Deep Learning 图像分类基础理论学习笔记
目录
一:Transformer 的学习与理解
二:Vision transformer 的学习与理解
三:VGG 的学习与理解
1:VGG亮点
2:感受野(receptive field)的理解及计算
3:VGG网络详解
注意事项:
四:Googlenet的学习与理解
1: Googlenet 亮点
2:inception 模块的理解
3: Googlenet 网络详解
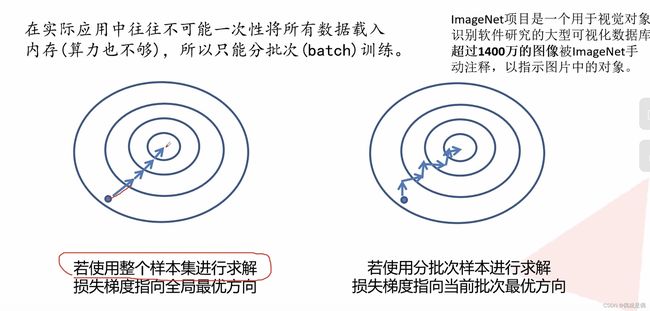
五:卷积神经网络的误差计算及误差反向传播
1:误差计算
2:误差反向传播
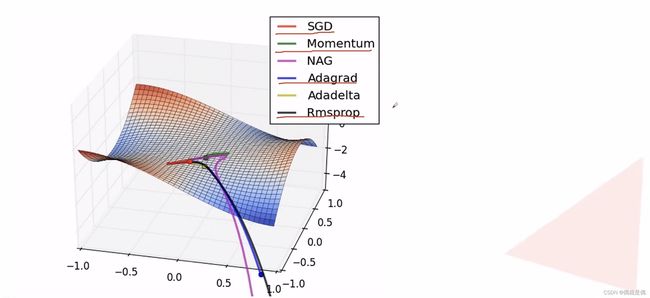
3:权重优化器
1)SGD
2)SGD+Momentum
3)Adagrad
4) RMSProp
5)Adam
六:ResNet的学习与理解
1:Resnet 的亮点
2:Batch Normalization 及迁移学习(transfer learning)的理解
3:ResNet 网络详解
七:MobileNet 网络的学习与理解
八:计算分类模型的混淆矩阵
一:Transformer 的学习与理解

1.attention模块
QK两个向量做内积:若值越大,表示cos值越大,相似度越高。
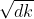 :表示向量的长度。为什么要使用dk, 其实dk不是很大的话除不除都没有关系,但值很大时,softmax的值会更接近1,余下的值会更加靠近0,值向两端靠拢,这样算梯度时,值会比较小,这样梯度比较小。会跑不动(我们希望的是置信的靠近1,不置信的靠近0)
:表示向量的长度。为什么要使用dk, 其实dk不是很大的话除不除都没有关系,但值很大时,softmax的值会更接近1,余下的值会更加靠近0,值向两端靠拢,这样算梯度时,值会比较小,这样梯度比较小。会跑不动(我们希望的是置信的靠近1,不置信的靠近0)
softmax获得权重:1个query,n个key,相乘得到n个值,放入softmax,得到n个非负的且和为1的权重
2.masked 模块
避免看到t时刻及以后得信息,具体是如何实现的呢?
在进入softmax前,输出计算权重的时候:mask把kt_kn及以后的值设为很大的负数,如![]()
softmax之后这个权重便为0
3.multihead模块

通过linear线性投影到低的维度,其中投影的Wi是可以学习到的参数。
二:Vision transformer 的学习与理解
三:VGG 的学习与理解
VGG能用来干嘛? Localization Task (定位任务) 和 Classification Task (分类任务)
paper: Very Deep Convolutional Networks For Large-Scale Image Recognition
1:VGG亮点
通过堆叠多个 3*3 的卷积层来代替一个大的卷积层。
为什么使用多个堆叠的小卷积层代替一个大的卷积层呢?
因为这样可以减少计算的参数:
3个3*3的卷积核 参数:
![]()
1个7*7的卷积核参数:
![]()
2:感受野(receptive field)的理解及计算
概念:输出层中一个单元(小方格)所对应的输入层的区域大小
感受野计算公式:![]()
F(i):第i层感受野
Stride : 第i层的步距
Ksize: 卷积核或池化层尺寸

