Vue源码解析之虚拟DOM和diff算法学习笔记+面试考点及回答+问题及解决+心得体会及总结+snabbdom的JS版本(阉割)
前提摘要:
文章内源码和图片多来自【尚硅谷】Vue源码解析之虚拟DOM和diff算法,文章偏向总结以及理解虚拟DOM和diff算法,偏个人笔记项,希望能够帮助在学的朋友理解,所以并非每步都有展现,若需要请参考B站尚硅谷老师视频下置顶评论,YK菌的笔记非常适合从0开始看
0.面试考点及回答:(仅供参考,若有错,感谢指出)
1.什么是虚拟DOM
虚拟DOM是将真实DOM的属性组合成对象的形式进行返回,主要有sel、data、children、text、elm、key属性分别是sel代表标签名、data里面是一些属性值,比如a标签的href属性,img标签的src属性等等、children是他的子节点(们)、text存放的是他的文本属性,比如h1标签的text是"这是一个标题"、elm存放的是该虚拟节点的真实DOM,一般在虚拟节点传换成真实DOM的时候会将生成的DOM节点赋值给elm属性、key是他的唯一标识,用于最小量更新等。
还看到过另一种说法是分为标签名( tag)、属性(attrs)和子元素对象( children)三个属性(这种我未做过大了解)
2.什么时候会进行diff比较:
这里主要是根据以下几点判别:
①同一节点才能进行diff算法比较,同一节点的定义是选择器和key值都相等
②即使是同一节点,但是未指定key值,如果顺序的话是可以进行最小量更新,但是一旦逆序或者打乱顺序,diff就会全部重建(感受diff算法第一个例子的情况②就是这样),所以同一节点需要指定key作为唯一标识,告诉diff他们是同一个节点,否则也会暴力拆迁。
③只进行同层比较,不能进行跨层比较,当比较元素内新增一层嵌套结构,例如div下多了一个section结构,即便是最内侧子节点都一样也无法进行比较了,因为跨层了。
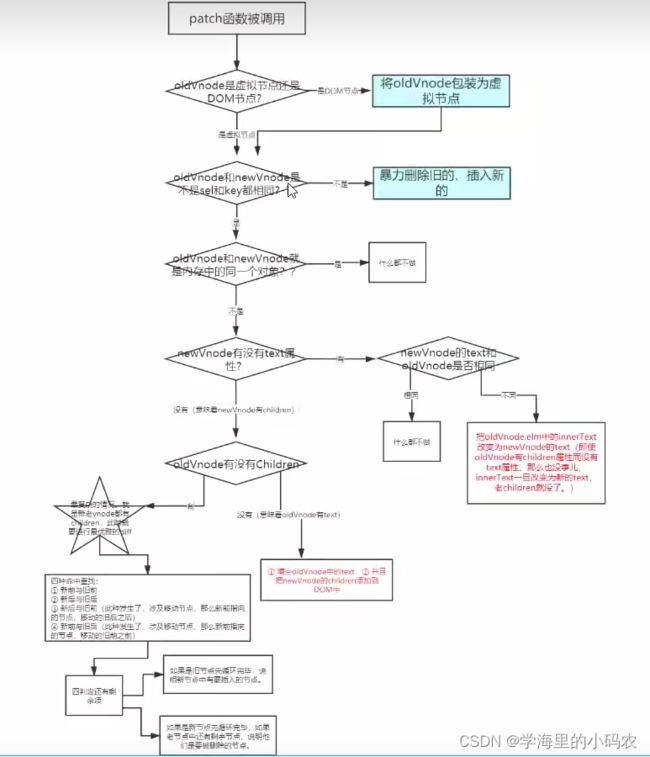
3.diff具体实现步骤有哪些?(当初面试时候就没答上来0.0)【参考文章最底部流程图方便理解】
首先,patch函数会被调用,当patch函数被调用的时候,需要比较oldVnode(旧节点)和newVnode(新节点)是否是同一个节点,主要是通过比较他们sel和key值,如果相同即可进行diff精细化比较,否则暴力删除旧的,插入新的,但是如果旧节点是DOM节点,我们需要先将他包装成虚拟节点,通过Vnode函数将其包装成虚拟节点,然后进行比较,如果sel和key都相同就进行diff,如果diff新旧节点没有任何改变就什么都不做,以text文本为例,如果text发生变化,那么新节点的innerText属性就会替代旧节点的text属性,如果是单属性的改变其实并不难判断,但是如果涉及children这种复杂属性的比较就会进行执行diff算法的四种命中比较,四种命中分别是:新前和新后(新前节点和新后节点)、新后和旧后、新后和旧前、新前和旧后比较,值得注意的是这里顺序执行的,由updateChildren代码处可见,他们共同放在一个while()函数中执行,while的条件是oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx,意思就是当旧前指针达到旧后指针位置或者新前指针到达新后指针位置处即需要终止判断,说明新节点或者旧节点已经循环完成了,但是while条件下除了四种命中以外还依旧存在其他可能,那么此时只会比较新前指针位置处的新前节点,需要拿他去和旧节点中的每一项循环比较,为了提升比较的速度,这里一般会采用map映射的方式,map的key也就是属性名为对应旧节点对应的key值(也就是就节点的唯一标识符),value也就是属性值设置为旧节点的index(方便确认节点的位置,为后续将虚拟节点赋值成undefined服务),如果不存在则证明是新加入的项,需要插入到旧前节点的前面,如果存在,则正面位置发生了变化,需要进行移动节点操作,移动节点依旧是插入到旧前节点的前面,但是与前面不同的是此时需要为对应旧节点中设置undefined值,这样做的目的是告诉diff算法,这里我们已经做过处理了,这个节点在新节点中有对应节点。除此之外依旧还存在两种情况,但是这两种比较容易理解,分别是while循环语句结束的时候,oldStartIdx还是
PS:
