深度学习之图像分类(二十)-- Transformer in Transformer(TNT)网络详解
深度学习之图像分类(二十)Transformer in Transformer(TNT)网络详解
目录
-
- 深度学习之图像分类(二十)Transformer in Transformer(TNT)网络详解
-
- 1. 前言
- 2. TNT Block
- 3. Position encoding
- 4. 复杂度计算分析
- 5. 可视化结果
- 6. 代码
本节学习 Transformer 嵌入 Transformer 的融合网络 TNT,思想自然,源于华为,值得一看。

1. 前言
Transformer in Transformer(TNT) 是华为团队 2021 的文章,论文为 Transformer in Transformer,并且表达的思想非常简单和自然。在原始的 Transformer 中,例如 ViT 中,对图片进行切片处理,切成了 16 × 16 16 \times 16 16×16 的 patch,Multi-Head Self-Attention 编码的是 patch 与 patch 之间的信息,也就是例如一个人脸图片,编码眼睛和嘴巴之间的相应权重。但是对于 patch 内部却没有进行很精细的编码,也就是说图片输入本身的“局部性”特性没有很好的利用上。一个很自然的想法就是,那我把 patch 直接变小好了,例如变为 4 × 4 4 \times 4 4×4 的大小,但是这样的话大大增加了 token 的数量,也增加了 Transformer 模型的计算量。此外之前微软团队的 Swin 工作也提到说,考虑把 key 值共享在一个小的 location 里可以对应于图像的局部性。那么,我们可以将大的 patch 再进行切片,在 patch 内部做一个 Multi-Head Self-Attention,将 key 值共享在 patch 内部,这样就能够兼顾“局部性”以及计算量。
事实上,Transformer in Transformer 和 U2Net (Unet in Unet) 有异曲同工之妙!
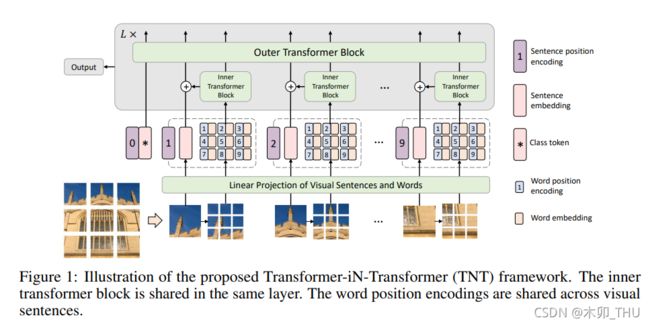
2. TNT Block
patch 内部的信息交流也非常重要,特别是对于精细结构而言。作者将 16 × 16 16 \times 16 16×16 的 patch 称为 visual sentences,将 patch 再进行切片出来的例如 4 × 4 4 \times 4 4×4 的更小的 patch 称为 visual word。这样 patch 内部进行自注意力机制研究哪里比较重要,patch 之间通过自注意力机制研究彼此之间的关系,能帮助我们增强特征的表示能力。此外,这样的小范围的 transformer 并不会增加太大的计算量。
让我们一步一步看看它是怎么实现的。
首先给定一个 2D 图像,我们通常将其进行切片形成 X = [ X 1 , X 2 , ⋯ , X n ] ∈ R n × p × p × 3 \mathcal{X}=\left[X^{1}, X^{2}, \cdots, X^{n}\right] \in \mathbb{R}^{n \times p \times p \times 3} X=[X1,X2,⋯,Xn]∈Rn×p×p×3, 即切成 n n n 个 patch,每个 patch 是 p × p × 3 p \times p \times 3 p×p×3,3 为 RGB 通道, p p p 为 patch 的分辨率。此后我们对单个 patch 再进行切分,切成 m m m 个 sub-patch,得到 visual sentence 对应的一系列的 visual words:
X i → [ x i , 1 , x i , 2 , ⋯ , x i , m ] X^{i} \rightarrow\left[x^{i, 1}, x^{i, 2}, \cdots, x^{i, m}\right] Xi→[xi,1,xi,2,⋯,xi,m]
其中 x i , j ∈ R s × s × 3 x^{i,j} \in \mathbb{R}^{s \times s \times 3} xi,j∈Rs×s×3,3 为 RGB 通道, s s s 为 sub-patch 的分辨率, x i , j x^{i,j} xi,j 表示第 i i i 个 patch 的第 j j j 个 sub-patch。例如一个 16 × 16 16 \times 16 16×16 的 patch 可以再被切为 16 个 4 × 4 4 \times 4 4×4 的 patch,则 m = 16 , s = 4 m=16, s=4 m=16,s=4。对于每个 sub-patch,首先将它们进行展平(向量化 vectorization),然后经过一个全连接层进行编码:
Y i = [ y i , 1 , y i , 2 , ⋯ , y i , m ] , y i , j = F C ( Vec ( x i , j ) ) Y^{i}=\left[y^{i, 1}, y^{i, 2}, \cdots, y^{i, m}\right], \quad y^{i, j}=F C\left(\operatorname{Vec}\left(x^{i, j}\right)\right) Yi=[yi,1,yi,2,⋯,yi,m],yi,j=FC(Vec(xi,j))
然后将它们经过一个非常普通的由 Multi-Head Self-Attention 和 MLP 组成的 Transformer block 进行 patch 内部的 Transformer 操作,LN 则是 Layer Normalization 层,其中下标 l l l 表示第几个 inner transform block:
Y l ′ i = Y l − 1 i + MSA ( L N ( Y l − 1 i ) ) Y l i = Y l ′ i + MLP ( L N ( Y l ′ i ) ) \begin{aligned} Y_{l}^{\prime i} &=Y_{l-1}^{i}+\operatorname{MSA}\left(L N\left(Y_{l-1}^{i}\right)\right) \\ Y_{l}^{i} &=Y_{l}^{\prime i}+ \operatorname{MLP}\left(L N\left(Y_{l}^{\prime i}\right)\right) \end{aligned} Yl′iYli=Yl−1i+MSA(LN(Yl−1i))=Yl′i+MLP(LN(Yl′i))
得到 patch 内部经过注意力机制变换后的新的 sub-patch 表示,对其进行编码得到和对应 patch 相同大小的编码,与原始 patch 进行加和。这里的 W l − 1 , b l − 1 W_{l-1},b_{l-1} Wl−1,bl−1 对应的就是一个全连接层的权重和偏置,但是在源码中这里并没有使用偏置 self.proj = nn.Linear(num_words * inner_dim, outer_dim, bias=False)。
Z l − 1 i = Z l − 1 i + Vec ( Y l − 1 i ) W l − 1 + b l − 1 Z_{l-1}^{i}=Z_{l-1}^{i}+\operatorname{Vec}\left(Y_{l-1}^{i}\right) W_{l-1}+b_{l-1} Zl−1i=Zl−1i+Vec(Yl−1i)Wl−1+bl−1
patch token 结合了自身切片后进行变换后的信息在馈入 outer transformer block 就得到了下一层的新 token。
Z l ′ i = Z l − 1 i + MSA ( L N ( Z l − 1 i ) ) Z l i = Z ′ i + MLP ( L N ( Z l ′ i ) ) \begin{aligned} \mathcal{Z}_{l}^{\prime i} &=\mathcal{Z}_{l-1}^{i}+\operatorname{MSA}\left(L N\left(\mathcal{Z}_{l-1}^{i}\right)\right) \\ \mathcal{Z}_{l}^{i} &=\mathcal{Z}^{\prime i}+\operatorname{MLP}\left(L N\left(\mathcal{Z}_{l}^{\prime i}\right)\right) \end{aligned} Zl′iZli=Zl−1i+MSA(LN(Zl−1i))=Z′i+MLP(LN(Zl′i))
这些总结出来就是:
Y l , Z l = TNT ( Y l − 1 , Z l − 1 ) \mathcal{Y}_{l}, \mathcal{Z}_{l}=\operatorname{TNT}\left(\mathcal{Y}_{l-1}, \mathcal{Z}_{l-1}\right) Yl,Zl=TNT(Yl−1,Zl−1)
在 TNT block 中,inner transformer block 用于捕捉局部区域之间的特征关系,而 outer transformer block 则用于捕捉区域之间的联系。将 inner transformer block 的输出加到 outer transformer block 的输入上,这其实就像类似上级向下级传达任务(分类猫狗),下级首先形成一个初步意见(初始token),然后每个小组内部先进行讨论沟通交流,整合意见之后交给小组长(token 相加),小组长共同开会进行交流沟通得到一个意见之间的融合,再传递给上级。这种组内部的交流沟通在生活中非常常见。
In our TNT block, the inner transformer block is used to model the relationship between visual words for local feature extraction, and the outer transformer block captures the intrinsic information from the sequence of sentences. By stacking the TNT blocks for L times, we build the transformerin-transformer network. Finally, the classification token serves as the image representation and a fully-connected layer is applied for classification.
TNT 网络结构如下所示,Depth 为 block 重复的次数。

3. Position encoding
很多工作表示了,位置编码非常重要,那么每个 sub-patch 对应的 token 怎么进行位置编码呢?在 TNT 中,不同 sentence 中的 words 共享位置编码,即 E w o r d E_{word} Eword 表示的是 sub-patch 在 patch 中的位置,这个在各个大 patch 中是一致的。
Z 0 ← Z 0 + E sentence Y 0 i ← Y 0 i + E w o r d , i = 1 , 2 , ⋯ , n \mathcal{Z}_{0} \leftarrow \mathcal{Z}_{0}+E_{\text {sentence }}\\ Y_{0}^{i} \leftarrow Y_{0}^{i}+E_{w o r d}, i=1,2, \cdots, n Z0←Z0+Esentence Y0i←Y0i+Eword,i=1,2,⋯,n
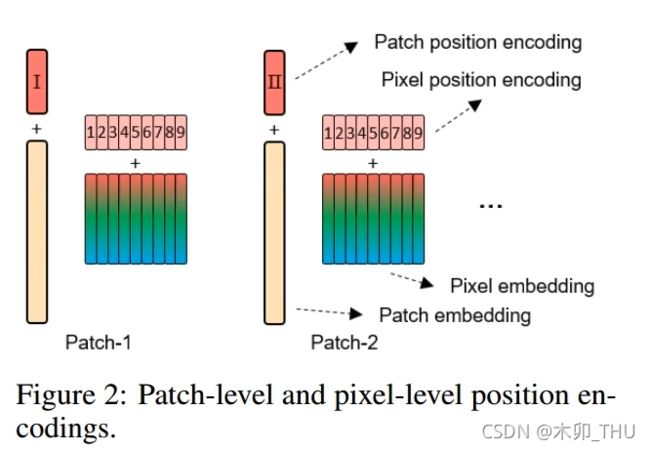
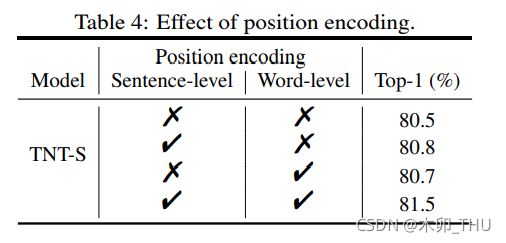
实验也发现,两个都使用位置编码可以得到更好的效果,但是在这篇 paper 中就没有去讨论使用绝对还是相对位置编码,1D 还是 2D 位置编码,以及把位置编码和 query 点乘构建 Attention 的一部分了。
4. 复杂度计算分析
对于原论文的描述,我一直存在疑惑,希望得到大家的解答。
一个标准的 Transformer block 包含两部分,Multi-head Self-Attention 和 multi-layer perceptron. 其中 Multi-head Self-Attention 的计算 FLOPs 为 2 n d ( d k + d v ) + n 2 ( d k + d v ) 2 n d\left(d_{k}+d_{v}\right)+n^{2}\left(d_{k}+d_{v}\right) 2nd(dk+dv)+n2(dk+dv),其中 n n n 为 token 的数量, d d d 为 token 的维度,query 和 key 的维度都是 d k d_k dk,value 的维度为 d v d_v dv。MLP 对应的 FLOPs 则为 2 n d v r d v 2nd_vrd_v 2ndvrdv,其中 r r r 通常取 4,为第一个 全连接层维度扩展的倍数。通常呢这个 d k = d v = d d_k = d_v = d dk=dv=d 。当不考虑 bias 以及 LN 时,一个标准的 transformer block 的 FLOPs 为 :
FLOPs T = 2 n d ( d k + d v ) + n 2 ( d k + d v ) + 2 n d d r = 2 n d ( 6 d + n ) \operatorname{FLOPs}_{T}=2 n d\left(d_{k}+d_{v}\right)+n^{2}\left(d_{k}+d_{v}\right)+2 n d d r = 2nd(6d+n) FLOPsT=2nd(dk+dv)+n2(dk+dv)+2nddr=2nd(6d+n)
MLP 对应的 FLOPs 很好理解,一个 n d d r nddr nddr 是第一个全连接层从 d d d 扩展维度到 r d rd rd;一个 n d d r nddr nddr 是第一个全连接层从 r d rd rd 还原到 d d d。但是 MSA 的 FLOPs 就不是那么好理解了。 2 n d d k 2ndd_k 2nddk 是计算 n n n 个 token 对应的 key 和 query, n d d v ndd_v nddv 是计算 n n n 个 token 对应的 value,那前面的 2 怎么理解呢?此外, n 2 ( d k + d v ) n^{2}\left(d_{k}+d_{v}\right) n2(dk+dv) 应该对应的是计算 Attention 矩阵以及对 d v d_v dv 进行加权求和。计算 Attention 是会得到 n 2 n^2 n2 对 key 和 query 点乘,也应该是 n 2 d k n^2 d_k n2dk? n n n 个新 token,每个源自 n n n 个 value 的加权求和,那么很自然是 n 2 d v n^2d_v n2dv。其中 n d v n d_v ndv 表示一个新 token 是 n n n 个 value 的加权求和。