3:VGG网络详解
原文网络结构 一般常用16层的结构:

最后一个1000的全连接层没有使用RELU 而是使用的softMax函数
注意事项:
我们通常看到别人在搭建VGG网络时,图像预处理的第一步会将图像的RGB分量分别减去[123.68, 116.78, 103.94]这三个参数。这三个参数是对应着ImageNet分类数据集中所有图像的R、G、B三个通到的均值分量。如果你要使用别人在ImageNet数据集上训练好的模型参数进行fine-trian操作(也就是迁移学习)那么你需要在在图像预处理过程中减去这[123.68, 116.78, 103.94]三个分量,如果你是从头训练一个数据集(不使用在ImageNet上的预训练模型)那么就可以忽略这一步。
四:Googlenet的学习与理解
1: Googlenet 亮点
原论文《going deeper with convolutions》
Googlenet 能用来干嘛?图像分类,相较于VGGnet,他的计算参数是VGGnet的1/20,但是其网络的搭建过于复杂,因此大多数情况人们将会采用VGG。
1)引入了inception 结构(融入不同尺度的特征信息)也就是并联的使用了不同大小的卷积核
2)使用1*1 的卷积核进行降维以及映射处理(inception之后要将输出拼接,如果尺寸不一样,无法拼接,
3)添加两个辅助分类器进行帮助训练(两个辅助分类器的输出纬度都是14*14,只是深度不同
4)丢弃了全连接层,采用平均池化层(这也是为什么Googlenet的参数比VGGnet少的原因
2:inception 模块的理解
参数计算公式: ![]()
( 卷积核维度*通道数*卷积核个数)
3: Googlenet 网络详解
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):inception 结构
辅助分类器模块:
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
五:卷积神经网络的误差计算及误差反向传播
1:误差计算

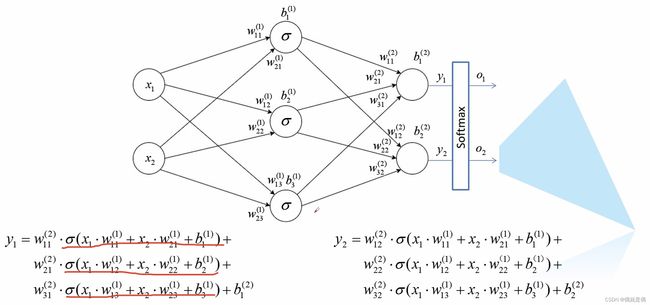


2:误差反向传播

3:权重优化器
1)SGD
2)SGD+Momentum
3)Adagrad
4) RMSProp
5)Adam





六:ResNet的学习与理解
1:Resnet 的亮点
1)超深的网络结构(突破1000层)
2)提出residual模块
3)使用Batch Normalization 加速训练(丢弃dropout)
2:Batch Normalization 及迁移学习(transfer learning)的理解
1)batch normalization
为什么要使用batch normalization?
在卷积层与卷积层之间,上一个卷积层的输出作为下一个卷积层的输入,其输入特征矩阵(feature map)不一定满足某一分布规律,因此通过batch normalization 将其变成均值为0 方差为1 的分布规律。
batch normalization 的工作原理
normalization只能针对每一个batch,如果是整个数据集的计算量太大,但batch越大,越接近数据集分布。