目前由于水平有限,组织表达可能不够通俗易懂,或者可能有错误,随着水平和理解提升,会定期修改回答结果
1.感受diff算法:
diff算法主要是通过patch实现,目的是就说实现最小量更新,减小开销
情况①:
顺序增加,但不指定key值
import {
init,
classModule,
propsModule,
styleModule,
eventListenersModule,
h,
} from "snabbdom";
const patch = init([classModule,propsModule,styleModule,eventListenersModule])
// import { h } from "./mysnabbdom/h";
const container = document.getElementById("container")
const vnode1 = h('ul',{},[
h('li',{},'A'),
h('li',{},'B'),
h('li',{},'C'),
h('li',{},'D')
])
patch(container,vnode1);
const vnode2 = h('ul',{},[
h('li',{},'A'),
h('li',{},'B'),
h('li',{},'C'),
h('li',{},'D'),
h('li',{},'E')
])
var btn = document.getElementById("btn")
//点击按钮是,将vnode1改成vnode2
btn.onclick = function(){
patch(vnode1,vnode2);
}
这样通过点击按钮,就会发现多出了E这个节点,并且通过控制台修改原ABCD值内容如下图

结果的确如此,能够按照预期添加

情况②:
不指定key值,但是逆序增加

结果没有按照预期,而是重新构建了所有元素,实际上他进行的步骤是,将A改成E,B改成A,依次到底,最后添加D,所以是重建了

情况③:
逆序,但是在h函数为其指定key属性值作为唯一标识

结果按照预期产生,没有进行重建

由此可以总结:
①最小量更新的确厉害,但是为了方便比较最好添加唯一标识key,告诉diff算法,元素在更改前后依旧是同一个结点
2.当h函数中的ul改成ol后,即使内部全都添加了关键词依旧无法进行精细化比较
const vnode1 = h('ul',{},[
h('li',{key:'A'},'A'),
h('li',{key:'B'},'B'),
h('li',{key:'C'},'C'),
h('li',{key:'D'},'D')
])
patch(container,vnode1);
const vnode2 = h('ol',{},[
h('li',{key:'A'},'A'),
h('li',{key:'B'},'B'),
h('li',{key:'C'},'C'),
h('li',{key:'D'},'D'),
h('li',{key:'E'},'E')
])

其实这个挺好理解,虚拟节点不一样,自然不会比较了,如何定义是不是同一个节点,当选择器和key都相等的时候才能说是同一节点,
const vnode1 = h('ul',{key:'0216'},[]}
const vnode2 = h('ul',{key:'0216'},[])
// vnode1和vnode2的选择器都是ul,并且key值都是0216,可以进行diff比较2.1 当新旧节点类型不同的时候,例如代码片段2.1,container是DOM节点,而vnode1是虚拟节点,这个时候如流程图2.1所示,如果不是虚拟节点无法进行比较,需要包装成虚拟节点然后比较key值和选择器,判断方法如代码片段2.2所示,代码为ts代码:冒号后的是变量类型,如果相同才继续比较,否则暴力拆解
patch(container,vnode1);代码片段2.1
function sameVnode(vnode1:VNode,vnode2:Vnode):boolean {
return vnode1.key == vnode2.key && vnode1.sel == vnode2.sel
}代码片段2.2

流程图2.1(来源尚硅谷)
总结:
①同一节点才能进行diff算法比较,同一节点的定义是选择器和key值都相等
3.当h函数中多嵌套一个层级,内部元素能够进行最小量更新吗?
