【步态识别】GaitEdge超越普通的端到端识别《GaitEdge: Beyond Plain End-to-end Gait Recognition for Better Practicality》
目录
- 1. 论文&代码源
- 2. 论文亮点
- 3. 跨域识别问题
- 4. 框架解读
-
- 4.1 步态合成(Gait Synthesis)
-
- 预处理(Pre-processing)
- 4.2 步态调整模块(Gait Alignment Module)
- 5. 实验结果
-
- 5.1 单域测试
- 5.2 跨域测试
- 5.3 消融实验
-
- 5.3.1 边缘的影响
- 5.3.2 GaitAlign模块的影响
- 5.4 可视化
- 6. 总结
- 0. 知识补充
-
- 0.1 掩膜(Mask)
- 0.2 TTG-200数据集
- 0.3 常用步态数据集对比总结
1. 论文&代码源
《GaitEdge: Beyond Plain End-to-end Gait Recognition for Better Practicality》
论文地址:https://arxiv.org/pdf/2203.03972.pdf
代码下载地址:https://github.com/ShiqiYu/OpenGait
2. 论文亮点
1. 提出RGB噪声的影响:
提出与步态无关的噪声混入对识别产生的影响,引入跨域测试验证RGB信息噪声的泄露,收集得到RGB视频的步态数据集(TTG-200);
2. 对RGB噪声的处理措施:
提出GaitEdge模型,可以有效阻止与识别无关的RGB噪声;
3. 对模型结构的进一步优化:
提出GaitAlign模块,可以对步态剪影进行端到端的尺寸优化。
3. 跨域识别问题
现有的端到端方法能够较好地提高识别性能,但我们很自然地怀疑是因为RGB信息的引入,提高了识别准确率,为了验证这一猜想,作者引入了两种步态识别样例进行实验比较。
关于端到端的概念解释可以参考另一篇博客【步态识别】SMPLGait 算法学习《Gait Recognition in the Wild with Dense 3D Representations and A Benchmark》知识补充0.1 “端到端”概念
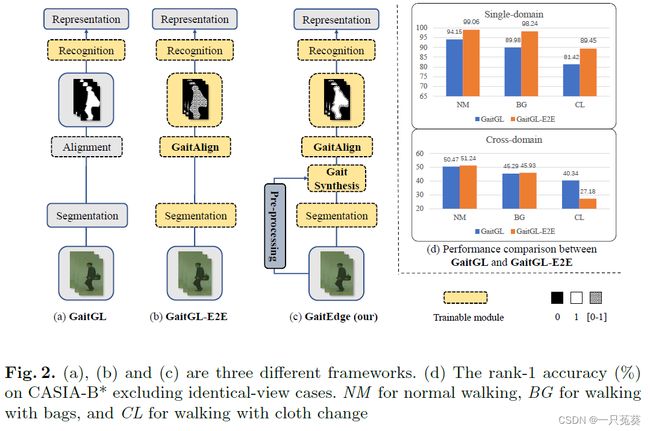
如上图所示, ( a ) (a) (a)是较为经典的两步步态识别方法(非端到端)GaitGL,作者以此作为参考依据; ( b ) (b) (b)是对GaitGL的改进方法,通过可训练的分割网络(U-Net),并使用浮点编码代替二进制掩码,形成一种端到端网络GaitGL-E2E; ( c ) (c) (c)则是本文作者提出的GaitEdge方法,详细信息参见4. 框架解读 。
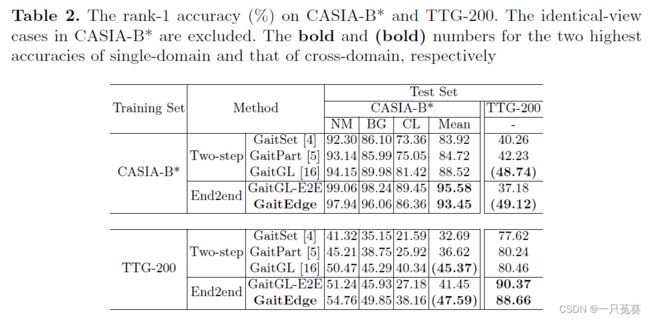
实验分为单域测试和跨域测试两种:单域测试是在CASIA-B数据集上完成模型的训练和测试;而跨域测试是在TTG-200数据集上进行训练,在CASIA-B数据集上进行测试。
如图 ( d ) (d) (d)单域测试结果所示,GaitGL-E2E 的性能优于GaitGL,因为端到端模型具有更多可训练的参数,并且浮点掩码中包含的信息明显要多于二进制掩码 ,但与此同时也引入了另一个问题,也就是浮点掩码可能会把RGB图像中的纹理和颜色一并引入,这样识别网络就学习到与步态无关的信息,从而提高了精准度。
再看图 ( d ) (d) (d)跨域测试结果,GaitGL-E2E 的性能明显下降,这说明在有干扰因素的条件下,端到端识别模型很难较好地处理细粒度信息。
