Hadoop2.7.5集群搭建
官方文档:
Hadoop – Apache Hadoop 2.7.5
《Hadoop权威指南》第四版中文版pdf:
链接:https://pan.baidu.com/s/1WDWgZLlErWf6S-9JJwiAqQ
提取码:umnh
参考课程:【好程序员】最新大数据Hadoop入门基础视频教程,适合零基础自学的大数据开发课程_哔哩哔哩_bilibili
下载hadoop:
https://hadoop.apache.org/releases.html
可以下载最新版本,也可以在网站中找到发布记录里自己想要的版本,这里我下载的是hadoop-2.7.5.tar.gz版本。
- 准备三台机器用以搭建3个节点的hadoop集群
| Hostname | IP | Role |
| hadoop01 | 192.168.126.132 | NameNode DataNode NodeManager |
| hadoop02 | 192.168.126.133 | SecondaryNameNode NodeManager |
| hadoop03 | 192.168.126.134 | DataNode NodeManager |
- 安装JDK(安装步骤参考:https://blog.csdn.net/QYHuiiQ/article/details/86560498)

- 关闭防火墙,以保证三台节点之间可以相互通信
[root@localhost wyh]# systemctl stop firewalld
[root@localhost wyh]# systemctl disable firewalld
[root@localhost wyh]# systemctl status firewalld
[root@localhost wyh]# vi /etc/selinux/config
SELINUX=disabled
- 修改主机名
[root@localhost wyh]# vi /etc/hostname
hadoop01
#重启使之生效
[root@localhost wyh]# reboot
#查看主机名
[root@hadoop01 ~]# hostname
hadoop01
[root@hadoop02 ~]# hostname
hadoop02
[root@hadoop03 ~]# hostname
hadoop03
- 添加主机ip与主机名之间的映射关系
[root@hadoop01 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.126.132 hadoop01
192.168.126.133 hadoop02
192.168.126.134 hadoop03
#将配置文件分发给另外两台机器
[root@hadoop01 ~]# scp /etc/hosts root@hadoop02:/etc/hosts
[root@hadoop01 ~]# scp /etc/hosts root@hadoop03:/etc/hosts
- 配置免密登录
#使用rsa加密技术生成公钥和私钥;命令执行过程中全部输入回车即可(分别在三台机器上执行)。
[root@hadoop01 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:P3ZWmLDVyGvYaWw8SQemtnkr2bHWmaGm5pIzBat+bIY root@hadoop01
The key's randomart image is:
+---[RSA 2048]----+
| o |
| + + |
| + = o |
| .. % B |
| So= ^ o |
| ...B O + |
| + o* X + |
| E X..O |
| ..+ *o |
+----[SHA256]-----+
#进入home目录下的.ssh隐藏目录,使用ssh-copy-id命令将主机1的公钥分发给主机2,使得主机1可以实现对主机2的免密登录
[root@hadoop01 ~]# cd
[root@hadoop01 ~]# ll -a
total 28
dr-xr-x---. 3 root root 147 Mar 7 07:32 .
dr-xr-xr-x. 17 root root 244 Mar 7 08:03 ..
-rw-------. 1 root root 1371 Feb 28 17:03 anaconda-ks.cfg
-rw-------. 1 root root 830 Mar 7 08:03 .bash_history
-rw-r--r--. 1 root root 18 Dec 28 2013 .bash_logout
-rw-r--r--. 1 root root 176 Dec 28 2013 .bash_profile
-rw-r--r--. 1 root root 176 Dec 28 2013 .bashrc
-rw-r--r--. 1 root root 100 Dec 28 2013 .cshrc
drwx------. 2 root root 57 Mar 7 08:26 .ssh
-rw-r--r--. 1 root root 129 Dec 28 2013 .tcshrc
[root@hadoop01 ~]#
[root@hadoop01 ~]# cd .ssh/
[root@hadoop01 .ssh]# ll
total 12
-rw------- 1 root root 1679 Mar 7 08:26 id_rsa
-rw-r--r-- 1 root root 395 Mar 7 08:26 id_rsa.pub
-rw-r--r--. 1 root root 694 Mar 7 08:18 known_hosts
[root@hadoop01 .ssh]#
[root@hadoop01 .ssh]# ssh-copy-id hadoop02
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop02's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop02'"
and check to make sure that only the key(s) you wanted were added.