const vnode1 = h('div',{key:'0216'},[
h('p',{key:'A'},'A'),
h('p',{key:'B'},'B'),
h('p',{key:'C'},'C'),
h('p',{key:'D'},'D')
])
patch(container,vnode1);
const vnode2 = h('div',{key:'0216'},h('section',{},[
h('p',{key:'A'},'A'),
h('p',{key:'B'},'B'),
h('p',{key:'C'},'C'),
h('p',{key:'D'},'D')
]))

从代码运行结果可知,即使父元素选择器和key值相同的情况下,嵌套多一层结构,diff依旧是重新构建了元素
总结:
①只进行同层比较,不能进行跨层比较
最终总结:(详细请看上述)
①最小量更新,最好指定为其指定key值,这样即使乱序也能实现最小量更新
②同一节点才能进行diff算法比较,同一节点的定义是选择器和key值都相等
③只进行同层比较,不能进行跨层比较
2.问题及解决:
2.1配置简易开发环境:
①npm i -D webpack@5 webpack-cli@3 webpack-dev-server@3安装依赖失败:
先
npm i webpack-cli@3完成后再
npm i webpack-dev-server@3最后通过
npm i -D webpack@5完成安装。解决问题来源:评论区用户:えいえんな,在此非常感谢!
2.2JavaScript中的函数重载:
函数重载是一个同名函数完成不同的功能,根据传入参数的不同,使用不同执行方法,与传入的参数类型和参数个数相关,能够接受的类型越多,重载的功能就越强大,最后通过return返回值来区分调用的是哪一个函数。
**JavaScript 中没有真正意义上的函数重载
**原因: 重载是面向对象语言里很重要的一个特性,JavaScript 中没有真正的重载,是模拟出来的(因为JavaScript 是基于对象的编程语言,不是纯面向对象的,它没有真正的多态:如继承、重载、重写),本质原因是声明创建同名函数JS中默认覆盖。
h('div')
h('div','文字')
h('div',[])
h('div',h())
h('div',{},[])
h('div',{},'文字')
h('div',{},h())2.3低级错误:
报错类型:
index.js:15 Uncaught TypeError: (0 , _mysnabbdom_h__WEBPACK_IMPORTED_MODULE_0__.h) is not a function
错误写法:
import {h} from "./mysnabbdom/h";改正:
import h from "./mysnabbdom/h";原因:
由于导入文件export default 这种导出方式如代码片段6.6,并未对方法进行命名,所以导出的名称交给了导入这,我们可以之间通过import h from "./mysnabbdom/h";导入即可,相反如果加上{h}代表在这个模块中找到export 暴露出的h方法的函数,由于文件内并没有暴露这种函数所以报错,由此我们引出了另一种解决错误的方法,如代码片段6.7,我们为导出的方法命名为h函数,即可通过import {h} from "./mysnabbdom/h";方式引入也可
总结:
如果引入的方法使用export default 无需加花括号,如果导入模块有非常多的方法,我们可以按需导入需要的方法,比如Vue项目中常用的按需导入如代码片段6.5,当然如果导入方法与其他地方重合或者不方便记忆或者书写也可以通过as语句进行重命名使用如代码片段6.4
import {studentList as ms } from 'studentList'代码片段6.4
import { defineComponent, onMounted, reactive, ref, getCurrentInstance,nextTick } from 'vue'代码片段6.5
export default function(sel,data,c){
...
}代码片段6.6
export function h(sel,data,c){
...