上图的公式可以知道代表着我们计算的feature map每个维度(channel)的均值,注意是一个向量不是一个值,向量的每一个元素代表着一个维度(channel)的均值。代表着我们计算的feature map每个维度(channel)的方差,注意是一个向量不是一个值,向量的每一个元素代表着一个维度(channel)的方差,然后根据和计算标准化处理后得到的值
以batch size=2 为例: 带下标的1代表所有特征的第一个通道的所有数据。 计算这个通道所有数据展平成向量的均值和方差。
feature1 代表第一个卷积核得出的输出结果
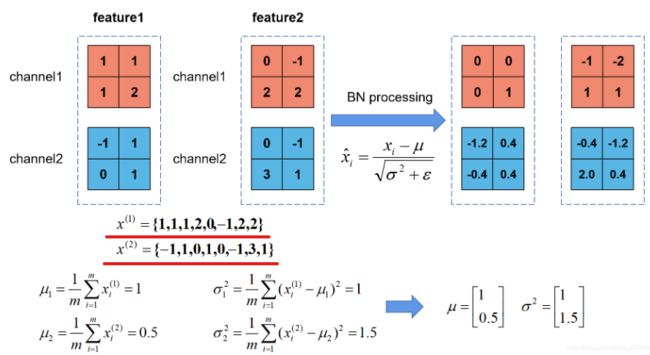
原论文公式中不是还有 ,
, 两个参数吗?是的,是用来调整数值分布的方差大小,是用来调节数值均值的位置。这两个参数是在反向传播过程中学习得到的,的默认值是1,的默认值是0。
两个参数吗?是的,是用来调整数值分布的方差大小,是用来调节数值均值的位置。这两个参数是在反向传播过程中学习得到的,的默认值是1,的默认值是0。
使用BN时需要注意的问题
(1)训练时要将traning参数设置为True,在验证时将trainning参数设置为False。在pytorch中可通过创建模型的model.train()和model.eval()方法控制。
(2)batch size尽可能设置大点,设置小后表现可能很糟糕,设置的越大求的均值和方差越接近整个训练集的均值和方差。
(3)建议将bn层放在卷积层(Conv)和激活层(例如Relu)之间,且卷积层不要使用偏置bias,因为没有用,参考下图推理,即使使用了偏置bias求出的结果也是一样的
2) 迁移学习(Transfer learning)
为什么要使用迁移学习?
1)能够快熟训练处一个理想结果
2)数据小时也可以训练出理想的结果(但要注意别人模型的预处理方式)
迁移学习是如何工作的?
每一个卷积层学习到不同的特征,前面浅层的特征是通用的,所以迁移过来之后对自己的模型只需要训练最后几层参数即可。
迁移学习的方式:
载入权重后训练所有参数
载入权重后只训练最后几层参数
载入权重后在原始网络基础上在添加一层全连接层,仅仅训练最后一个全连接层
3:ResNet 网络详解

Resnet网络的深度很深,但是为什么还有何凯明提出的resnet呢?为什么不能直接简单的通过堆叠形成。主要有下面两个原因。
1:梯度消失或者梯度爆炸(误差梯度小于1,向前传递,越来越小;大于1,越来越大,爆炸)——解决方法:数据标准化,权重初始化,BN来解决
2:退化问题(degradation problem)
残差结构(residual 结构)

 红色标记为卷积核个数
红色标记为卷积核个数
左边输入channel为64,3*3的卷积核,卷积核个数为64。
右边的1*1卷积核是用来降维和升维,因为相加必须维度,深度一样才能相加
参数计算:
右边:![]()
左边:如果输入深度也是256的话: ![]()
通过residual结构可以大大降低计算参数
网络结构:

34层的结构中,其残差结构模块分别重复3、4、6、3次。
conv2_x output size: 56*56*64
conv3_x output size: 28*28*128 这样在利用residual时没法进行相加操作,因此需要把residual中的实线连接变成虚线连接,通过1*1的卷积核进行升维,通过stride=2 进行缩小。
主分支的![]() 这些层的第一层stride都为2,也是为了将图片H W 进行减半处理。并且卷积核个数都依次翻倍。
这些层的第一层stride都为2,也是为了将图片H W 进行减半处理。并且卷积核个数都依次翻倍。
如下图所示:
