出于工作需要,学习了GAN,原理这块就不多讲了,主要讲怎么训练自己的数据生成新的图片,因为博客上大多是生成MNIST数据集,生成自己的图片时,有些小坑。
下面记录一下本人基于参考链接,将MNIST数据集的代码改成生成自己数据时遇到的坑。
一、读取数据问题
# MNIST dataset
mnist = datasets.MNIST(
root='./data/', train=True, transform=img_transform, download=True)
# Data loader
dataloader = torch.utils.data.DataLoader(
dataset=mnist, batch_size=batch_size, shuffle=True)
可以看到,datasets.MNIST这个肯定不能用于我们自己的数据。我借鉴了原来做二分类的datasets.ImageFolder。
发现老是报错:
RuntimeError: Found 0 files in subfolders of: E:\Projects\gan\battery\ng
Supported extensions are: .jpg,.jpeg,.png,.ppm,.bmp,.pgm,.tif,.tiff,.webp
后面单步调试,原来这个函数是需要文件夹下面有分类标签的,根据子文件夹名生成分类标签。
故放弃,只能自己写了。
下面是参考网上的,写了个读取数据的函数:
import numpy as np
import torch
import os
import random
from PIL import Image
from torch.utils.data import Dataset
class myDataset(Dataset):
def __init__(self, data_dir, transform):
self.data_dir = data_dir
self.transform = transform
self.img_names = [name for name in list(filter(lambda x: x.endswith(".jpg"), os.listdir(self.data_dir)))]
def __getitem__(self, index):
path_img = os.path.join(self.data_dir, self.img_names[index])
img = Image.open(path_img).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img
def __len__(self):
if len(self.img_names) == 0:
raise Exception("\ndata_dir:{} is a empty dir! Please checkout your path to images!".format(self.data_dir))
return len(self.img_names)
二、维度不匹配问题
解决了读取数据之后,发现可以训练了,因为参考链接的MINIST数据都是单通道的,我们大部分图像都是3通道的,所以我将通道改为3后,发现判别器那块老是报错,标签和数据不匹配。
RuntimeError: mat1 dim 1 must match mat2 dim 0
后面一查,发现问题出在这句上面:
for i, (imgs, _) in enumerate(dataloader)
这样得到的imgs已经没有batch-size的信息了,需要改为这样:
for i, imgs in enumerate(dataloader):
下面是整个代码块,贴上去记录下来,以便过段时间万一忘了,还有个看的地方。
import argparse
import os
import numpy as np
import math
# import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets, models, transforms
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
from tools.my_dataset import myDataset
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=50, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=2, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=4, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=128, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
print('cuda is',cuda)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# Loss function
adversarial_loss = torch.nn.BCELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# # Configure data loader
# os.makedirs("./data/mnist", exist_ok=True)
# dataloader = torch.utils.data.DataLoader(
# datasets.MNIST(
# "./data/mnist",
# train=True,
# download=True,
# transform=transforms.Compose(
# [transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
# ),
# ),
# batch_size=opt.batch_size,
# shuffle=True,
# )
dataset = r'E:\Projects\gan\battery'
ng_directory = os.path.join(dataset, 'ng')
ok_directory = os.path.join(dataset, 'ok')
image_transforms = {
'ng': transforms.Compose([
transforms.Resize([opt.img_size,opt.img_size]),
transforms.ToTensor(),
]),
'ok': transforms.Compose([
transforms.Resize([opt.img_size,opt.img_size]),
transforms.ToTensor(),
])}
data = {
'ng': myDataset(data_dir=ng_directory, transform=image_transforms['ng']),
'ok': myDataset(data_dir=ok_directory, transform=image_transforms['ok'])
}
dataloader = DataLoader(data['ng'], batch_size=opt.batch_size, shuffle=True)
ng_data_size = len(data['ng'])
ok_data_size = len(data['ok'])
print('train_size: {:4d} valid_size:{:4d}'.format(ng_data_size, ok_data_size))
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
# for i, (imgs, _) in enumerate(dataloader):
for i, imgs in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 3, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
aa = discriminator(gen_imgs)
g_loss = adversarial_loss(aa, valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
bb = discriminator(real_imgs)
real_loss = adversarial_loss(bb, valid)
# 此处需要注意,detach()是为了截断梯度流,不计算生成网络的损失,
# 因为d_loss包含了fake_loss,回传的时候如果不做处理,默认会计算generator的梯度,
# 而这里只需要计算判别网络的梯度,更新其权重值,生成网络保持不变即可。
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)

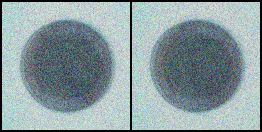
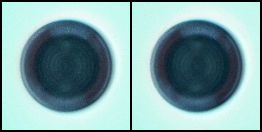
上面是原始图片,下面是生成的图片,从开始的噪声,到慢慢有点样子,还没训练完,由于我的显卡比较小,GTX1660Ti,6G显存,所以将原始图片从800x800压缩到了128x128,可能影响了效果,没关系,后面还可以优化,包括将全连接网络改为卷积的,图片设置大点,等等。

总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。