}
//这样的话就能通过{h}方式导入3.心得体会及总结:
学习了虚拟DOM和diff算法后,了解到什么是虚拟DOM了,虚拟DOM其实就是将真实DOM中属性转换成对象形式存储,这样的目的也很明了,其实就是为了diff算法做比较,而且转换成对象方便我们数据进行操作,而且由于操作的是虚拟DOM而不是真实DOM,开销会非常小,虚拟DOM的转换主要用到了h函数,他的作用就是创建虚拟节点,虚拟节点的数据会以对象的形式存储返回,再进行一系列diff后,然后需要用到createElement函数,也就是根据虚拟节点的属性创建真实的DOM,后会通过patch函数根据不同情况,是否符合最小量更新条件的情况进行节点的上树操作,也就是转换成真实的页面DOM元素;diff算法的主要作用就是进行节点之间的比较,比较新旧虚拟节点中是否存在相同的项,存在则进行patchVnode最小量更新,如果不存在则创建新的节点,这里值得注意的是,diff比较是虚拟节点,而不是真实DOM元素,diff比较的时候需要传入key关键词作为唯一表示,如果不传会怎么样呢?
根据代码3.2处实例结合3.1处代码分析可知,判断是否是同一节点的条件就是看新旧节点sel和key属性是否相同,由于都是li标签,sel都是li,缺乏key唯一标识,所以每次都能进行第一命中如图3.3和3.4所示,看似是最小量更新结果,其实每个值都被修改了,也就违背了最小量更新原则,如果是最小量更新文字就不会消失,因为最小量更新的结果其实只是移动节点,并非去拆除重建,这体现了key值得重要性,也是为什么开发得时候v-for需要传入唯一标识,就是为最小量更新diff服务的。
function checkSameVnode(a,b){
return a.sel == b.sel && a.key == b.key
}
// 开始四次命中判断
// 新前和旧前
if (checkSameVnode(oldStartVnode,newStartVnode)){
console.log("1新前和旧前命中")
patchVnode(oldStartVnode,newStartVnode)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
}else
// 新后和旧后
if (checkSameVnode(oldEndVnode,newEndVnode)){
console.log("2新后和旧后命中")
patchVnode(oldEndVnode,newEndVnode)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
}else
// 新后与旧前
if (checkSameVnode(oldEndVnode,newEndVnode)){
console.log("3新后和旧前命中")
patchVnode(oldStartVnode,newEndVnode)
//当3新后与旧前命中的时候,此时要移动节点。移动新前指向的这个节点到老节点的旧后的后面
parentElm.insertBefore(oldStartVnode.elm,oldEndVnode.elm.nextSilbling)
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
}else
// 新前与旧后
if (checkSameVnode(oldEndVnode,newStartVnode)){
console.log("4新前和旧后命中")
patchVnode(oldEndVnode,newStartVnode)
//第四种情况需要移动节点,移动新前到旧前的前面
parentElm.insertBefore(oldEndVnode.elm,oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} 3.1
var myVnode1 = h('ul',{},[
h('li',{},'A'),
h('li',{},'B'),
h('li',{},'C'),
h('li',{},'D'),
h('li',{},'E'),
])
var myVnode2 = h('ul',{},[
h('li',{},'E'),
h('li',{},'C'),
h('li',{},'D'),
h('li',{},'A'),
h('li',{},'B'),
])3.2
3.3

3.4
4.snabbdom的JS版本(阉割版)
前提摘要:
在此只提供关键函数代码实现,项目结构以及文件配置不在叙述范围,h函数为了便于理解为其加入一些限定条件:虚拟节点有text属性就没有children属性,有children属性就没有text。加入该条件的目的是简化讨论情况防止复杂逻辑容易懵,其实主要是讲解diff实现原理,if else这种情况判断只需取出典型,若细致到全部讨论容易舍本逐末,因为侧重点并不是来看他有多少种情况,而是如何进行diff的。
h函数:
主要的作用就是创建虚拟节点,他会接受部分值,然后通过调用Vnode函数将其转换成对象返回,这样就创建了虚拟节点如图4.1所示。
这里值得注意的是当一个虚拟节点的第三个参数是一个数组的时候,不需要进行循环处理什么东西,因为数组内每一项都是通过h函数创建的,他会再去走一次h函数的判断,那么这个时候return给外层h函数的children就已经是虚拟节点,无需处理了,这是一个精妙的地方。
var myVnode1 = h('ul',{},[
h('li',{key:'A'},'A'),
h('li',{key:'B'},'B'),
h('li',{key:'C'},'C'),
h('li',{key:'D'},'D'),
h('li',{key:'E'},'E'),
])4.1
import vnode from "./vnode";
//编写一个低配版本的h函数,这个函数必须接受3个参数,缺一不可
//相当于它的重载功能较弱
// 也就是说,调用的时候形态必须是下满三种之一
// h("div",{},'文字')
// h("div",{},[])
// h("div",{},h())
export default function(sel,data,c){
//检查参数的个数
if(arguments.length != 3 ){
throw new Error('对不起,h函数是低配版,最少三个参数!')