#分发成功,尝试登陆
[root@hadoop01 .ssh]# ssh hadoop02
Last login: Mon Mar 7 08:07:55 2022 from 192.168.126.100
#尝试在主机2上将公钥复制给主机3(root@可以省略不写,因为默认就是以root账户进行操作)
[root@hadoop02 ~]# ssh-copy-id root@hadoop03
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'hadoop03 (192.168.126.134)' can't be established.
ECDSA key fingerprint is SHA256:G87zFtUxK/e6e1PR5z23FSTd5FnEZn7Df9m4WDxzaWc.
ECDSA key fingerprint is MD5:f0:df:12:7b:ad:f0:68:53:d7:69:2a:a7:08:e2:6c:af.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop03's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@hadoop03'"
and check to make sure that only the key(s) you wanted were added.
[root@hadoop02 ~]# ssh hadoop03
Last login: Mon Mar 7 08:08:40 2022 from 192.168.126.100
由于免密操作是单向的,所以需要在每个节点上都要对另外两个节点执行ssh-copy-id命令使之可以双向免密,也可以对自己本机也执行copy命令使启动集群时对自己也执行免密,这里就省略余下的分发操作。
分发之后,可以看到.ssh目录下多了一个authorized_keys文件,这个文件就是用来保存其他节点的公钥。id_rsa.pub是自己的公钥,id_rsa是自己的私钥。
[root@hadoop01 .ssh]# ll
total 16
-rw------- 1 root root 790 Mar 7 08:50 authorized_keys
-rw------- 1 root root 1679 Mar 7 08:26 id_rsa
-rw-r--r-- 1 root root 395 Mar 7 08:26 id_rsa.pub
-rw-r--r--. 1 root root 694 Mar 7 08:18 known_hosts
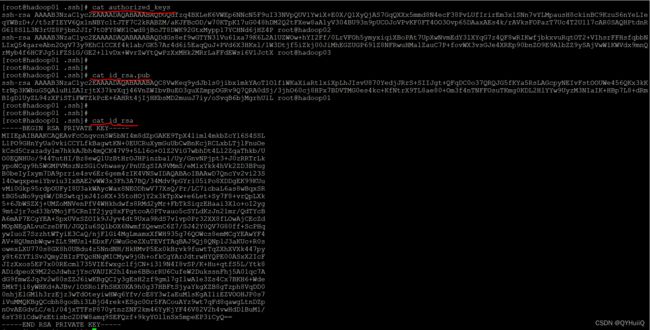
免密登录的实现原理:
主机01将自己生成的公钥发送给主机02,02收到01发送的公钥之后将01的公钥保存到自己的authorized_keys文件中。当01想要免密登录02时,会向02发送请求,请求命令中包含了01自己的ip、主机等信息,02收到01发送的登录请求后,会去自己的authorized_keys中查找有没有01对应的ip等登陆信息,如果查到了有01的信息,那么就会随机生成一个字符串并用01的公钥进行加密,将加密后的字符串返回给01,01收到02加密后的字符串后,会用自己的私钥对该字符串进行解密,如果自己的私钥可以解密成功,就将解密后的字符串返回给02,02收到返回的字符串后会与自己最开始生成的随机字符串进行验证,如果验证成功,就表明允许01免密登录。
- 集群节点间的时间同步
集群间的时间必须保持同步,他们之间的时间差不能超过30s。以其中一台机器的时间为准,将另外两台机器与其同步。
在01上安装ntp(时间同步服务器)
[root@hadoop01 .ssh]# yum -y install ntp在01上修改文件:
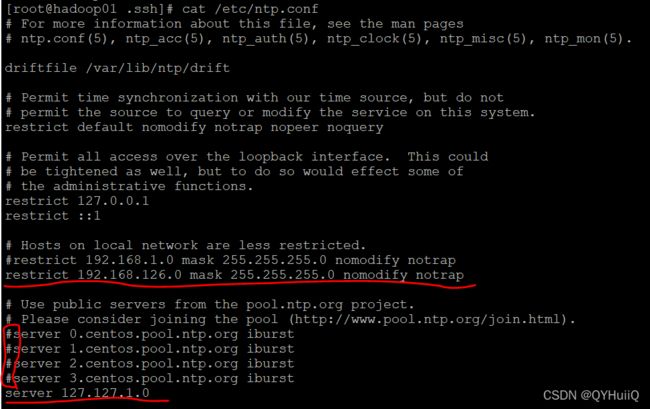
在01上开启ntpd服务:
[root@hadoop01 .ssh]# systemctl start ntpd查看状态:
[root@hadoop01 .ssh]# systemctl status ntpd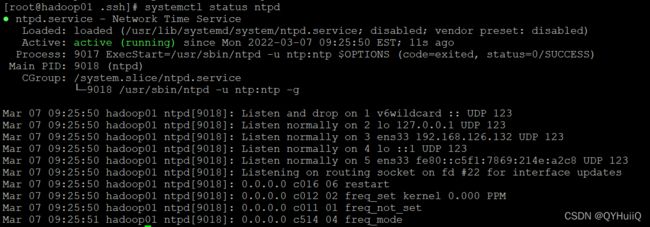
在02和03上安装ntpdate,同步01的时间并添加定时任务:
[root@hadoop02 .ssh]# yum install -y ntpdate
[root@hadoop02 .ssh]# ntpdate -u hadoop01
#添加定时任务使之定时去同步时间
[root@hadoop02 .ssh]# crontab -e
no crontab for root - using an empty one
crontab: installing new crontab、
#输入i转为编辑模式添加如下内容,* * * * *表示每分钟执行一次
[root@hadoop02 .ssh]# crontab -e
* * * * * /usr/sbin/ntpdate -u hadoop01 > /dev/null 2>&1
- 安装hadoop
[root@hadoop01 wyh]# tar -zxvf hadoop-2.7.5.tar.gz
#添加如下内容
[root@hadoop01 wyh]# vi /etc/profile
HADOOP_HOME=/usr/local/wyh/hadoop-2.7.5
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME PATH
#使配置生效
[root@hadoop01 wyh]# source /etc/profile
#查看hadoop版本验证安装成功
[root@hadoop01 wyh]# hadoop version
可以将上述操作在02和03上依次执行,也可以直接将解压后的安装包和修改后的/etc/profile文件scp传到另外两台机器上,但传过去之后还是要执行source命令使配置生效。
- 修改hadoop配置文件
在hadoop安装包下hadoop-2.7.5/share/doc/hadoop/xxxx中会有各个模块默认的xxxx-default.xml配置文件:
我们可以在代码中或xxx-site.xml文件中修改配置,这三处配置在真正生效时的优先级是:代码配置>xxx-site.xml>xxx-default.xml。
我们要修改的配置文件在/usr/local/wyh/hadoop-2.7.5/etc/hadoop目录下:
core-site.xml
fs.defaultFS
hdfs://hadoop01:8020
hadoop.tmp.dir
/usr/local/wyh/hadoop-2.7.5/tmp
hdfs-site.xml
dfs.namenode.name.dir
file://${hadoop.tmp.dir}/dfs/name
dfs.datanode.data.dir
file://${hadoop.tmp.dir}/dfs/data
dfs.replication
3
dfs.blocksize
134217728
dfs.namenode.secondary.http-address
hadoop02:50090
dfs.namenode.http-address
hadoop01:50070
mapred-site.xml
原始是mapred-site.xml.template文件,所以我们需要copy一份新的并重命名为mapred-site.xml。
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop01:10020
mapreduce.jobhistory.webapp.address
hadoop01:19888
yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop01
yarn.nodemanager.aux-services.mapreduce_shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
hadoop01:8032
yarn.resourcemanager.scheduler.address
hadoop01
yarn.resourcemanager.resource-tracker.address
hadoop01:8031
yarn.resourcemanager.admin.address
hadoop01:8033
yarn.resourcemanager.webapp.address
hadoop01:8088
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
640800
hadoop-env.sh
#修改JAVA_HOME
export JAVA_HOME=/usr/local/wyh/jdk1.8.0_311yarn-env.sh
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
#修改JAVA_HOOME
JAVA_HOME=/usr/local/wyh/jdk1.8.0_311
fi
slaves
#配置datanode节点
[root@hadoop01 hadoop]# cat slaves
hadoop01
hadoop02
hadoop03
回到上一级etc目录下,将刚才所做的这些配置文件的修改复制到另外两台节点上:
[root@hadoop01 etc]# scp -r hadoop/ hadoop02:$PWD
[root@hadoop01 etc]# scp -r hadoop/ hadoop03:$PWD
- 格式化集群
在主节点hadoop01上执行:
[root@hadoop01 ~]# hdfs namenode -format
格式化成功之后,就会发现在core-site.xml中我们配置的tmp.dir路径下创建好tmp目录:
- 启动集群
在主节点上使用启动脚本启动集群,这样会使整个集群中的三个节点都启动,启动NameNode/SecondaryNode/DataNode这几种角色的进程:
#启动与hdfs相关的进程
[root@hadoop01 current]# start-dfs.sh

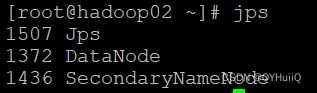
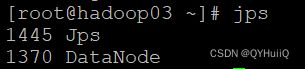
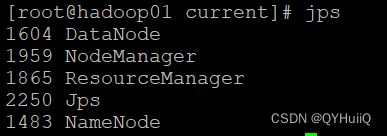
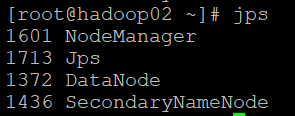
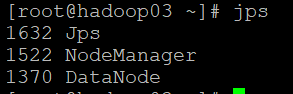
启动完成之后可以使用jps命令查看当前进程:

启动与yarn相关的进程,主要是ResourceManager/NodeManager:
[root@hadoop01 current]# start-yarn.sh

########################################################
如果想要一次性地把hdfs和yarn相关的进程全部启动,可以使用下面的命令(stop也是一样的):
[root@hadoop01 current]# start-all.sh
########################################################
启动成功后,可以在浏览器中访问web界面,这个地址和端口号在hdfs-site.xml中配置的dfs.namenode.http-address的值:
http://192.168.126.132:50070/
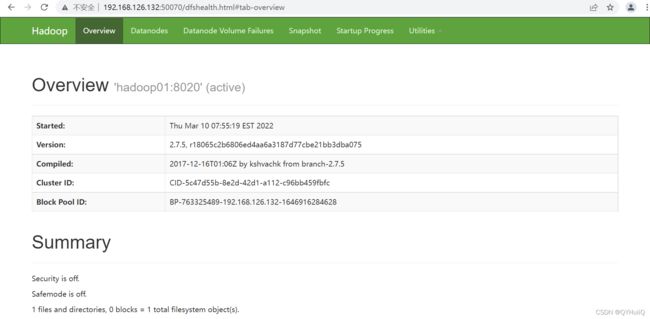
可以看到集群中的活跃节点数为3:
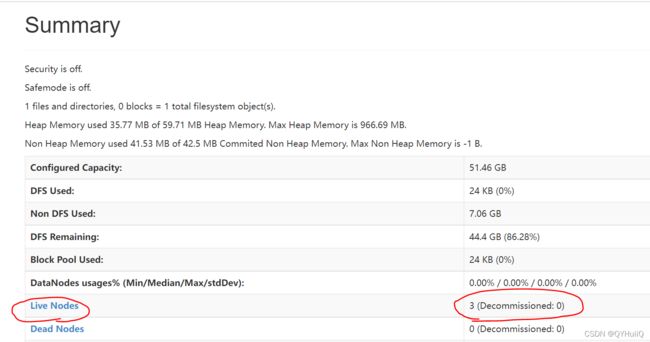
最后关闭集群:
[root@hadoop01 current]# stop-all.sh
以上就是搭建hadoop集群的简单实现全过程。