An Empirical Study on Leveraging Position Embeddings for TOWE 论文阅读笔记
一、作者
Samuel Mensah、Kai Sun
Computer Science Department, University of Sheffield, UK
BDBC and SKLSDE, Beihang University, China
二、背景
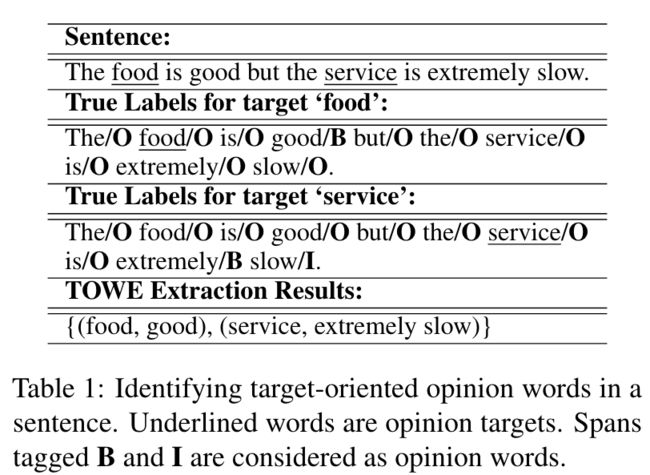
面向目标的意见词提取(TOWE)是面向目标的情感分析的一个新的子任务,旨在为文本中的给定方面提取意见词。
下面分别为数据集示例和为 TOWE 应用 BIO 标签方案的示例。
{
"tokens": ["The", "bread", "is", "top", "notch", "as", "well", "."],
"head": [2, 5, 5, 5, 0, 5, 6, 5],
"POS": ["DT", "NN", "VB", "JJ", "NN", "RB", "RB", "."],
"deprel": ["det", "subj", "cop", "amod", "ROOT", "advmod", "fixed", "punct"],
"asp": [[1, 1]],
"opn": [[3, 4]]
}
三、具体实现
给定句子 s = w 1 , w 2 , ⋯ , w n s = {w_1, w_2, \cdots, w_n} s=w1,w2,⋯,wn,其中方面词为 w t ∈ s w_t \in s wt∈s。作者的模型将单词、词性和位置信息的整体作为 TOWE 任务的输入,进一步探索了通过 GCN 编码器合并来自句子句法解析的信息进而增强文本编码。
1.输入表示
单词嵌入:作者分别通过 Glove 词向量以及基于 BERT 的表示进行实验,其中基于 BERT 的表示是从 BERT 基础模型的最后一层中提取的,并在 TOWE 上进行了微调。
位置嵌入(POSN):作者计算了从 w i w_i wi 到 w t w_t wt 的相对距离 d i d_i di,并在随机初始化的位置嵌入表中查找它们的嵌入。
词性嵌入(POST):作者使用 Stanford Parser 为每个 token 分配了词性标记,并在随机初始化的词性嵌入表中查找它们的嵌入。
输入结合:
- Glove 输入:由连接每个标记的 Glove 词嵌入、POST 和 POSN 嵌入构成。
- BERT 输入:将 BERT 向量与每个 token 的词性嵌入连接起来。
2.文本编码
作者分别基于 CNN、Transformer、BiLSTM 和 ON-LSTM 进行了文本编码的实验。
3.GCN编码器
首先通过二元邻接矩阵 A i j A_{ij} Aij 来对句法树进行表示,即节点间有边对应位置置1,否则置0。
基于句法邻接矩阵,得到的第 k 个 GCN 层的表示为: H ( k ) = ReLU ( A H ( k − 1 ) W ( k ) ) + H ( k − 1 ) H^{(k)}=\operatorname{ReLU}\left(AH^{(k-1)}W^{(k)}\right)+H^{(k-1)} H(k)=ReLU(AH(k−1)W(k))+H(k−1)。
其中, W ( k ) W^{(k)} W(k) 为第 k 层的参数矩阵, ReLU \operatorname{ReLU} ReLU 为对应的激活函数。GCN 的初始输入 H ( 0 ) H^{(0)} H(0) 对应于文本编码器提取的单词表示集合。同时第二项在传播过程中引入了保留了 H ( 0 ) H^{(0)} H(0) 的上下文信息的残差连接。
4.分类和优化
作者的模型使用表示 H ( l ) H^{(l)} H(l),应用线性层,然后使用 softmax 函数对其进行归一化,以得到输入中每个单词在集合 {B, I, O} 上的概率分布。损失函数采用交叉熵损失函数。