}
// 检查参数c的类型
if (typeof c == 'string' || typeof c == 'number'){
// 说明现在调用h函数是第一个类型
return vnode(sel,data,undefined,c,undefined)
}else if (Array.isArray(c)){
//说明现在调用h函数是第二种
let children = []
//遍历c,收集children中的h函数生成的数据
for (let i =0;iVnode函数:
Vnode函数的作用非常简单,就是将接受的参数组合合成对象返回即可,返回的就是虚拟节点内的属性。
//函数的功能非常简单,就把传入的5个参数组合合成对象返回
export default function(sel,data,children,text,elm) {
const key = data.key;
return {
// sel:sel,
// data:data,
// children:children,
// text:text,
// elm:elm,
// ES6新语法特性,属性值和属性名相同可以缩写
sel,data,children,text,elm,key
}
}createElement函数:
createElement函数的作用就是将虚拟节点转换成真正DOM结构,因为最终上树也就是呈现到页面的需要是真实DOM而不是虚拟节点,所以这步必不可少,值得注意的是之前说过h函数是通过多次调用h函数避开循环问题,那么当其转换成真正DOM结构的时候依旧需要再次面临循环问题,也就是内部children属性生成DOM结构需要如何处理?
为了方便说明4.1代码处说明,myVnode1虚拟节点在变成真实DOM节点之前,会根据他的sel属性创建真实DOM节点出来,但是这个时候他是一个孤儿节点,用变量domNode进行接收,巧妙的地方就来了,将children属性中的子节点创建并appendChild到domNode这个节点上,形成了一个“节点群”,由于此步操作在vnode.elm = domNode,return vnode.elm赋值和return之前进行,所以返回就是完整myVnode1的结构,自此就完成了有children属性的虚拟节点转换成真实DOM的操作。
PS:
孤儿节点:
其实是因为他还没上树,更通俗说就是还未与页面文本产生联系,但是节点已经被创建出来了,我们在学js基础的时候都知道,创建一个节点,需要先createElement,然后通过appendChild或insertBefore方法将结点加入到对应的位置
节点群:
我自己定义的,意思就是虽然还未上树,但是由于已经通过domNode生成了真实DOM节点,接下来的子节点就有了标杆可以依据此节点进行appendChild操作,这样就形成一群有关系节点群
// // 真正创建节点。将vnode创建为DOM,插入到pivot(标杆节点)这个元素之前
// export default function (vnode,pivot) {
// console.log('目的是把虚拟节点',vnode,'插入到标杆',pivot)
// //创建以一个DOM节点,这个节点现在是孤儿节点(未上树或者说没插入)
// //依据节点选择器名称创建节点
// let domNode = document.createElement(vnode.sel)
// //有子节点还是有文本??
// if(vnode.text != "" && (vnode.children == undefined || vnode.children.length ==0)){
// //它内部是文字
// domNode.innerText = vnode.text
// //将孤儿节点上书,让标杆节点的父元素调用insertBefore方法
// //将新的孤儿节点插入到标签节点之前就能在页面中显示真实DOM元素了
// pivot.parentNode.insertBefore(domNode,pivot)
// } else if (Array.isArray(vnode.children) && vnode.children.length > 0){
// //它内部是子节点,就要递归创建节点
// }
// }
// 真正创建节点。将vnode创建为DOM
export default function createElement(vnode) {
//将虚拟节点变成真正的DOM节点,但是未插入
//创建以一个DOM节点,这个节点现在是孤儿节点(未上树或者说没插入)
//依据节点选择器名称创建节点
let domNode = document.createElement(vnode.sel)
//有子节点还是有文本??
