eqOp(const sales_data &lhs,const sales_data &rhs){ return lhs.isbn() == rhs.isbn (); }我们的hasher函数使用一个 标准库
hash类型 对象来计算ISBN成员的哈希值,该hash类型建立在string类型之上。类似的,eqOp函数通过比较ISBN号来比较两个Sales_data。
我们使用这些函数来定义一个unordered_multiset:using SD_multiset = unordered_multiset<sales_data, decltype(hasher)* , decltype(eqOp)*>; // 参数是桶大小、哈希函数指针和相等性判断运算符指针 SD_multiset bookstore(42, hasher, eqOp);为了简化bookstore的定义,首先为
unordered_multiset定义了一个类型别名,此集合的哈希和相等性判断操作与hasher和eqOp函数有着相同的类型。通过使用这种类型,在定义bookstore时可以将我们希望它使用的函数的指针传递给它。
如果我们的类定义了==运算符,则可以只重载哈希函数:// 使用FooHash生成哈希值;Foo必须有==运算符 unordered_set<Foo,decltype(FooHash)*> fooSet(10,FooHash);
重点:
每种无序关联容器都指定了默认的
hash哈希函数和equal_to比较规则 :
- 其中,哈希函数只是一个称谓,其本体并不是普通的函数形式,而是一个函数对象类。因此,如果用户想自定义一个哈希函数,就需要自定义一个函数对象类。而如果要使用自定义的类类型,则默认的
hash哈希函数不再适用。- 默认情况下无序容器使用的
std::equal_to比较规则,其本质也是一个函数对象类,该规则在底层实现过程中,直接用==运算符比较容器中任意 2 个元素是否相等。这意味着,如果容器中存储的元素类型,支持直接用==运算符比较是否相等,则该容器可以使用默认的std::equal_to比较规则;反之,就不可以使用。hash和equal_to都是可调用(Callable)
4个无序关联容器的类模板的前三个参数都是一样的 ,如下:
所以,如果想定义一个关键字类型为用户自定义的类类型的无序容器,只需要满足两个要求:
- 第二参数——定义自己的 hash 规则:
- 传入一个满足
std::hash规则的可调用(Callable)对象
- 第三参数——定义比较规则:
- 重载自定义类类型的
==运算符- 或者,传入一个满足比较的可调用(Callable)对象