对贝叶斯、svm和神经网络的入门级理解
在省略了不少计算、优化的过程的情况下记录了一些自己对一下三个算法整体思路和关键点的理解,因此也只能说是“入门级理解”。以下是目录索引。
贝叶斯
- 朴素贝叶斯
svm支持向量积
神经网络
贝叶斯概率可以用来解决“逆概”问题,“正向概率”问题是指比如说,一个袋子中我们已知有2个白球,3个黑球,那么一次随机摸球活动,我们摸到黑球的概率是多少。但是现实中我们更常见的情况是,事先并不知道里面有多少个什么颜色的球,只知道摸出的某一个球的颜色,由此来猜测的袋中球色分布。这就是“逆概”问题。
贝叶斯公式:P(B|A) = P(AB) / P(A)
P(B|A)后验概率,在已知A发生的情况下B发生的概率
P(AB)联合概率,两件事一同发生的概率
P(A) A的边缘概率,也称先验概率,求解时通过合并无关事件B的概率从而将其消去,回顾一下概率论,在离散函数就是求无关事件B的和,连续函数中就是取B的积分。
就是在事件A发生的情况下,B发生的概率为A、B事件一同发生的概率与A事件单独发生的概率的比值。
贝叶斯公式看起来很简单,但是它是很有用的。举个输入错误判断的例子,如果一个人输入thew,那么我们怎么判断他到底是想输入the还是thaw呢?
A:已近知道的情况,在这里是”输入thew”
B1:猜测一,“想输入的是the”
B2:猜测二,“想输入thaw”
显然这里只需要比较P(AB)
但是P(AB)是什么呢,不好理解,我们再用一次贝叶斯P(AB)=P(B|A)*P(B) 代入,得到P(B|A)=P(A|B)P(B)/P(A)
这里, 关键就是P(B)和P(A|B)了。P(B)理解为这个单词在词库中出现的概率,P(A|B)为想打the却打成thew的似然概率。
显然,the的曝光率应该比thaw的高,而第二个,可以从thew的编辑距离来判断,键盘上,e和w邻近,也就是说,想打the,一不小心多敲一个w的概率非常高,然而,a与e的距离就远了,也就是说,把thaw敲成thew的概率低一点。
朴素贝叶斯,在贝叶斯定理的基础上,粗暴地加上一个非常简单的假设:各属性之间相互独立。举个例子,现在一个事物,有很多特征n1、n2、n3……判断它属于A类还是B类或者CDF,
假设它是A类
P(A|n1,n2,……) = P(n1, n2, ….|A)P(A) / P(n1, n2, …)
分子都是一样的, P(A)是该类的频繁性(其实这里也好理解,一般太特别的情况我们总是延迟考虑嘛),在朴素贝叶斯里面,它觉得,P(n1, n2, ..|A) 就等于P(n1|A)*P(n2|A)*P(n3|A)…..即各个属性相互不影响,这可是一个非常大胆的假设,我们都知道事物之间总是相互联系的嘛。
svm支持向量积
svm是建立在统计学习理论的vc维理论和结构风险最小原理基础上的,根据有限的样本信息在模型复杂度和学习能力之间寻求最佳折中。
下面来一一解释上面这短话。
vc维是对函数类的一种度量,可以简单地理解为问题的复杂程度,vc维越高,问题越复杂。svm关注vc维,也就是说svm解决问题时候也样本维数无关。
误差的积累叫做风险,分类器在样本数据上的分类结果与真是数据的差距就是经验风险。经验风险很低,做其他数据分类是一塌糊涂的情况称为推广能力差,或范化能力差。
统计学习因此引入泛化误差界的概念,指真实风险应该由经验风险和置信风险(代表我们多大程度可以信任分类器的真实分类能力)组成。后者显然无法真实测量,因此只能给出一个区间。置信风险与两个量有关,一是样本数量,量越大,学习结果越可能正确,二是分类函数的vc维,此值越大,推广能力越差。
泛化误差界的公式为:R(w)≤Remp(w)+Ф(n/h)
R(w)为真实风险,Remp(w)是经验风险,Ф(n/h) 是置信风险,统计学习的目标从经验最小化变成了泛化风险最小化,也称,结构风险最小。
小样本,与问题的复杂度相比,svm算法要求的样本数量是比较少的
非线性:svm擅长样本数据线性不可分的情况,主要是通过松弛变量和核函数技术来实现。
高维模式识别:可以处理样本维数很高。
svm从线性可分的最优分类面发展而来,如果数据可以被一个线性模型完全正确地分开,那么数据就是线性可分的。
线性函数,在一维空间是一个点,二维空间是一条直线,三维空间是一个平面,如此想象写去,我们统称为超平面。
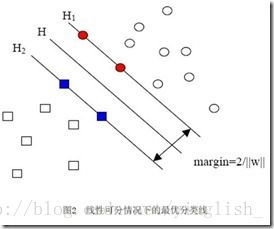
众多的讲解博客都会放类似的这个图,svm就是追求使所分成的类别之间能够有最大的间距。因此它也称为最大边缘分类器
svm是分类问题,假定其分类结果,不是1就是-1,我们的线性方程是 g(x)=w*x+b。假设xi,其类别为yi,如果正确分类,有w*xi+b > 0,又yi>0,则 yi(w*xi+b)>0,同样的,xi不属于该类时,正确判断的情况下会有: yi(w*xi+b)>0。也就是说,正确判断的情况下,yi(w*xi+b)一定大于0,且其值越大,表明分类效果越好(前面强调的,svm寻求最大间距)。那么我们看不可以拿绝对值 |yi(w*xi+b)| 作为衡量依据呢?(在各种算法中,我们总是需要寻找一个方法,来衡量我们当前思路的准确性,并通过对此的调整,以达到优化我们的函数的方法)
事实上我们还需要进一步归一化,在绝对值中,如果我们同时放大w和b,函数不会变化,间距其实也没有改变,但是绝对值会变大。因此,我们让w和b除以 ||w||。得到
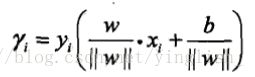
我们称之前的这个为函数间隔:
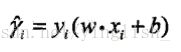
归一化后得到的成为几何间隔:
![]()
在前面那个图中我们看到 maragin=2/||w||
小tip: ||w|| 是什么符号?
||w||叫做向量w的范数,范数是对向量长度的一种度量,我们常说的范数其实是指它的2-范数,范数最一般的表示形式为p-范数,可以写成如下表达式:
向量w=(w1, w2, w3,…wn)
它的p-范数为
||w||与几何间隔称反比,最大化几何间隔其实也就是最小化这个 2/||w|| ,至于为什么不处理分母,我看了很多博客,大抵解释都是“我们常用的方法并不是固定||w||的大小而寻求最大几何间隔,而是固定间隔(例如固定为1),寻找最小的||w||。”,后来,我在一本书上看到:
假定 b1 是类别一中离函数最近的点,b2 属于类别二中离线性函数最近的点,简言之,这两个点在两个平行于决策面的超平面上
b1: w*x1+b=1
b2: w*x2 +b=-1
两式相减,得到 w(x1-x2)=2,即 ||w||*d=2,故间隔为 2 / ||w||
总之,我们要寻找的分类面,它必须使 2/||w|| 最小。之后各种最小化的方法这里就pass掉了。。。。。这篇有很详细的讲解,反正每种算法的过程都总是看得我森森怀疑,大一都干嘛去了,我的线代呢?高数呢?概率论呢?微积分呢?。。。。。
这里写的都只是入门的知识准备,svm处理数据包括线性可分和线性不可分(给定一个数据集,如果存在某个超平面能够将它们完全正确地划分到超平面的两侧,则称数据线性可分),当数据线性不可分时通过核函数使之可分,这些东西比较复杂,有望宝宝日后深究。。。。。。
神经网络
信息分为三大类:输入信息,隐含信息和输出信息
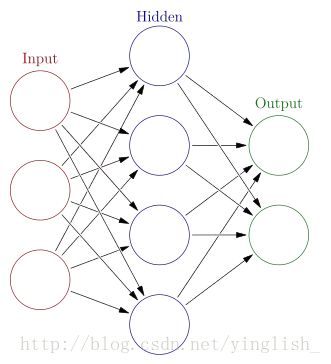
每个神经元,通过某种特定的输出函数,也称激励函数,计算处理来自其他相邻神经元的加权输入值
每个神经元之间信息传递的强度,用所谓加权值来定义,算法会不断自我学习,调整这个加权值
分布式表征,是神经网络研究的一个核心思想。它的意思是,当你表达一个概念时,不是用单个神经元一对一地存储;概念与神经元是多对多的关系,一个概念被分散在多个神经元里,而一个神经元参与多个概念的表达。与传统的局部表征相比,存储效率高,线性增加的神经元数目,可以表达指数级增加的大量不同概念。
此外,它的另一个特点就是,即使局部出现了故障,信息的表达也不会受到根本性的影响。
根据神经元之间的互联方式,常见网络结构有,前馈神经网络,各神经元从输入层开始,接受前一层的输入,并输入到下一级,直到输出层。反馈神经网络:从输出到输入都有反馈连接的神经网络。