if(vnode.text != "" && (vnode.children == undefined || vnode.children.length ==0)){
//它内部是文字
domNode.innerText = vnode.text
//补充elm属性
vnode.elm = domNode
} else if (Array.isArray(vnode.children) && vnode.children.length > 0){
//它内部是子节点,就要递归创建节点
for (let i=0;ipatch函数:
patch函数的主要作用就是将虚拟节点上树,讲人话就是将虚拟节点转换成真实DOM节点,虚拟节点是用来做判断等等数据处理的,用户其实只关心真实DOM的变化,也只看得到真实DOM的变化,patch的作用就是是否转换成DOM,而复杂的逻辑判断的最终结果也是判断这个节点需不需要进行patch,也就是需不需要展示出来,需不需要上树,如果需要调用patch函数就能使虚拟节点展示到页面上成为真正的DOM。
由于将节点上树分为两种情况,一是同一个节点上树,二是不是同一个节点上树,第二种是比较暴力的方式,代码量较少,情况也很简单,删除旧节点添加新节点即可,但是第一种情况比较复杂,于是就抽离成一个方法叫patchVnode,也就是同一节点上树操作。
import vnode from "./vnode";
import createElement from "./createElement";
import patchVnode from "./patchVnode";
export default function (oldVnode,newVnode) {
//判断传入的第一个参数,是DOM节点还是虚拟节点?
if(oldVnode.sel == '' || oldVnode.sel == undefined) {
//传入的第一个参数是DOM节点,此时要包装为虚拟节点
oldVnode = vnode(oldVnode.tagName.toLowerCase(),{},[],undefined,oldVnode)
}
// console.log(oldVnode,newVnode,"查看一个节点样子")
//判断oldVnode和newVnode是不是同一个节点
if (oldVnode.key == newVnode.key && oldVnode.sel == newVnode.sel){
console.log("是同一个节点")
patchVnode(oldVnode,newVnode)
}else{
console.log("不是同一个节点,暴力插入新的删除旧的")
// createElement(newVnode,oldVnode.elm)
let newVnodeElm = createElement(newVnode)
//插入到老节点之前
if(oldVnode.elm.parentNode && newVnodeElm){
oldVnode.elm.parentNode.insertBefore(newVnodeElm,oldVnode.elm)
}
// 删除老节点
oldVnode.elm.parentNode.removeChild(oldVnode.elm)
}
}patchVnode函数:
patchVnode的主要作用是,同一节点上树,依旧可以分为两种情况,一种是text不同,及新旧节点都有text属性,text属性发生变化,这种情况也非常简单,第二种是新旧节点都有children属性,这种情况是最为复杂的,因为children有很多个,也分很多情况,比如修改、新增、删除、换序等等,所以又单独封装了一个方法叫updateChildren函数
import createElement from "./createElement";
import updateChildren from './updateChildren'
export default function patchVnode(oldVnode,newVnode){
// 判断新旧vnode是否是同一个对象
if (oldVnode === newVnode) return;
// 判断新vnode有没有text属性
if (newVnode.text != undefined && (newVnode.children == undefined || newVnode.children.length == 0)){
console.log("新Vnode有text属性")
if (newVnode.text != oldVnode.text){
// 如果新虚拟节点的text和老虚拟节点的text不同,那么直接让新的text写入老的elm中即可。
// 如果老的elm中的是children,那么也会立即消失
oldVnode.elm.innerText = newVnode.text
}
}else{
console.log("新Vnode没有text属性")
// 判断老的有没有children
if (oldVnode.children != undefined && oldVnode.children.length > 0){
// 老的有children,此时就是最复杂的情况。就是新老都有children。
//
//
//
updateChildren(oldVnode.elm,oldVnode.children,newVnode.children)
}else {
// 老的没有children,新的有children
// 清空老的节点内容
oldVnode.elm.innerHTML = ''
// 遍历新的vnode的子节点,创建DOM,上树
for (let i=0;iupdateChilren函数:
updateChilren函数主要的作用是处理同一节点并且都有children属性的不同情况的处理操作,这里是核心的地方之一,用到了snabbdom的diff算法,这个diff算法非常优秀,基本涵盖用户常进行的四种操作,这里涵盖内容较多,详细可以看尚硅谷老师的介绍,我这里就不介绍了