基于以上实验,作者认为 GaitGL-E2E 模型确实在一定程度上吸收了RGB噪声,因此对于具有实际跨域识别要求的步态识别任务变得不再可靠。因而,作者提出了一种新的名为GaitEdge 的模型,它是由 Gait Synthesis 模块和可微的 GaitAlign 模块组成 ,与 GaitGL-E2E 模型最显著的区别是,这一模型通过人为操作剪影的合成来控制RGB信息的传输。
4. 框架解读
4.1 步态合成(Gait Synthesis)
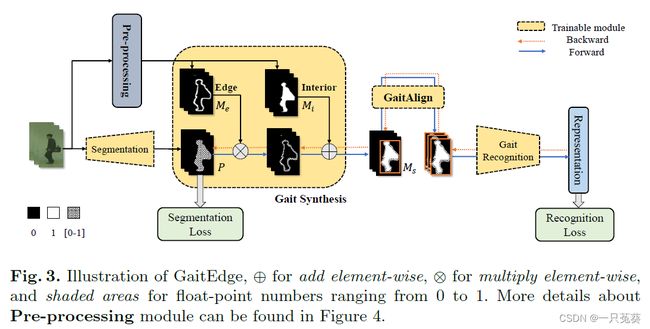
通常认为轮廓边缘是步态图像中最有效的信息,内部则被视为信息较少的低频信息,但如果将内部去掉,信息将过于紧凑而无法进行训练。
关于上面这句话,我的理解是:因为剪影图像的特征主要是依靠边缘的形状,因为内部都是一样的(在此视为低频信息),但是如果只保留边缘图像,我们所能利用的信息就仅仅局限在很小的一个范围内,再通过卷积池化操作,这些信息就很容易被丢失,因而无法达到训练的效果。
因此我们需要在不去除剪影内部的前提下,让网络专注于学习剪影轮廓。
Gait Synthesis通过掩膜操作,将可训练的边缘与固定的内部相结合。它只训练剪影图像的边缘部分,而边缘以外的区域则从冻结的分割网络中提取出来。
如上图所示,黄色块内表示的是可训练的模块,橙色虚线表示反向传播,蓝色实线表示前向传播。边缘和内部的掩码分别表示为 M e M_e Me和 M i M_i Mi;分割网络输出的概率为 P P P;Gait Synthesis的输出为 M s M_s Ms。计算过程可以表示为: M s = M e × P + M i (1) M_s = M_e \times P +M_i \tag1 Ms=Me×P+Mi(1)公式中明确地将 P P P乘以 M e M_e Me并加上 M i M_i Mi,这就阻断了绝大多数的信息(步态相关和不相关的所有信息),但我们可以对剪影边缘进行微调,使其自动优化以便于识别,作者将这一操作成为预处理(Pre-processing)。
预处理(Pre-processing)
通过一个不可训练的预处理得到边缘掩码和内部掩码,具体操作流程如下图所示:
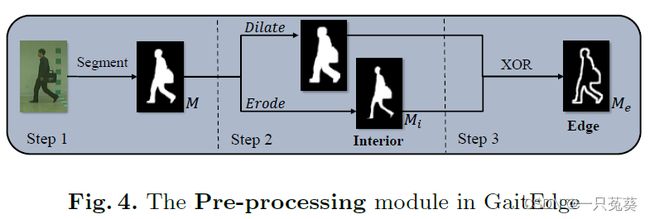
用 训 练 好 的 分 割 模 型 对 R G B 图 像 分 割 , 得 到 轮 廓 M ⇒ 使 用 经 典 形 态 学 算 法 得 到 具 有 3 × 3 平 面 结 构 元 素 的 膨 胀 ( d i l a t i o n ) 和 侵 蚀 ( e r o d e ) 轮 廓 M i ⇒ 通 过 元 素 互 斥 或 ⊻ 得 到 M e 用训练好的分割模型对RGB图像分割,得到轮廓M\\ \Rightarrow 使用经典形态学算法得到具有3 \times 3 平面结构元素的膨胀(dilation)和侵蚀(erode)轮廓M_i \\ \Rightarrow 通过元素互斥或⊻得到M_e 用训练好的分割模型对RGB图像分割,得到轮廓M⇒使用经典形态学算法得到具有3×3平面结构元素的膨胀(dilation)和侵蚀(erode)轮廓Mi⇒通过元素互斥或⊻得到Me计算式为: M i = e r o d e ( M ) M e = M i ⊻ d i l a t e ( M ) (2) M_i = erode(M)\\ M_e = M_i ⊻ dilate(M) \tag2 Mi=erode(M)Me=Mi⊻dilate(M)(2)采用最直观的方式,通过限制可调节区域保留最有价值的轮廓特征,同时消除大部分低级RGB信息噪声,还可以拆卸集成到以前基于轮廓的端到端方法。
4.2 步态调整模块(Gait Alignment Module)
非端到端方法能够在步态剪影图像分割后进行尺寸归一化,这有利于消除噪声,但是端到端方法(如GaitNet)则是将分割后的图像直接送入网络进行处理,因此作者提出了名为 GaitAlign 模块,使身体成为图像的中心,并在垂直方向上填充整个图像,算法代码如下:

5. 实验结果
5.1 单域测试
5.2 跨域测试

5.3 消融实验
5.3.1 边缘的影响
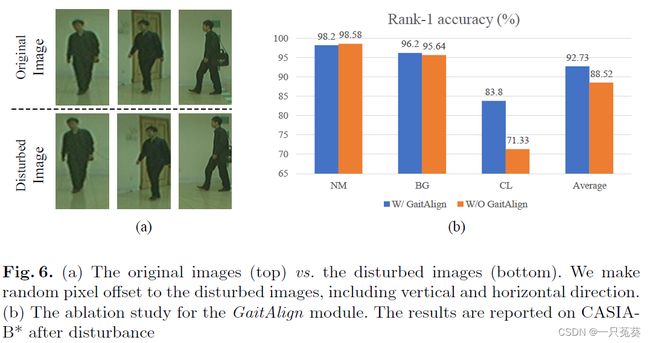
5.3.2 GaitAlign模块的影响

5.4 可视化

6. 总结
本文提出了一个新的端到端步态识别框架,称为GaitEdge,可以解决跨域情况下的识别性能下降问题。具体来说,作者设计了一个步态合成模块(Gait Synthesis),用通过形态学算法得到的可调整的边缘掩盖固定的身体。此外,还提出了步态可调整模块(GaitAlign),以解决由上游行人检测任务引起的身体位置抖动问题。作者在CASIA-B和新建立的TTG-200数据集上进行实验,结果表明GaitEdge明显优于以前的方法,可以有效地阻断RGB噪声,是一种更实用的端到端方法。此外,这项工作暴露了以前的研究所忽视的跨领域问题,为未来的研究提供了一个新的视角。
0. 知识补充
0.1 掩膜(Mask)
图像掩膜用选定的图像、图形或物体,对处理的图像(全局或局部)进行遮挡,来控制图像处理的区域或过程。
掩膜的用法:
- 提取感兴趣区:用预先制作的感兴趣区掩膜与待处理图像相乘,得到感兴趣区图像,感兴趣区内图像值保持不变,而区外图像值都为0;
- 屏蔽作用:用掩膜对图像上某些区域作屏蔽,使其不参加处理或不参加处理参数的计算,或仅对屏蔽区作处理或统计;
- 结构特征提取:用相似性变量或图像匹配方法检测和提取图像中与掩膜相似的结构特征;
- 特殊形状图像的制作。
掩膜操作就是两幅图像之间的各种位运算操作。
0.2 TTG-200数据集
这个数据集是作者团队构建的一个新数据集,其中包含200个在室外行走的受试者,每个受试者需要在6种不同的条件下行走,即是否携带物品、不同穿着、是否接打电话等。在每个行走过程中,受试者将被位于不同视角的12个摄像头捕捉,这意味着每个受试者至多有 6 × 12 = 72 6\times 12=72 6×12=72 个步态序列。

如上图所示,与CASIA-B相比,TTG-200有三个主要区别:
(1) TTG-200的背景更加复杂多样(在多个不同的室外场景中采集);
(2) TTG-200的数据多为鸟瞰图,而CASIA-B的数据多为水平图;
(3) TTG-200的图像质量更好。
0.3 常用步态数据集对比总结
| 数据集 | 受试者数量 | 拍摄环境 | 数据类型 | 变量 | 序列长度 |
|---|---|---|---|---|---|
| CASIA-B | 124 | 室内 | RGB | 11个角度、携带物、衣着 | 13,636 |
| OU-MVLP | 10,307 | 室内 | 剪影 | 14个角度 | 267,388 |
| FVG | 226 | 室外 | RGB | 3个正面视角、行走速度、携带物、衣着、背景 | 2,856 |
| Outdoor-Gait | 138 | 室外 | RGB | 携带物、衣着 | 4,964 |
| GREW | 26,345 | 室外 | 剪影 | 多相机拍摄 | 128,671 |
| TTG-200 | 200 | 室外 | RGB | 12个角度、携带物、衣着、接打电话、背景 | 14,198 |
参考博客:
(ECCV-2022)GaitEdge:超越普通的端到端步态识别,提高实用性
图像中的掩膜(Mask)是什么