Spark SQL dataframe和dataset
目录
一.Spark SQL是什么:
二.Spark SQL 编程 :
三.Spark中的DateFrame是什么?
3.1 DataFrame与RDD的主要区别:
DataFrame 和 RDDs 应该如何选择?
3.2 dataFrame的Schema和Row
3.3 创建DataFrame的方法:
3.4 DataFrame使用SQL语法
3.4.1SQL语法需要临时视图或者全局视图来辅助
3.4.2现在来试试创建全局表:
3.5 DataFrame使用DSL语法
3.7 RDD转换为DataFrame
3.8 在实际开发中,一般通过样例类来将RDD转换为DataFrame
3.9 DataFrame转换为RDD
四.Spark中的DateSet是什么?
4.1 DateSet的特点:
4.2 什么是强类型:
4.3 创建DataSet
4.4 RDD转换为DataSet
4.5 DataSet转换为RDD
五.DataFrame和DataSet区别和互相转换:
5.1 DataFrame和DataSet转换:
5.2 RDD,DataFrame,DataSet三者的关系:
5.2.1 共性:
5.2.2 区别:
5.3 三者的互相转换图:
六.Spark SQL的运行原理
4.1 逻辑计划(Logical Plan)
4.2 物理计划(Physical Plan)
4.3 执行
一.Spark SQL是什么:
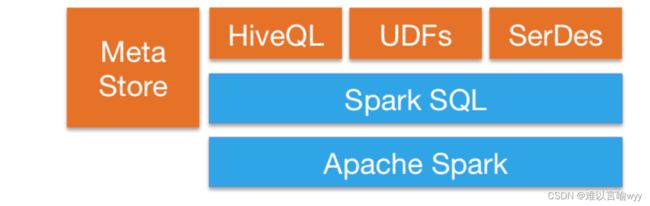
Spark SQL 是 Spark 中的一个子模块,主要用于操作结构化数据。它具有以下特点:
- 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 DataFrame API 对结构化数据进行查询;
- 支持多种开发语言;
- 支持多达上百种的外部数据源,包括 Hive,Avro,Parquet,ORC,JSON 和 JDBC 等;
- 支持 HiveQL 语法以及 Hive SerDes 和 UDF,允许你访问现有的 Hive 仓库;
- 支持标准的 JDBC 和 ODBC 连接;
- 支持优化器,列式存储和代码生成等特性;
- 支持扩展并能保证容错。
二.Spark SQL 编程 :
Spark Core 中,如果想要执行应用程序,需要首先构建上下文环境对象 SparkContext, 而Spark SQL 其实可以理解为对 Spark Core 的一种封装,不仅仅在模型上进行了封装,上下文 环境对象也进行了封装。 在老的版本中,SparkSQL 提供两种 SQL 查询起始点:一个叫 SQLContext,用于 Spark 自己提供的 SQL 查询;一个叫 HiveContext,用于连接 Hive 的查询。 SparkSession 是 Spark 最新的 SQL 查询起始点,实质上是 SQLContext 和 HiveContext 的组合,所以在 SQLContex 和 HiveContext 上可用的 API 在 SparkSession 上同样是可以使用 的。SparkSession 内部封装了 SparkContext,所以计算实际上是由 sparkContext 完成的。当 我们使用 spark-shell 的时候, spark 框架会自动的创建一个名称叫做 spark 的 SparkSession 对象, 就像我们以前可以自动获取到一个 sc 来表示 SparkContext 对象一样
三.Spark中的DateFrame是什么?
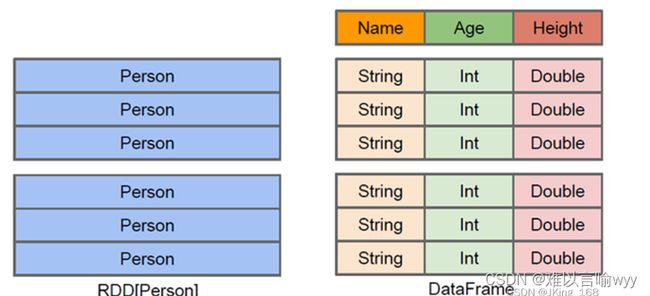
DataFrame=RDD[Person]-泛型+Schema+sql操作+优化
解释一下,就是DataFrame是一种以RDD为基础的分布式数据集,是一种特殊的RDD,是一个分布式的表,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有Schema元信息,即DataFrame所表示的二维表数据集的每一个列都带有名称和类型。
3.1 DataFrame与RDD的主要区别:
DataFrame带有schema(结构表的列名和列的类型),方便Spark SQL得以洞察更多的结构信息,来对藏于DataFrame背后的数据源以及作用与DataFrame之上的变换进行针对性的优化,来提高效率。
RDD因为无法得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单,通用的流水线优化。
DataFrame同hive一样,也支持嵌套数据类型(struct,array,map)
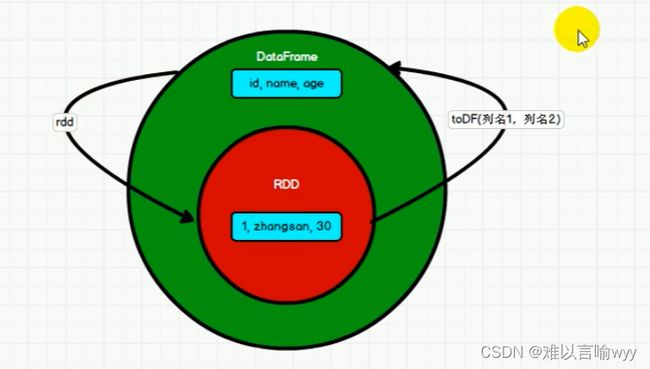
下图就是RDD和DataFrame的区别:
DataFrame 和 RDDs 应该如何选择?
- 如果你想使用函数式编程而不是 DataFrame API,则使用 RDDs;
- 如果你的数据是非结构化的 (比如流媒体或者字符流),则使用 RDDs,
- 如果你的数据是结构化的 (如 RDBMS 中的数据) 或者半结构化的 (如日志),出于性能上的考虑,应优先使用 DataFrame。
注意点:Data也是懒执行的,但是在性能上比RDD要高,主要原因:执行了优化的执行策略,通过使用Spark catalyst optimiser优化。
Spark catalyst optimiser优化:逻辑查询计划优化就是一个利用基于关系代数的等价变换,将高成本的操作替换为低成本操 作的过程。
3.2 dataFrame的Schema和Row
DataFrame中的Schema用大白话来讲,就是结构表的列名于列类型。
他有两种定义方式:
使用 StructType 定义,是一个样例类,属性为 StructField 的数组
使用 StructField 定义,同样是一个样例类,有四个属性,其中字段名称和类型为必填
DataFrame中的row表示为每行数据,DataFrame中每条数据都封装在Row中。
3.3 创建DataFrame的方法:
分为三种:
1.从Spark数据源进行创建
2.从RDD进行转换
3.从Hive Table进行查询返回
以从 Spark数据源进行创建为例:
spark支持的创建文件的数据源格式:
在本地文件中创建一个文件写入信息:
读取该文件创建DataFrame
注意:如果从内存中获取数据,spark 可以知道数据类型具体是什么。如果是数字,默认作 为 Int 处理;但是从文件中读取的数字,不能确定是什么类型,所以用 bigint 接收,可以和 Long 类型转换,但是和 Int 不能进行转换
结果:

3.4 DataFrame使用SQL语法
3.4.1SQL语法需要临时视图或者全局视图来辅助
df.createOrReplaceTempView(“people”) 创建临时表(创建或重写临时表)
df.createOrReplaceGlobalTempView(“people”) 创建全局表(创建或重写全局表)
**注意:**普通临时表是Session范围内的,如果想要应用范围内有效,可以使用全局临时表。使用全局临时表是需要全路径访问,前面加上global_temp. 例如:select * from global_temp.people
步骤:
1.读取JSON文件创建DataFrame
2.对DataFrame创建一个临时表
3.通过SQL语句来实现查询全表
4.结果
注意:普通临时表是 Session 范围内的,如果想应用范围内有效,可以使用全局临时
表。使 用全局临时表时需要全路径访问,如:global_temp.people

3.4.2现在来试试创建全局表:
步骤:
1.对于DataFrame创建一个全局表
2.通过SQL语句实现查询全表

3.5 DataFrame使用DSL语法
DataFrame 提供一个特定领域语言(domain-specific language, DSL)去管理结构化的数据。 可以在 Scala, Java, Python 和 R 中使用 DSL。
使用 DSL 语法可以不用创建临时视图
步骤:
1.创建一个DataFrame
2.查看DataFrame的Schema信息
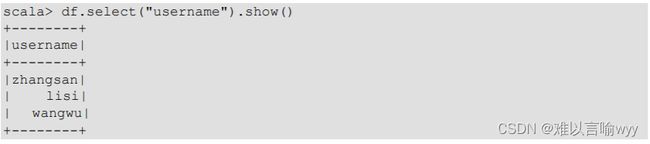
3.设置查看哪一列数据,并且查看它
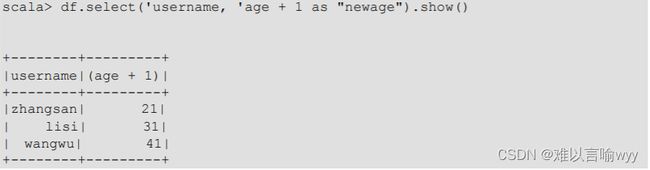
4.在查看username列数据的基础上再加上一个对年龄的计算,使年龄的值都加1
在上面的写法中,我们知道了涉及到运算时,每列都必须使用¥,或者采用引号表达式加上字段名
5.查看年龄大于30的信息
6.按照年龄分组,查看数据条数