需要注意的是,除了核心四种命中之外,如图4.12所示即使错开四种命中依旧可以进行判断,那就是循环判断,通过map映射保存oldVnode中的key,然后通过对key值查找,如果有对应则进行patchVnode操作,如果没有就证明newVnode中的项是新增的,那么需要在oldstartVnode处添加真实节点即可,这样即使不是四种常见命中依旧可以处理
除了上述情况,还可能出现4.13和4.14两种情况,一个是新节点遍历完,老节点还有需要遍历的,此时需要进行删除操作,另一个是旧节点遍历完,新节点还有需要遍历,此时需要进行新增操作,因为如4.15中while()大循环内处理的就是四种命中及其补充的处理结果,而4.13 4.14则是除此之外剩下的两种情况,补充完这两种情况,一个简易的虚拟DOM和diff算法模型就完成了。
while(oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx)4.15
var myVnode1 = h('ul',{},[
h('li',{key:'A'},'A'),
h('li',{key:'B'},'B'),
h('li',{key:'C'},'C'),
h('li',{key:'D'},'D'),
h('li',{key:'E'},'E'),
])
var myVnode2 = h('ul',{},[
h('li',{key:'E'},'E'),
h('li',{key:'B'},'B'),
h('li',{key:'A'},'A'),
h('li',{key:'D'},'D'),
h('li',{key:'C'},'C'),
h('li',{key:'F'},'F'),
h('li',{key:'G'},'G'),
])4.14
var myVnode1 = h('ul',{},[
h('li',{key:'A'},'A'),
h('li',{key:'B'},'B'),
h('li',{key:'C'},'C'),
h('li',{key:'D'},'D'),
h('li',{key:'E'},'E'),
])
var myVnode2 = h('ul',{},[
h('li',{key:'E'},'E'),
h('li',{key:'B'},'B'),
])4.13
var myVnode1 = h('ul',{},[
h('li',{key:'A'},'A'),
h('li',{key:'B'},'B'),
h('li',{key:'C'},'C'),
h('li',{key:'D'},'D'),
h('li',{key:'E'},'E'),
])
var myVnode2 = h('ul',{},[
h('li',{key:'E'},'E'),
h('li',{key:'B'},'B'),
h('li',{key:'A'},'A'),
h('li',{key:'D'},'D'),
h('li',{key:'C'},'C'),
])4.12
import patchVnode from "./patchVnode"
import createElement from "./createElement"
// 判断是否是同一个虚拟节点
function checkSameVnode(a,b){
return a.sel == b.sel && a.key == b.key
}
export default function updateChildren(parentElm,oldCh,newCh){
// 四个指针
// 旧前
let oldStartIdx = 0
// 新前
let newStartIdx = 0
// 旧后
let oldEndIdx = oldCh.length - 1
// 新后
let newEndIdx = newCh.length - 1
// 旧前节点
let oldStartVnode = oldCh[0]
// 旧后节点
let oldEndVnode = oldCh[oldEndIdx]
// 新前节点
let newStartVnode = newCh[0]
// 新后节点
let newEndVnode = newCh[newEndIdx]
let keyMap = null
// 开始大while了
while(oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx){
//首先进行的不是四种命中的判断,而是略过已经是undefined标记过的值,表示已经被处理过了
if(oldStartVnode == null || oldCh[oldStartIdx] == undefined){
oldStartVnode = oldCh[++oldStartIdx]
}else if (oldEndVnode == null || oldCh[oldEndIdx] == undefined){
oldEndVnode = oldCh[--oldEndIdx]
}else if (newStartVnode == null || newCh[newStartIdx] == undefined){
newStartVnode = newCh[++newStartIdx]
}else if (newEndVnode == null || newCh[newEndIdx] == undefined){
newEndVnode = newCh[--newEndIdx]
}else
// 开始四次命中判断
// 新前和旧前
if (checkSameVnode(oldStartVnode,newStartVnode)){
console.log("1新前和旧前命中")
patchVnode(oldStartVnode,newStartVnode)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
}else
// 新后和旧后
if (checkSameVnode(oldEndVnode,newEndVnode)){
console.log("2新后和旧后命中")
patchVnode(oldEndVnode,newEndVnode)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