我认为的一个标准的 transformer block 的 FLOPs 为 :
- 计算 query: W q X = n d d W_q X = ndd WqX=ndd
- 计算 key: W k X = n d d W_kX = ndd WkX=ndd
- 计算 value: W v X = n d d W_vX = ndd WvX=ndd
- 计算 Attention Q K T QK^T QKT: n 2 d n^2d n2d
- 计算 value 的加权平均: n 2 d n^2 d n2d
- 两层全连接层: W 2 W 1 X = 2 n d r d W_2W_1X = 2ndrd W2W1X=2ndrd
- 所以应该是 3 n d d + 2 n 2 d + 8 n d d = 2 n d ( 5.5 d + n ) 3ndd + 2n^2 d + 8ndd = 2nd(5.5d+n) 3ndd+2n2d+8ndd=2nd(5.5d+n)?
- 忽略了 残差 n d nd nd 级别,忽略了偏置 n d nd nd 级别,忽略了 LN。
一个标准的 transformer block 的参数量为 :
Params T = 12 d d . \text { Params }_{T}=12 d d \text {. } Params T=12dd.
而在 TNT 中,新增的一个 inner transformer block 的计算量和一个全连接层,所以 TNT 的 FLOPs 为 :
F L O P S T N T = 2 n m c ( 6 c + m ) + n m c d + 2 n d ( 6 d + n ) \mathrm{FLOPS}_{T N T}=2 n m c(6 c+m)+n m c d+2 n d(6 d+n) FLOPSTNT=2nmc(6c+m)+nmcd+2nd(6d+n)
其中 2 n m c ( 6 c + m ) 2nmc(6c+m) 2nmc(6c+m) 为 inner transformer block, 2 n d ( 6 d + n ) 2nd(6d+n) 2nd(6d+n) 为 outer transformer block, n m c d nmcd nmcd 为那个全连接层,需要从 m × c m \times c m×c 维转为 n × d n \times d n×d 维。相应的 TNT 的参数量为:
Params T N T = 12 c c + m c d + 12 d d . \text { Params }_{TNT}=12cc+mcd+12 d d \text {. } Params TNT=12cc+mcd+12dd.
当 c ≪ d c \ll d c≪d 且 O ( m ) ≈ O ( n ) O(m) \approx O(n) O(m)≈O(n) 时候,例如 d = 384 , n = 196 , c = 24 , m = 16 d=384,n=196,c=24,m=16 d=384,n=196,c=24,m=16 时,TNT 的 FLOPs 为 1.14x,Params 为 1.08x。
但是 FLOPs 原论文算正确了吗?

5. 可视化结果
TNT 做分类等实验都表现出了一定的性能,其中和 DeiT 对比的可视化结果比较可观的反映出来了提升。可见局部信息在浅层得到了很好的保留,而随着网络的深入,表征逐渐变得更加抽象。


inner transformer 中不同的 query 位置(sub-patch)对应的激活部位可见,局部交流还是很有用的!

6. 代码
代码出处见 此处。
# 2021.06.15-Changed for implementation of TNT model
# Huawei Technologies Co., Ltd.