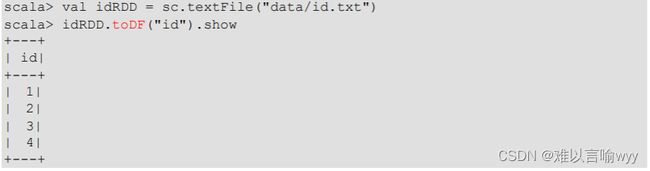
3.7 RDD转换为DataFrame
在 IDEA 中开发程序时,如果需要 RDD 与 DF 或者 DS 之间互相操作,那么需要引入 import spark.implicits._
spark-shell 中无需导入,自动完成此操作。
步骤:
3.8 在实际开发中,一般通过样例类来将RDD转换为DataFrame
衍生:样例类(
Scala中提供了一种特殊的类,用case class进行声明,中文也可以称作“样例类”。样例类是一种特殊的类,经过优化以用于模式匹配。样例类类似于常规类,带有一个case 修饰符的类,在构建不可变类时,Case类非常有用,特别是在并发性和数据传输对象的上下文中。)


3.9 DataFrame转换为RDD
dataFrame可以理解为对RDD的封装,所以可以直接获取内部的RDD

注意:这个里面得到的数据存储类型为Row

四.Spark中的DateSet是什么?
DataSet 是分布式数据集合。DataSet 是 Spark 1.6 中添加的一个新抽象,是 DataFrame 的一个扩展。它提供了 RDD 的优势(强类型,使用强大的 lambda 函数的能力)以及 Spark SQL 优化执行引擎的优点。DataSet 也可以使用功能性的转换(操作 map,flatMap,filter 等等)
4.1 DateSet的特点:
- DataSet 是 DataFrame API 的一个扩展,是 SparkSQL 最新的数据抽象
- 用户友好的 API 风格,既具有类型安全检查也具有 DataFrame 的查询优化特性;
- 用样例类来对 DataSet 中定义数据的结构信息,样例类中每个属性的名称直接映射到 DataSet 中的字段名称;
- DataSet 是强类型的。比如可以有 DataSet[Car],DataSet[Person]。
- DataFrame 是 DataSet 的特列,DataFrame=DataSet[Row] ,所以可以通过 as 方法将 DataFrame 转换为 DataSet。Row 是一个类型,跟 Car、Person 这些的类型一样,所有的表结构信息都用 Row 来表示。获取数据时需要指定顺序
4.2 什么是强类型:
强类型是针对类型检查的严格程度而言的,它指任何变量在使用的时候必须要指定这个变量的类型,而且在程序的运行过程中这个变量只能存储这个类型的数据。因此,对于强类型语言,一个变量不经过强制转换,它永远是这个数据类型,不允许隐式的类型转换。
4.3 创建DataSet
步骤:
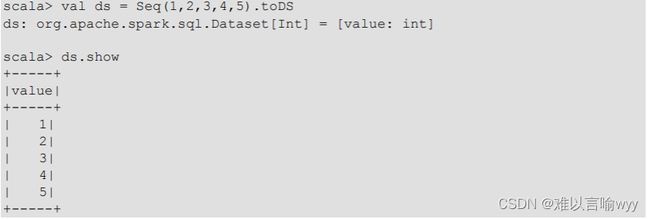
1.使用样例类序列创建DataSet:
2.使用基本类型的序列创建DataSet
注意:在实际使用的时候,很少用到把序列转换成DataSet,更多的是通过RDD来得到DataSet

4.4 RDD转换为DataSet
含有case类的RDD可以通过SparkSQL转换为DataSet

4.5 DataSet转换为RDD
DataSet其实也是对RDD的封装,所以可以直接获取内部的RDD

五.DataFrame和DataSet区别和互相转换:
5.1 DataFrame和DataSet转换:
步骤:
1.DataFrame转换为DataSet
2.DataSet转换为DataFrame