}else
// 新后与旧前
if (checkSameVnode(oldEndVnode,newEndVnode)){
console.log("3新后和旧前命中")
patchVnode(oldStartVnode,newEndVnode)
//当3新后与旧前命中的时候,此时要移动节点。移动新前指向的这个节点到老节点的旧后的后面
parentElm.insertBefore(oldStartVnode.elm,oldEndVnode.elm.nextSilbling)
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
}else
// 新前与旧后
if (checkSameVnode(oldEndVnode,newStartVnode)){
console.log("4新前和旧后命中")
patchVnode(oldEndVnode,newStartVnode)
//第四种情况需要移动节点,移动新前到旧前的前面
parentElm.insertBefore(oldEndVnode.elm,oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else{
//四种命中都没有匹配到
// 寻找key的map
if (!keyMap){
keyMap = {}
// 从oldStartIdx开始,到oldEndIdx结束,创建keyMap映射对象,查找速度更快
for (let i =oldStartIdx;i <= oldEndIdx;i++){
const key = oldCh[i].key
if(key!=undefined) {
keyMap[key] = i
}
}
}
console.log(keyMap)
// 寻找当前这项(newStartIdx)这项在keyMap种的映射的位置序号
const idxInOld = keyMap[newStartVnode.key]
console.log(idxInOld)
if(idxInOld == undefined) {
// 判断,如果idxInOld是undefined表示它是全新的项
// 被加入的项(就是newStartVode这项)现不是真正DOM节点
parentElm.insertBefore(createElement(newStartVnode),oldStartVnode.elm)
}else {
//如果不是undefined,不是全新的项,而是要移动的项
const elmToMove = oldCh[idxInOld]
patchVnode(elmToMove,newStartVnode)
//把这项设置成undefined,表示这个节点已经被处理过了
oldCh[idxInOld] = undefined
//移动阶段位置,将从新节点中找到的对应就节点定义成undefined后,需要将真正DOM节点移动到旧的开始节点之前
parentElm.insertBefore(elmToMove.elm,oldStartVnode.elm)
}
//只移动新的头
newStartVnode = [++newStartIdx]
}
}
// 继续看看有没有落下的情况,循环结束了start依旧比old小
// 需要新增的情况,也就是说遍历完新节点之后还有剩余,那么需要进行新增操作
if(newStartIdx <= newEndIdx){
//为什么是插到之前呢?很好理解,因为oldStartVnode其实是移动的跟随指针,oldStartVnode是
// 已经处理完了很多节点了,处理完的在他上面,所以新的处理结果也已经加在他之前
console.log("new还有剩余节点没有处理,要加项,将剩余项全部加到oldStartVnode之前")
// //找到插入的标杆,这里使用了三元表达式,有两种情况,一是如果是第一次插入那么newCh[newEndIdx+1].elm表示的是
// // 新节点的下一个,那么这个时候肯定是null,所以就在后面加一个相当于appendChild,二是如果已经有了第二个开始,那么就会
// // 有一个新节点存在,那么最新的就插入他的前面即可
// // 这里需要三元表达式还有一个原因是因为null不能打点会报错
// const before = newCh[newEndIdx+1] == null ? null : newCh[newEndIdx+1].elm
// for(let i = newStartIdx;i<=newEndIdx;i++){
// //insertBefore方法可以自动识别null,如果是是null就会自动排到队尾去,就是和appendChild是一致的
// // 这里newCh[i]还没变成真正DOM元素,所以需要调用createElement函数将其变成DOM
// parentElm.insertBefore(createElement(newCh[i]),before)
// }
// 遍历新的newCh,添加到老的没有处理之前
for(let i = newStartIdx;i<=newEndIdx;i++){
//insertBefore方法可以自动识别null,如果是是null就会自动排到队尾去,就是和appendChild是一致的
// 这里newCh[i]还没变成真正DOM元素,所以需要调用createElement函数将其变成DOM
parentElm.insertBefore(createElement(newCh[i]),oldCh[oldStartIdx].elm)
}
}else
// 还有一种情况是Old节点没有循环完毕,这种情况就是老节点多了,就是需要删除老节点
if(oldStartIdx <= oldEndIdx){
console.log("old还有剩余节点没有处理,要删")
// 批量删除oldStart和oldEnd指针之间的项
for(let i= oldStartIdx;i<=oldEndIdx;i++){
if(oldCh[i]){
parentElm.removeChild(oldCh[i].elm)
}
}
}
}流程总图: