3D点云分割系列5:RandLA-Net:3D点云的实时语义分割,随机降采样的重生
RandLA-Net

《RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds》发布于CVPR 2020。
1 引言
在自动驾驶等领域,高效的分割网络是目前最基本和最关键的研究方向。目前存在的一些点云处理方法包括PointNet、PointNet++、PointCNN、KPConv等方法,或多或少都存在效率不高或是特征采样不足的情况,以及输入点云大小存在限制的问题。出现这些问题的原因包括:1. 这些网络的点采样方法计算量大、效率低,比如使用FPS最远点采样算法,十分耗时;2. 局部特征提取器通常依赖于计算量大的核或是图网络的构建,导致无法处理大量的点;3. 大规模点云中通常存在大量的对象,现有的局部特征提取器难以捕获大尺度下的特征,感受野受限。
因此,本文的目标是设计一种内存和计算效率高的神经架构,它能够在单次处理中直接处理大规模 3D 点云,而不需要任何预处理/后处理步骤,例如体素化、块分区或图构建。这就需要
- 一种内存和计算高效的采样方法,以逐步对大规模点云进行下采样以减少GPU内存消耗。
- 一种有效的局部特征学习器以逐步增加感受野大小以保留复杂的几何结构。本文首先系统地证明随机采样(random sampling)是深度神经网络有效处理大规模点云的关键推动因素。但随机采样会丢失关键信息,尤其是对于点云稀疏的对象。为了防止稀疏点关键信息的丢失,提出了一种新的高效局部特征聚合模块(local feature aggregation module)来捕获逐渐变小的点集上的复杂局部结构。
2 RandLA-Net
2.1 采样算法
目前最远点采样( FPS )和逆密度采样(IDIS)常用于小尺度的点云数据,但这两种采样算法的时间复杂度这也成为了网络扩展到大尺度点云的瓶颈之一。作者认为随机抽样(RS)是迄今为止最适合大规模点云处理的采样算法,因为它速度快且可高效扩展。但随机抽样同样容易导致一些问题,因为一些重要的点特征可能会被随机丢弃,导致网络模型没有学习到这些特征,造成模型性能损失。
2.1.1 Random Sampling (RS)
随机抽样算法从原来的 N N N个点中均匀选取 K K K个点。它的计算复杂度为 O ( 1 ) O(1) O(1),与输入点的总数无关,即它耗费的时间是恒定的,因此具有潜在的可扩展性。与 FPS 和 IDIS 相比,无论输入点云的规模如何,随机采样的计算效率最高。处理 1 0 6 10^6 106 个点仅需0.004s。
2.1.2 Farthest Point Sampling (FPS)
为了从具有 N 个点的大规模点云 P 中采样 K 个点,FPS 返回对度量空间{$ {{p_1 ···p_k ···p_K } } KaTeX parse error: Expected 'EOF', got '}' at position 1: }̲的重新排序,使得每个 点p_k$ 是距离前k-1 所有点 { p 1 ⋅ ⋅ ⋅ p k − 1 {p_1 ···p_{k-1}} p1⋅⋅⋅pk−1 } 最远的点。 FPS广泛用于小点集的语义分割。虽然它对整个点集有很好的覆盖,但其计算复杂度为 O ( N 2 ) O(N^2 ) O(N2)。对于大规模点云 (N ∼ 1 0 6 10^6 106 ),FPS 需要 200 秒 才能从 1 0 6 10^6 106个点中采样出合适的输入。这说明FPS不适用于大规模点云。
2.1.3 Inverse Density Importance Sampling (IDIS):
为了从 N N N 个点中采样$ K $ 个点,IDIS 根据每个点的密度对所有 N 个点重新排序,然后选择前 K 个点。其计算复杂度约为 O(N)。根据经验,处理 1 0 6 10^6 106 个点需要 10 秒。与 FPS 相比,IDIS 更高效,但对异常值也更敏感。但对于实时的分割而言,10s的耗费时间显然是过长的。
除了这些之外,还有一些其他的采样算法,如基于生成器的采样算法、基于连续松弛的采样算法、基于策略梯度的采样算法等。但总体而言,随机采样算法是最适合实时点云分割的,因为其计算效率非常高,同时不需要额外的内存来进行计算。
2.2 局部特征聚合Local Feature Aggregation

局部特征聚合模块包含三部分:Local Spatial Encoding(LocSE)、Attentive Pooling、Dilated Residual Block。
2.2.1 Local Spatial Encoding
L o c S e LocSe LocSe模块的输入为一个包含N个点的点云数据,包含了xyz的坐标信息以及d维特征(可以是rgb以及其他特征)。点云中的点会和周围点产生交互,形成有意义的点集,这样LocSE模块就可以聚合这些点的相对空间位置信息,来帮助整体模型有效学习复杂的局部结构。对于某个点 ( p i , f i ) (p_i, f_i) (pi,fi),通过KNN算法收集其K个相邻点 ( p i 1 , p i k , . . . , p i K ) (p_i^1, p_i^k,..., p_i^K) (pi1,pik,...,piK)。
Relative Point Position Encoding
对于点 p i p_i pi的K个相邻点,通过如下公式进行位置编码。
r i k = M L P ( p i ⊕ p i k ⊕ ( p i − p i k ) ⊕ ∥ p i − p i k ∥ ) \mathbf{r}_{i}^{k}=M L P\left(p_{i} \oplus p_{i}^{k} \oplus\left(p_{i}-p_{i}^{k}\right) \oplus\left\|p_{i}-p_{i}^{k}\right\|\right) rik=MLP(pi⊕pik⊕(pi−pik)⊕ pi−pik )
其中, p i p_i pi和 p i k p_i^k pik为x-y-z坐标, ⊕ \oplus ⊕为concatenation, ∥ ⋅ ∥ \left\|·\right\| ∥⋅∥为欧氏距离。
Point Feature Augmentation
对于每个相邻点 p k p_k pk,将编码器的相对位置 r i k r_i^k rik与其对应的点特征 f i k f_i^k fik相连接,得到增强的特征向量 f ^ i k \hat f_i^k f^ik。
最终, L o c S E LocSE LocSE的输出是一组新的相邻特征向量 f ^ i = { f ^ i 1 , f ^ i k , . . . , f ^ i K } \hat f_i = \{{\hat f_i^1, \hat f_i^k,...,\hat f_i^K}\} f^i={f^i1,f^ik,...,f^iK}。这组特征显式编码了中心点 p i p_i pi 的局部几何结构,增强了局部相邻点的特征表示。
2.2.2 Attentive Pooling
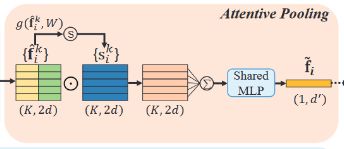
该神经单元用于聚合相邻点特征集合 F ^ i \hat F_i F^i。
Computing Attentive Scores
首先计算注意力分数。给定的输入局部特征集为 F ^ i = { f ^ i 1 , f ^ i k , . . . , f ^ i K } \hat F_i = \{{\hat f_i^1, \hat f_i^k,...,\hat f_i^K}\} F^i={f^i1,f^ik,...,f^iK},设计一个函数 g ( ) g() g()来学习每个特征的注意力分数,通常这个函数使用MLP来代替(激活函数选择SoftMax)。那么输出的注意分数 s i k s_i^k sik的计算公式:
s i k = g ( f ^ i k , W ) s_i^k = g(\hat f_i^k, W) sik=g(f^ik,W)
其中W是MLP的权重。
Weighted Summation
提取的注意力分数可以看做是一个特征的mask,其中对重要特征进行了选择,那么只需要将这个mask与特征本身相乘,即可突出重要特征。
f ~ i = ∑ k = 1 K ( f ^ i k ⋅ s i k ) \widetilde f_i = \sum_{k=1}^{K}{(\hat fi^k \cdot s_i^k)} f i=k=1∑K(f^ik⋅sik)
对于点云 P P P中的一个点 p i p_i pi, L o c S e LocSe LocSe和 A t t e n t i v e P o o l i n g Attentive Pooling AttentivePooling模块将这个点周围的特征和图案进行聚合,最终生成信息丰富的特征向量 f ~ i \widetilde f_i f i。
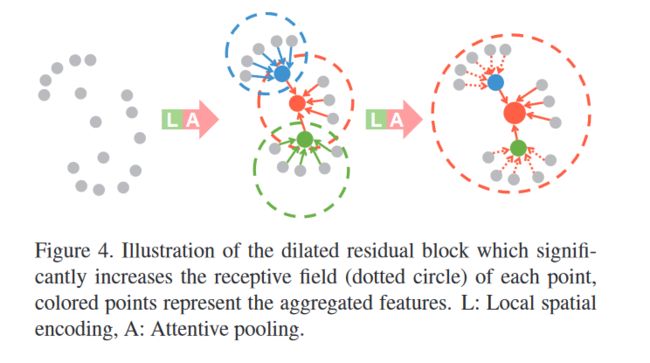
2.2.3 Dilated Residual Block

无论是2D还是3D的场景,残差链接都是必要的。无论是信息传递还是帮助模型拟合,残差模块都能表现出很好的效果。作者这里选择在两个 L o c S E LocSE LocSE和 A t t e n t i v e P o o l i n g Attentive Pooling AttentivePooling之间做残差链接,顾及了时间消耗的模型精度。
总之,局部特征聚合模块旨在通过考虑相邻几何形状和显著增加感受野来保留复杂的局部结构。这些模块只包含了MLP,因此计算效率会比较高。
3 实验
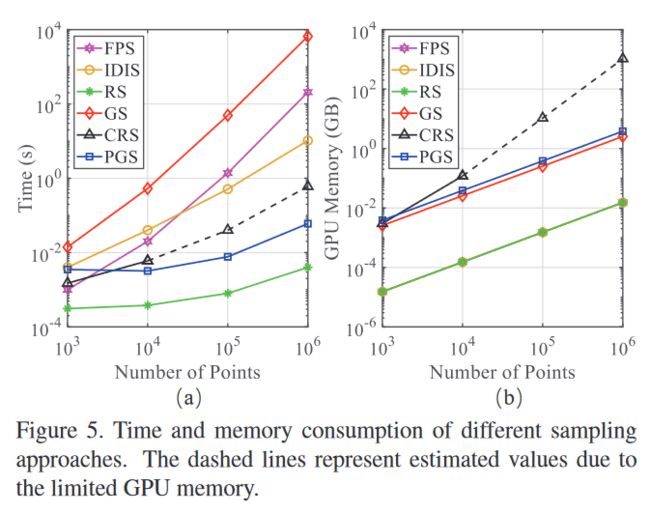
采样效率的影响
作者比较了不同采样方式在时间消耗上的影响。实时证明RS采样方法效率最高,对GPU显存的消耗也最低。
模型效率

消融实验

4 总结
RandLA-Net主要是在实时的3D点云分割方面做了一些贡献和改进,通过采样策略的选择、局部点的特征聚合、残差块的链接、只使用MLP进行计算提升了点云分割模型的效率,同时大大降低了显存消耗。