【代码笔记】Pytorch学习 DataLoader模块详解
Pytorch DataLoader模块详解
- dataloader整体结构
- DataLoader
-
- init 初始化
-
- 参数解释
- 代码解析
-
- IterableDataset 判断
- 构建Sampler,单样本
- 构建BatchSampler,组建batch
- 构建collate_fn 对获取的batch进行处理
- 其他的一些逻辑判断
- _get_iterator
-
- 代码解析
- multiprocessing_context
- multiprocessing_context
- __setattr__
- __iter__
-
- 代码解释
- _auto_collation
-
- 代码解析
- _index_sampler
- __len__
- check_worker_number_rationality
- _SingleProcessDataLoaderIter
-
- 代码解析
- _BaseDataLoaderIter
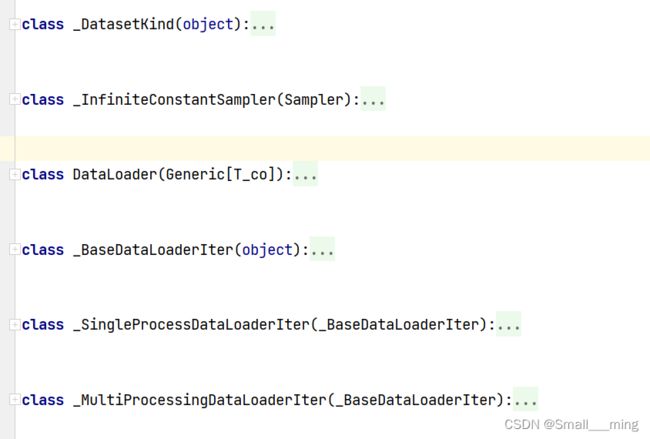
dataloader整体结构
dataloader主要有6个class构成(可见下图)
- _DatasetKind:
- _InfiniteConstantSampler:
- DataLoader:
- _BaseDataLoaderIter:
- _SingleProcessDataLoaderIter:
- _MultiProcessingDataLoaderIter:
DataLoader
我们首先看一下DataLoader的整体结构:
- init:
- _get_iterator:
- multiprocessing_context:
- multiprocessing_context:
- setattr:
- iter:
- _auto_collation:
- _index_sampler:
- len:
- check_worker_number_rationality:
init 初始化
参数解释
这里会把参数全部列出,这里列出的目的是让大家知道各个参数的意义。实际上很多是用不到的,我用加粗字体表示一些常用的参数。
- self:代之Dataset这个类本身
- dataset: Dataset[T_co]是默认值,是你要处理的数据集
- batch_size: Optional[int] = 1, 可选,默认是1。每个batch可以加载batct_size个数据。
- shuffle: bool = False, 每轮训练后是否将数据集打乱
- sampler: Optional[Sampler] = None, 默认是None 自定义方法(某种顺序)从Dataset中取样本,指定这个参数就不能设置shuffle。因为shuffle是打乱数据集的顺序,而sample是以某种顺序取数据,所以二者互斥!sampler可能是获取一整个数据集的数据,是对一整个数据集进行操作,而不是一个batch_size。
- batch_sampler: Optional[Sampler[Sequence]] = None, 返回一个batch的索引,与batch_size, shuffle, sampler, drop_last互斥
传入了batch_sampler,相当于已经告诉了PyTorch如何从Dataset取多少数据,怎么取数据去组成一个mini batch,所以不需要以上参数。可以理解为batch_sampler是batch_size和sampler的结合,所以不需要batch_size, sampler, shuffle, drop_last(因为drop_last也是怎么取数据)。- num_workers: int = 0, 多进程加载数据,默认为0,即采用主进程加载数据
- collate_fn: Optional[_collate_fn_t] = None, 聚集函数,用来对一个batch进行后处理,拿到一个batch的数据后进行什么处理,返回处理后的batch数据。默认源码中进行了若干逻辑判断,仅将数据组合起来返回,没有实质性工作。默认collate_fn的声明是:def default_collate(batch): 所以自定义collate_fn需要以batch为输入,以处理后的batch为输出。类似于transform,transform是对单个数据处理,而collate_fn是对单个batch做处理。
- pin_memory: bool = False, 用于将tensor加载到GPU中进行运算
- drop_last: bool = False, 是否保存最后一个mini batch,样本数量可能不支持被batch size整除,所以drop_last参数决定是否保留最后一个可能批量较小的batch
- timeout: float = 0, 控制从进程中获取一个batch数据的时延
- worker_init_fn: Optional[_worker_init_fn_t] = None, 初始化子进程
- multiprocessing_context=None,
- generator=None,
- prefetch_factor: int = 2, 控制样本在每个进程里的预加载,默认为2
- persistent_workers: bool = False 控制加载完一次Dataset是否保留进程,默认为False
def __init__(self, dataset: Dataset[T_co], batch_size: Optional[int] = 1,
shuffle: bool = False, sampler: Optional[Sampler] = None,
batch_sampler: Optional[Sampler[Sequence]] = None,
num_workers: int = 0, collate_fn: Optional[_collate_fn_t] = None,
pin_memory: bool = False, drop_last: bool = False,
timeout: float = 0, worker_init_fn: Optional[_worker_init_fn_t] = None,
multiprocessing_context=None, generator=None,
*, prefetch_factor: int = 2,
persistent_workers: bool = False):
代码解析
在DataLoader的__init__函数里,我们可以看到,它实现了:
- 判断是否是IterableDataset类型,如果是需要进一步判断参数是否正确
- 构建Sampler,单样本
- 构建BatchSampler,
- 组建batch 构建collate
- 其他的一些逻辑判断
IterableDataset 判断
- IterableDataset应用于数据集非常大,将其完全加载进内存不现实(例如高达几个TB的数据),这时就需要IterableDataset构建可迭代的Dataset类,自定义的Dataset需要继承自torch.util.data.IterableDataset,重写__iter__方法,返回可迭代对象(通常是yield生成器)
- 对于IterableDataset来说,就没有构建采样器Sampler的需求,因为样本是通过调用__iter__一个个读取出来的。执行封装的DataLoader传进去的batch_size次__iter__方法,就获取到一个mini batch
# 判断dataset是否是IterableDataset类型
if isinstance(dataset, IterableDataset):
self._dataset_kind = _DatasetKind.Iterable
# 按照__iter__获取数据,所以不需要打乱
if shuffle is not False:
raise ValueError(
"DataLoader with IterableDataset: expected unspecified ""shuffle option, but got shuffle={}".format(shuffle))
elif sampler is not None:
# 按照__iter__获取数据,也不再需要sampler获取数据
raise ValueError("DataLoader with IterableDataset: expected unspecified ""sampler option, but got sampler={}".format(sampler))
elif batch_sampler is not None:
# 按照__iter__获取数据,也不再需要batch_sampler获取数据索引
raise ValueError("DataLoader with IterableDataset: expected unspecified " "batch_sampler option, but got batch_sampler={}".format(batch_sampler))
else:
self._dataset_kind = _DatasetKind.Map
构建Sampler,单样本
if sampler is None: # give default samplers
if self._dataset_kind == _DatasetKind.Iterable:
# 如果是Iterable的Dataset,就采用迭代的方式获取sampler
sampler = _InfiniteConstantSampler()
else: # 否则判断是否使用shuffle,使用则随机产生sampler,不使用就按照顺序产生sampler
if shuffle:
sampler = RandomSampler(dataset, generator=generator)
else:
sampler = SequentialSampler(dataset)
构建BatchSampler,组建batch
- 注意,上面说batch_sampler不能和batch_size、sampler、drop_last同时使用是指:如果已经定义了batch_sampler则与batch_size和sampler互斥!!!前提是已经定义了batch_sampler!!!但是如果没有定义batch_sampler,则可以通过batch_size,sampler,dorp_last来组建batch!!!
# 要取batch_size个sampler,但是还没有取,即batch_sampler==None
if batch_size is not None and batch_sampler is None:
# 获取batch_size个sampler个索引
batch_sampler = BatchSampler(sampler, batch_size, drop_last)
构建collate_fn 对获取的batch进行处理
if collate_fn is None:
if self._auto_collation:
# 默认的实际上什么也没干
collate_fn = _utils.collate.default_collate
else:
collate_fn = _utils.collate.default_convert
其他的一些逻辑判断
# sampler 不能和 shuffle 同时出现
# 因为shuffle是将数据打乱,而sampler是按照某一顺序获取数据
if sampler is not None and shuffle:
raise ValueError('sampler option is mutually exclusive with ''shuffle')
if batch_sampler is not None:
# batch_sampler不能和batch_size,shuffle,sampler,drop_last同时使用。
# batch_sampler可以理解为batch_size和sampler的结合
if batch_size != 1 or shuffle or sampler is not None or drop_last:
raise ValueError('batch_sampler option is mutually exclusive ''with batch_size, shuffle, sampler, and ' 'drop_last')
batch_size = None
drop_last = False
elif batch_size is None:
# batch_size为None,默认是1,如果drop_last为True就会舍弃最后一个,这样数据就会减少。(构成了一个batch但是仍然舍弃掉)
if drop_last:
raise ValueError('batch_size=None option disables auto-batching ''and is mutually exclusive with drop_last')
self.collate_fn = collate_fn
self.persistent_workers = persistent_workers
self.__initialized = True
self._IterableDataset_len_called = None # See NOTE [ IterableDataset and __len__ ]
self._iterator = None
self.check_worker_number_rationality()
torch.set_vital('Dataloader', 'enabled', 'True') # type: ignore[attr-defined]
_get_iterator
代码解析
def _get_iterator(self) -> '_BaseDataLoaderIter':
if self.num_workers == 0:
# 单线程
return _SingleProcessDataLoaderIter(self)
else:
# 多线程
self.check_worker_number_rationality()
return _MultiProcessingDataLoaderIter(self)
multiprocessing_context
multiprocessing_context
setattr
iter
代码解释
# 其中 -> '_BaseDataLoaderIter' 是函数注释,运行时跟没有加注解之前的效果也没有任何差距。
# 主要作用是提醒程序猿这里应该是 '_BaseDataLoaderIter'的数据类型
def __iter__(self) -> '_BaseDataLoaderIter':
if self.persistent_workers and self.num_workers > 0:
if self._iterator is None:
self._iterator = self._get_iterator()
else:
self._iterator._reset(self)
return self._iterator
else:
return self._get_iterator()
_auto_collation
代码解析
@property
def _auto_collation(self):
# 根据batch_sampler判断是否设置_auto_collation
return self.batch_sampler is not None
_index_sampler
len
check_worker_number_rationality
_SingleProcessDataLoaderIter
代码解析
def __init__(self, loader):
super(_SingleProcessDataLoaderIter, self).__init__(loader)
assert self._timeout == 0
assert self._num_workers == 0
self._dataset_fetcher = _DatasetKind.create_fetcher(
self._dataset_kind, self._dataset, self._auto_collation, self._collate_fn, self._drop_last)
def _next_data(self):
# 获取索引
index = self._next_index() # may raise StopIteration
# 获取数据
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
if self._pin_memory:
data = _utils.pin_memory.pin_memory(data)
# 返回数据
return data
_BaseDataLoaderIter
__next__方法会调用_next_data,_next_data获取一个batch的数据