人工智能论文原理图集2
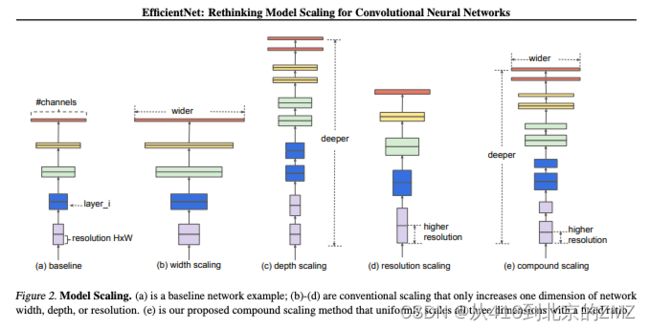
1, EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
2, EfficientFormer: Vision Transformers at MobileNet
Speed

3, Vision Transformers for Dense Prediction

4, DiT: Self-supervised Pre-training for
Document Image Transformer

5, Dilated Neighborhood Attention Transformer


6, End-to-End Object Detection with Transformers



7, NMS Strikes Back

8, Training data-efficient image transformers
& distillation through attention

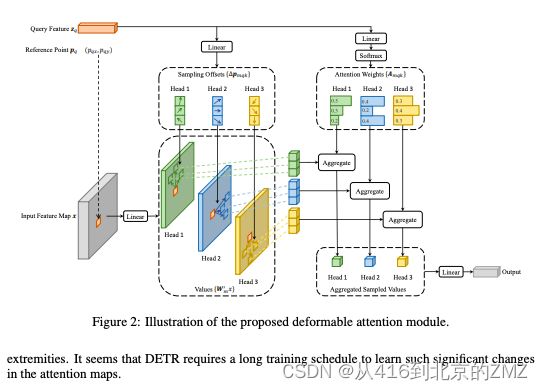
9, DEFORMABLE DETR: DEFORMABLE TRANSFORMERS
FOR END-TO-END OBJECT DETECTION

10, CvT: Introducing Convolutions to Vision Transformers


11, ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders


12, A ConvNet for the 2020s

13, Big Transfer (BiT): General Visual Representation Learning

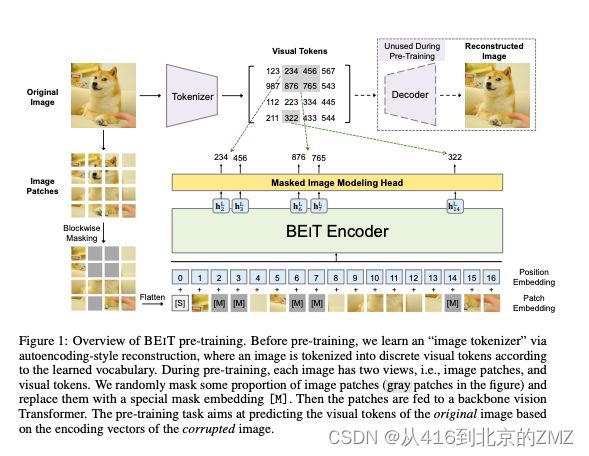
14, BEIT: BERT Pre-Training of Image Transformers
15, XLNet: Generalized Autoregressive Pretraining
for Language Understanding
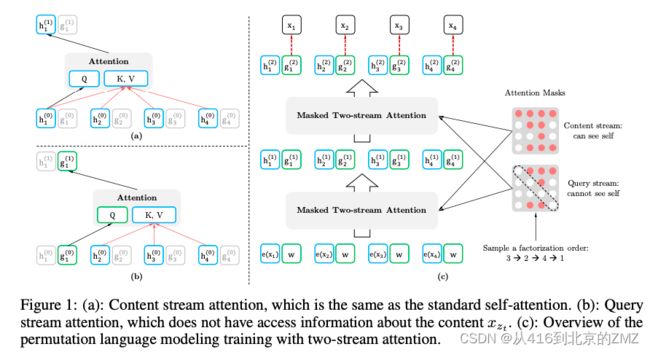
16, ProphetNet: Predicting Future N-gram for Sequence-to-Sequence
Pre-training


17, Cross-lingual Language Model Pretraining

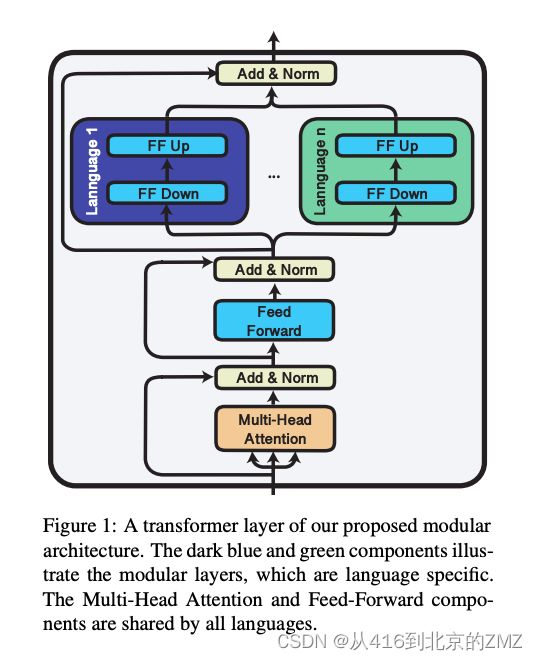
18, Lifting the Curse of Multilinguality
by Pre-training Modular Transformers
19, Unifying Language Learning Paradigms


20, TAPEX: TABLE PRE-TRAINING VIA LEARNING A
NEURAL SQL EXECUTOR




21, Exploring the Limits of Transfer Learning with a Unified
Text-to-Text Transformer



22, Switch Transformers: Scaling to Trillion Parameter Models
with Simple and Efficient Sparsity


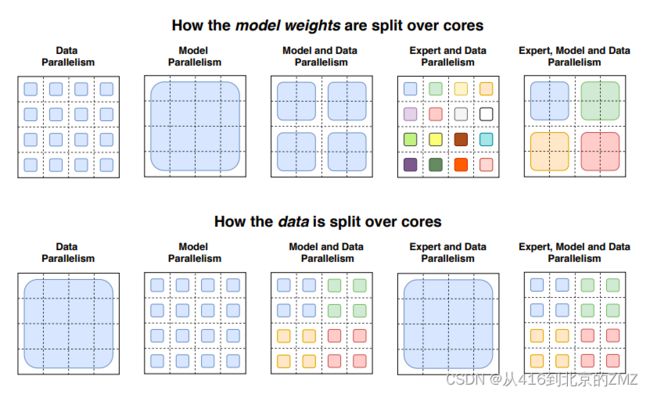
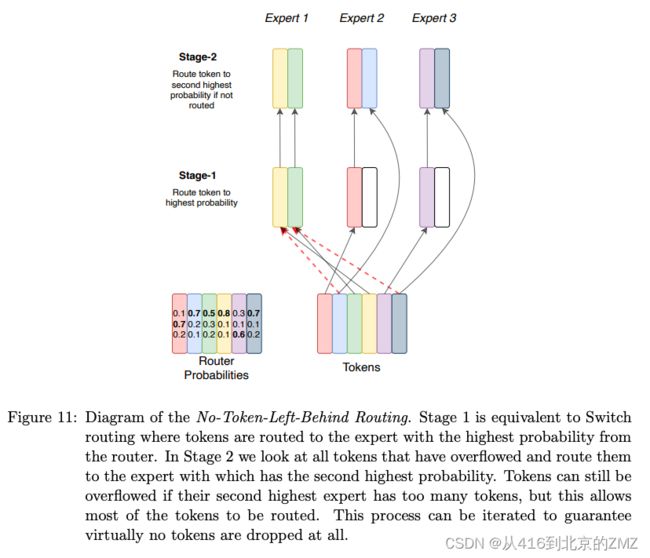
23, Few-Shot Question Answering by Pretraining Span Selection

24, ROFORMER: ENHANCED TRANSFORMER WITH ROTARY
POSITION EMBEDDING

25, RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining

26, FAIRSEQ: A Fast, Extensible Toolkit for Sequence Modeling

27, REFORMER: THE EFFICIENT TRANSFORMER


28, REALM: Retrieval-Augmented Language Model Pre-Training

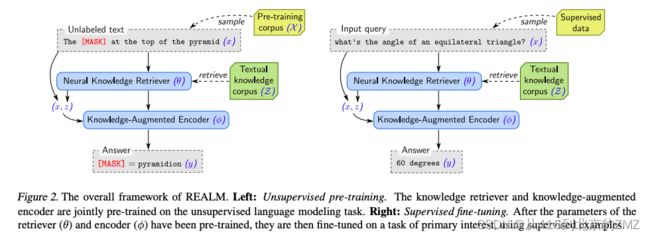
29, Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks

30, INTEGER QUANTIZATION FOR DEEP LEARNING INFERENCE:
PRINCIPLES AND EMPIRICAL EVALUATION

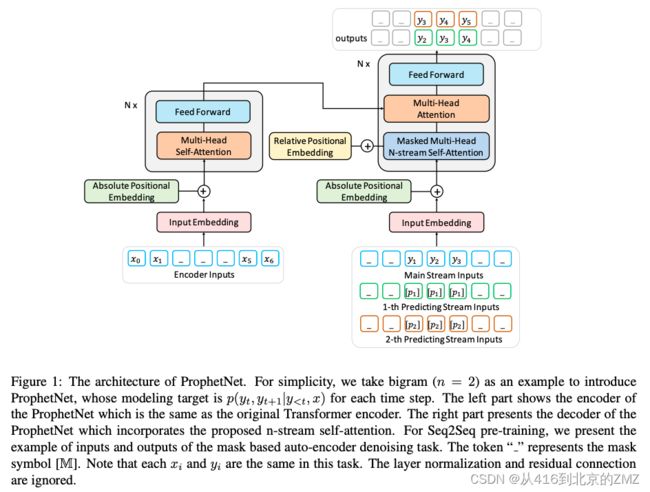
31, ProphetNet: Predicting Future N-gram for Sequence-to-Sequence
Pre-training

32, PEGASUS: Pre-training with Extracted Gap-sentences for
Abstractive Summarization

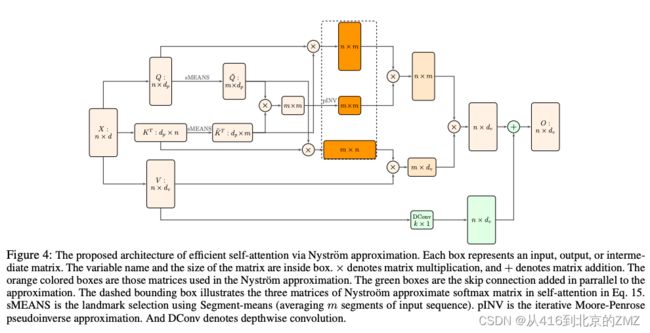
33, Nystromformer: A Nystr ¨ om-based Algorithm for Approximating Self-Attention

34, Twitter’s Recommendation Algorithm

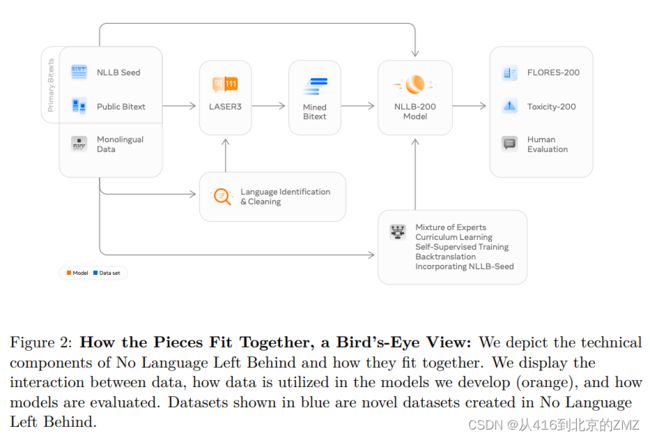
35, No Language Left Behind:
Scaling Human-Centered Machine Translation











36, MVP: Multi-task Supervised Pre-training
for Natural Language Generation

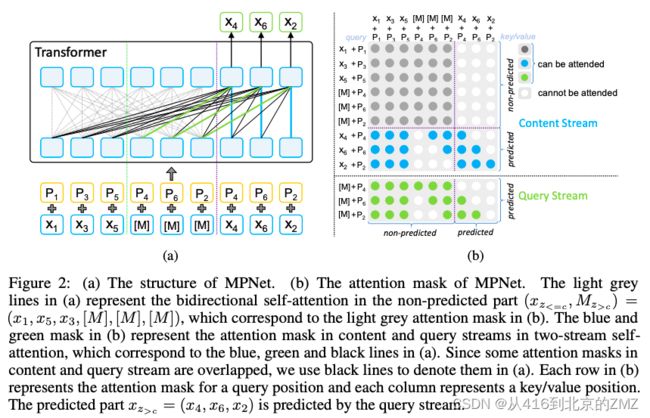
37, MPNet: Masked and Permuted Pre-training for
Language Understanding


38, MobileBERT: a Compact Task-Agnostic BERT
for Resource-Limited Devices


39, mLUKE: The Power of Entity Representations
in Multilingual Pretrained Language Models

40, Megatron-LM: Training Multi-Billion Parameter Language Models Using
Model Parallelism