5.2 RDD,DataFrame,DataSet三者的关系:
5.2.1 共性:
RDD、DataFrame、DataSet 全都是 spark 平台下的分布式弹性数据集,为处理超大型数 据提供便利;
三者都有惰性机制,在进行创建、转换,如 map 方法时,不会立即执行,只有在遇到 Action 如 foreach 时,三者才会开始遍历运算;
三者有许多共同的函数,如 filter,排序等;
在对 DataFrame 和 Dataset 进行操作许多操作都需要这个包:import spark.implicits._(在 创建好 SparkSession 对象后尽量直接导入)
三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会 内存溢出
三者都有 partition 的概念
DataFrame 和 DataSet 均可使用模式匹配获取各个字段的值和类型
5.2.2 区别:
- RDD 一般和 spark mllib 同时使用
- RDD 不支持 sparksql 操作
- DataFrame
- 与 RDD 和 Dataset 不同,DataFrame 每一行的类型固定为 Row,每一列的值没法直接访问,只有通过解析才能获取各个字段的值
- DataFrame 与 DataSet 一般不与 spark mllib 同时使用
- DataFrame 与 DataSet 均支持 SparkSQL 的操作,比如 select,groupby 之类,还能 注册临时表/视窗,进行 sql 语句操作
- DataFrame 与 DataSet 支持一些特别方便的保存方式,比如保存成 csv,可以带上表 头,这样每一列的字段名一目了然(后面专门讲解)
- DataSet
- Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同。 DataFrame 其实就是 DataSet 的一个特例 type DataFrame = Dataset[Row]
- DataFrame 也可以叫 Dataset[Row],每一行的类型是 Row,不解析,每一行究竟有哪 些字段,各个字段又是什么类型都无从得知,只能用上面提到的 getAS 方法或者共 性中的第七条提到的模式匹配拿出特定字段。而 Dataset 中,每一行是什么类型是 不一定的,在自定义了 case class 之后可以很自由的获得每一行的信息
5.3 三者的互相转换图:

六.Spark SQL的运行原理
DataFrame、DataSet 和 Spark SQL 的实际执行流程都是相同的:
- 进行 DataFrame/Dataset/SQL 编程;
- 如果是有效的代码,即代码没有编译错误,Spark 会将其转换为一个逻辑计划;
- Spark 将此逻辑计划转换为物理计划,同时进行代码优化;
- Spark 然后在集群上执行这个物理计划 (基于 RDD 操作) 。
4.1 逻辑计划(Logical Plan)
执行的第一个阶段是将用户代码转换成一个逻辑计划。它首先将用户代码转换成
unresolved logical plan(未解决的逻辑计划),之所以这个计划是未解决的,是因为尽管您的代码在语法上是正确的,但是它引用的表或列可能不存在。 Spark 使用analyzer(分析器) 基于catalog(存储的所有表和DataFrames的信息) 进行解析。解析失败则拒绝执行,解析成功则将结果传给Catalyst优化器 (Catalyst Optimizer),优化器是一组规则的集合,用于优化逻辑计划,通过谓词下推等方式进行优化,最终输出优化后的逻辑执行计划。
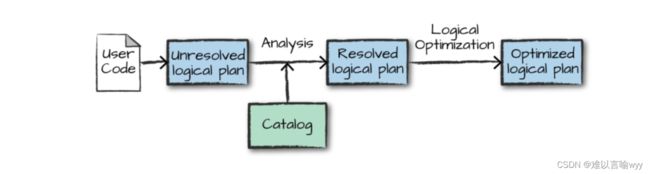
4.2 物理计划(Physical Plan)
得到优化后的逻辑计划后,Spark 就开始了物理计划过程。 它通过生成不同的物理执行策略,并通过成本模型来比较它们,从而选择一个最优的物理计划在集群上面执行的。物理规划的输出结果是一系列的 RDDs 和转换关系 (transformations)。
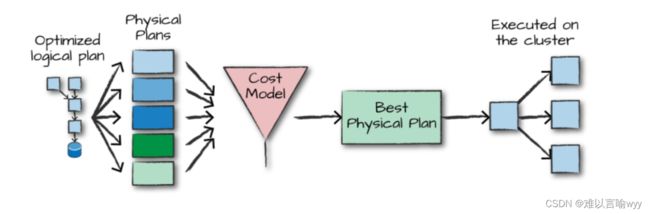
4.3 执行
在选择一个物理计划后,Spark 运行其 RDDs 代码,并在运行时执行进一步的优化,生成本地 Java 字节码,最后将运行结果返回给用户。