剪枝与重参第五课:前置知识
目录
- 前置知识
-
- 前言
- 1.CIFAR10数据集
-
- 1.1 简介
- 1.2 数据集的获取
- 1.3 数据集的加载
- 2.VGG网络搭建
-
- 2.1 VGGNet
- 2.2 VGG网络实现
- 3.Batch Normalize
-
- 3.1 简介
- 3.2 BN层实现
- 4.L1&L2正则
-
- 4.1 L1正则化(Lasso回归)
- 4.2 L2正则化(岭回归)
- 4.3 思考
- 5.train
-
- 5.1 parse_opt
- 5.2 train
- 5.3 test
- 5.4 save_checkpoint
- 5.5 完善示例代码
- 总结
前置知识
前言
手写AI推出的全新模型剪枝与重参课程。记录下个人学习笔记,仅供自己参考。
本次课程主要讲解实战的前置知识。
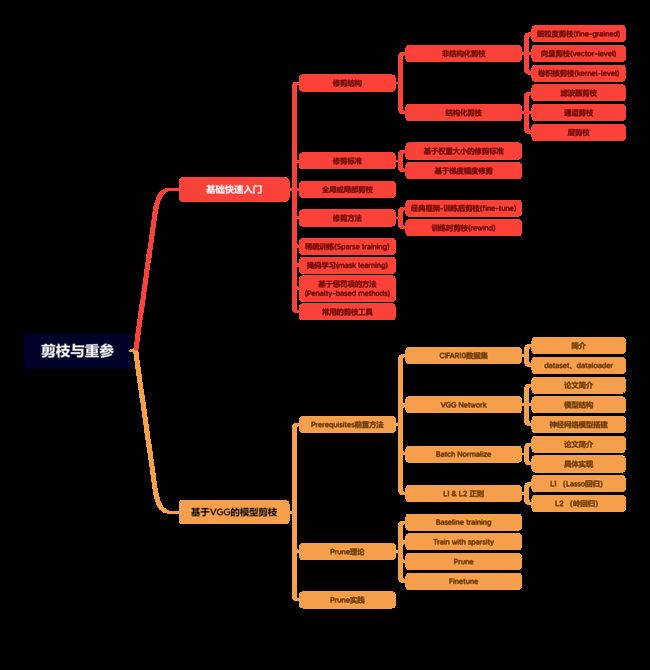
课程大纲可看下面的思维导图
1.CIFAR10数据集
1.1 简介
CIFAR10是一个广泛使用的图像分类数据集,由10个类别中的60000张32x32彩色图像组成,每个类别有6000张图像。其中50000张用于训练集,10000张用于测试集。该数据集中的图像均为低分辨率(32x32像素),使其称为一个小型但具有挑战性的数据集。
CIFAR10数据集的类别包括:airplane(飞机)、automobile(汽车)、bird(鸟)、cat(猫)、deer(鹿)、dog(狗)、frog(青蛙)、horse(马)、ship(船)和truck(卡车)。
下面是CIFAR10数据集中的一些简单示例图:

1.2 数据集的获取
CIFAR10官网提供了数据集的下载方式,在pytorch中也提供了关于数据集的下载:
import torchvision.datasets as datasets
train_set = datasets.CIFAR10(root='./data.cifar10', train=True, download=True)
运行上述代码后,在data.cifar10文件夹下有下载好的cifar-10-python.tar.gz压缩文件以及解压后的cifar-10-batchs-py文件,该文件夹下的内容有:
- batches.meta:包含一个Python字典,包含标签10个类别信息,每个batch的图片数量(10000),每张图片的像素个数(3072=32x32x3)
- data_batch_1 - data_batch_5:训练数据集,每个文件包含10000张图像和对应的标签
- readme.html:说明文档
- test.batch:测试数据集,包含10000张图像和对应的标签
每个数据文件都是一个二进制文件,可以使用Python的pickle模块进行读取和反序列化。每个数据文件包含一个Python字典,其中data键包含一个10000x3072的NumPy数组,其中每行表示一张图像的颜色通道值(32x32x3=1024个红色像素值+1024个绿色像素值+1024个蓝色像素值),以及一个label键包含与每个图像相关联的类别标签(0到9之间的整数)。
在读取数据集时,可以使用NumPy数组操作对图像数据进行处理和转换,并使用pickle模块对文件进行反序列化。也可以使用pytorch中的DataLoader对数据集进行加载。
1.3 数据集的加载
CIFAR10数据集加载的示例代码如下:
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
def create_train_loader(batch_size=16):
train_set = datasets.CIFAR10(root='./data.cifar10', train=True, download=True)
mean = train_set.data.mean(axis=(0,1,2)) / 255
std = train_set.data.std(axis=(0,1,2)) / 255
transforms_train = transforms.Compose([
transforms.Pad(4),
transforms.RandomCrop(32),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
train_set.transform = transforms_train
train_loader = DataLoader(dataset=train_set, batch_size=batch_size, shuffle=True)
return train_loader
def create_test_loader(batch_size=16):
test_set = datasets.CIFAR10(root='./data.cifar10', train=False, download=True)
mean = test_set.data.mean(axis=(0,1,2)) / 255
std = test_set.data.std(axis=(0,1,2)) / 255
transforms_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
test_set.transform = transforms_test
test_loader = DataLoader(dataset=test_set, batch_size=batch_size, shuffle=True)
return test_loader
if __name__ == "__main__":
train_loader = create_train_loader()
test_loader = create_test_loader()
import matplotlib.pyplot as plt
# 获取一个batch的数据
data_iter = iter(test_loader)
images, labels = data_iter.next()
# 将数据转换为numpy数组
images = images.numpy()
# 显示图片
fig, axes = plt.subplots(nrows=4, ncols=4, figsize=(10,10))
for i, ax in enumerate(axes.flat):
# 显示图片
ax.imshow(images[i].transpose(1,2,0))
# 设置标签
ax.set_title(f"Label: {labels[i]}")
# 隐藏坐标轴
ax.axis('off')
plt.show()
上述代码通过PyTorch库的torchvision.datasets来加载CIFAR10数据集,并使用transforms对图像进行预处理,然后使用torch.utils.data中的DataLoader创建数据加载器,最后显示了一个batch的图像数据。
2.VGG网络搭建
2.1 VGGNet
- 官方网站:Visual Geometry Group Home Page
- 相关论文:Very Deep Convolutional Networks For Large-scale Image Recognition (2015)
VGGNet是由牛津大学计算机视觉组于2014年提出的一个深度卷积神经网络,它获得了2014年ImageNet图像分类比赛的第二名。VGGNet的特点是采用了非常小的3x3卷积核,使用多个小卷积核来替代大的卷积核,增加网络的深度和非线性表达能力。VGGNet具有很好的可扩展性,可以通过添加更多的卷积层和全连接层来进一步提高网络的性能。VGGNet包含了几个不同深度和宽度的网络结构,其中最有名的是VGG16和VGG19,它们分别包含16和19个卷积层和全连接层。
VGGNet的网络结构非常简单,它包含了若干个卷积层和全连接层,其中卷积层包含了多个卷积核,每个卷积核的大小都是3x3。网络的最后一层是全连接层,用于将卷积层的输出映射到类别标签上。VGGNet的网络结构中,每个卷积层都采用了相同的结构,即两个3x3的卷积核,每个卷积核后面都跟了一个ReLU激活函数,最后是一个2x2的最大池化层。这个基本单元被称为VGG块,网络中的所有卷积层都由多个VGG块组成。
下图是VGG-16的网络结构图:

不同深度和宽度的VGG网络结构的配置信息如下:
defaultcfg = {
11 : [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512 ],
13 : [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512 ],
16 : [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512 ],
19 : [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512],
}
2.2 VGG网络实现
VGG网络搭建的示例代码如下:
import torch.nn as nn
defaultcfg = {
11 : [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512 ],
13 : [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512 ],
16 : [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512 ],
19 : [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512],
}
class VGG(nn.Module):
def __init__(self, num_classes=10, depth=11, cfg=None):
super().__init__()
if not cfg:
cfg = defaultcfg[depth]
self.features = self.make_layers(cfg)
self.classifier = nn.Linear(cfg[-1], num_classes)
def make_layers(self, cfg):
layers = []
in_channels = 3
for l in cfg:
if l == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, l, kernel_size=3, padding=1, bias=False)
layers += [conv2d, nn.BatchNorm2d(l), nn.ReLU(inplace=True)]
in_channels = l
return nn.Sequential(*layers)
def forward(self, x):
x = self.features(x)
x = nn.AvgPool2d(2)(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
if __name__ == "__main__":
vgg = VGG()
print(vgg)
我们搭建的VGG-11网络与原始的VGG网络不同,在features后采取的是AvgPool2d进行池化且为了简单化只使用了一个全连接层。
3.Batch Normalize
3.1 简介
- 相关论文:Batch Normalization- Accelerating Deep Network Training b y Reducing Internal Covariate Shift (2015)
- 知乎解读:Batch Normalization原理与实战
Batch Normalize(批标准化)是一种深度神经网络中常用的正则化方法,旨在缓解深度神经网络中梯度消失或梯度爆炸的问题,加速训练过程并提高模型的性能。
Batch Normalize在训练过程中,对每个 minibatch 的输出进行标准化,即对每个特征在 batch 维度上进行标准化,使得输出的均值和标准差分别为 0 和 1。这样做的好处在于,使得每个层的输入都是以相同的方式进行标准化,从而加速了训练过程。
具体来说,Batch Normalize 可以分为以下几个步骤:
-
对于输入特征 x x x,计算其均值 μ \mu μ 和标准差 σ \sigma σ。
-
标准化:将特征 x x x 标准化为 x ^ = x − μ σ 2 + ϵ \hat{x} = \frac{x-\mu}{\sqrt{\sigma^2+\epsilon}} x^=σ2+ϵx−μ,其中 ϵ \epsilon ϵ 是一个小的常数,防止除数为 0。
-
对标准化后的特征进行缩放和平移: B N ( x ) = γ x ^ + β BN(x) = \gamma\hat{x} + \beta BN(x)=γx^+β,其中 γ \gamma γ 和 β \beta β 是可学习的参数,使得模型可以自适应地选择适当的缩放和平移,从而提高模型的拟合能力。
-
对于每个 minibatch,通过梯度下降来更新 γ \gamma γ 和 β \beta β。
Batch Normalize在深度神经网络中广泛使用,可以使模型训练更加稳定和快速,从而提高模型的准确性。
3.2 BN层实现
BN层搭建的示例代码如下:
import torch
import torch.nn as nn
class BatchNorm(nn.Module):
def __init__(self, num_features, eps=1e-5, momentum=0.1):
super().__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
self.gamma = nn.Parameter(torch.ones(num_features))
self.beta = nn.Parameter(torch.zeros(num_features))
self.register_buffer('running_mean', torch.zeros(num_features))
self.register_buffer('running_var', torch.ones(num_features))
def forward(self, x):
if self.training:
mean = x.mean(dim=(0,2,3), keepdim=True)
var = x.var(dim=(0,2,3), keepdim=True)
self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * mean.squeeze()
self.running_var = (1 - self.momentum) * self.running_var + self.momentum * var.squeeze()
else:
mean = self.running_mean.unsqueeze(0).unsqueeze(-1).unsqueeze(-1)
var = self.running_var.unsqueeze(0).unsqueeze(-1).unsqueeze(-1)
x = (x - mean) / torch.sqrt(var + self.eps)
x = x * self.gamma.unsqueeze(-1).unsqueeze(-1) + self.beta.unsqueeze(-1).unsqueeze(-1)
return x
上面的示例代码用于实现Batch Normalize,主要有以下几点说明:
- 由于
self.gamma和self.beta都是可学习的参数,其值需要在训练过程中被更新,因此它们被定义为nn.Parameter对象。nn.Parameter是Tensor的子类,它的主要作用是为了将一个Tensor封装成一个 Parameter对象。这样做的好处是,将一个Tensor封装成Parameter对象后,该Tensor会被自动注册为模型的参数,可以被自动更新。 register_buffer是nn.Module类中的一个方法,它用于注册一个持久化的buffer,该buffer不需要梯度,且在调用to()方法时会自动将其移动到相应的设备上。在Batch Normalization中,running_mean和running_var是在训练过程中不断更新的均值和方差,它们需要在每次前向传播时被保存下来。因此,将它们注册为buffer可以保证它们被自动保存和移动到正确的设备上,而且不会被当做模型参数进行优化。- 对于CNN而言,输入的数据一般是4D的张量即(batch,channels,height,weight),对于每个channel,需要对batch个样本求均值和方差,所以求取mean和var是(0,2,3)。至于
keepdim=True的含义是指在求取均值和方差时是否保持维度不变。如果keepdim=True,则均值和方差张量的维度与输入张量维度相同,否则在求均值和方差时会进行降维操作。在Batch Normalization中,keepdim=True是为了保证均值和方差张量的维度与gamma和beta张量的维度相同,从而能够进行后续的运算。 running_mean和running_var的计算方式是对每个Batch的均值和方差进行动量平均。在新的Batch到来时,运用动量平均,将原有running_mean和新的均值进行一定比例的加权平均,以此来逐步调整整个数据集的分布,从而更好地适应新的数据分布。这样做的目的是在训练过程中更好地适应不同的数据分布,从而提高网络的泛化能力。其中动量momentum为0.1是较为常见的选择squeeze()表示将tensor维度为1的维度去掉。在BatchNorm的实现中,mean和var计算得到的是形状为(1,C,1,1)的tensor,其中C为特征的通道数。使用squeeze()可以将tensor的形状变为(C,),方便后续计算。unsqueeze()是PyTorch中用于增加维度的方法,它的作用是在指定的维度上增加一个维度,其参数是增加的维度的索引。
4.L1&L2正则
- 知乎解读:L1 相比于 L2 为什么容易获得稀疏解?
- 知乎解读:L1 正则与 L2 正则的特点是什么,各有什么优势?
- 知乎解读:L1 正则化与 L2 正则化
我们所说的正则化,就是在原来的Loss Function的基础上,加上了一些正则化项或者称为模型复杂度惩罚项
Loss Function
L ( w ) = 1 N ∗ ∑ i = 1 N ( y i − w T x i ) 2 L(w) = \frac{1}{N} *\sum\limits^{N}_{i=1}(y_i - w^Tx_i)^2 L(w)=N1∗i=1∑N(yi−wTxi)2
假设 L ( w ) L(w) L(w)在0处的导数为0,即达到最优解:
∂ L ( w ) ∂ w ∣ w = 0 = d = 0 \frac{\partial L(w)}{\partial w}\Bigm|_{w=0} = d = 0 ∂w∂L(w) w=0=d=0
4.1 L1正则化(Lasso回归)
-
加上L1正则项(Lasso 回归): C ∣ ∣ w ∣ ∣ 1 C||w||_1 C∣∣w∣∣1
-
损失函数:
L L 1 ( w ) = L ( w ) + λ ∣ w ∣ L_{L1}(w)= L(w) + \lambda|w| LL1(w)=L(w)+λ∣w∣
-
导数:
∂ L ( w ) ∂ w ∣ w = 0 − = d − λ \frac{\partial L(w)}{\partial w} \Bigm|_{w=0^-} = d - \lambda ∂w∂L(w) w=0−=d−λ
∂ L ( w ) ∂ w ∣ w = 0 + = d + λ \frac{\partial L(w)}{\partial w} \Bigm|_{w=0^+} = d + \lambda ∂w∂L(w) w=0+=d+λ
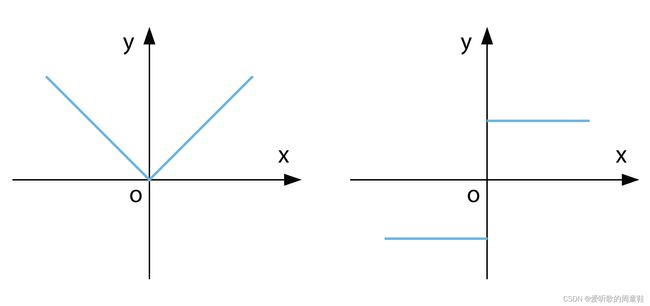
- 在剪枝中,L1正则化会用在Batch Normalization上面的 γ \gamma γ上面,实现稀疏训练
4.2 L2正则化(岭回归)
-
加上L2正则项(岭回归): C ∣ ∣ w ∣ ∣ 2 2 C||w||^2_2 C∣∣w∣∣22
-
损失函数:
L L 2 ( w ) = L ( w ) + λ w 2 L_{L2}(w) = L(w)+ \lambda w^2 LL2(w)=L(w)+λw2
-
导数:
∂ L ( w ) ∂ w ∣ w = 0 = d + 2 λ w = 0 \frac{\partial L(w)}{\partial w} \Bigm|_{w=0} = d + 2\lambda w =0 ∂w∂L(w) w=0=d+2λw=0
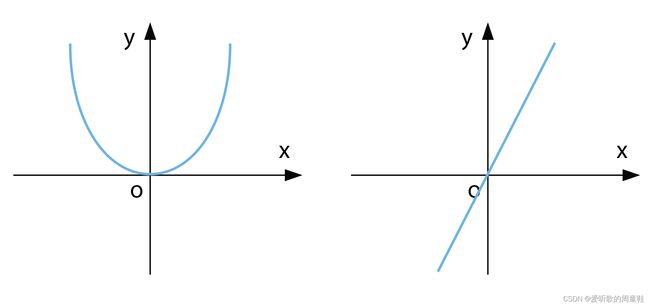
4.3 思考
问题1:为什么使用L1正则化可以实现稀疏训练?
L1正则化是一种对模型权重进行惩罚的方法,它将权重中的小值变为0,从而实现模型的稀疏化。在Batch Normalization中, γ \gamma γ是缩放因子,它用于缩放归一化的输出,而且 γ \gamma γ的初始值通常被设置为1,如果对其进行L1正则化惩罚,会使得模型更倾向于将一些通道的权重设置为0,从而实现通道的剪枝,减少模型参数量和计算量。因此,在剪枝中,L1正则化被广泛应用于Batch Normalization的缩放因子 γ \gamma γ上。(from chatGPT)
问题2:为什么使用L1正则化不使用L2正则化?
L1正则化在想要寻找一个能够大幅减少权值数量的最优解时很有用。L1正则化对权值施加的惩罚不像L2正则化那样平滑,它倾向于让一些权值变为0。对于 γ \gamma γ系数,因为它们的值用于调节每个通道的缩放因子,使其接近于1,而一些通道的重要性可能不如其他通道。因此,使用L1正则化有助于找到仅仅使用少量通道可以获得相同性能的 γ \gamma γ系数。而L2正则化倾向于使得所有 γ \gamma γ系数都很小但非零。因此,在使用L1正则化时,可以通过稀疏化权重获得一些模型压缩和加速的好处。(from chatGPT)
5.train
模型稀疏训练具体实现流程
5.1 parse_opt
利用argparse命令行参数解析模块传入模型训练时的参数,示例代码如下:
import argparse
def parse_opt():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch Slimming CIFAR training')
parser.add_argument('--dataset', type=str, default='cifar100', help='training dataset (default: cifar100)')
parser.add_argument('--sparsity-regularization', '-sr', dest='sr', action='store_true', help='train with channel sparsity regularization')
parser.add_argument('--s', type=float, default=0.0001, help='scale sparse rate (default: 0.0001)')
parser.add_argument('--refine', default='', type=str, metavar='PATH', help='path to the pruned model to be fine tuned')
parser.add_argument('--batch-size', type=int, default=64, metavar='N', help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=256, metavar='N', help='input batch size for testing (default: 256)')
parser.add_argument('--epochs', type=int, default=160, metavar='N', help='number of epochs to train (default: 160)')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N', help='manual epoch number (useful on restarts)')
parser.add_argument('--lr', type=float, default=0.1, metavar='LR', help='learning rate (default: 0.1)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M', help='SGD momentum (default: 0.9)')
parser.add_argument('--weight-decay', '--wd', default=1e-4, type=float, metavar='W', help='weight decay (default: 1e-4)')
parser.add_argument('--resume', default='', type=str, metavar='PATH', help='path to latest checkpoint (default: none)')
parser.add_argument('--no-cuda', action='store_true', default=False, help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S', help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=100, metavar='N', help='how many batches to wait before logging training status')
parser.add_argument('--save', default='./logs', type=str, metavar='PATH', help='path to save prune model (default: current directory)')
parser.add_argument('--arch', default='vgg', type=str, help='architecture to use')
parser.add_argument('--depth', default=19, type=int, help='depth of the neural network')
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_opt()
print(args)
5.2 train
训练函数实现的示例代码如下:
import argparse
from models import VGG
from utils import create_train_loader
import torch
import torch.optim as optim
import torch.nn.functional as F
import torch.nn as nn
def parse_opt():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch Slimming CIFAR training')
parser.add_argument('--dataset', type=str, default='cifar100', help='training dataset (default: cifar100)')
parser.add_argument('--sparsity-regularization', '-sr', dest='sr', action='store_true', help='train with channel sparsity regularization')
parser.add_argument('--s', type=float, default=0.0001, help='scale sparse rate (default: 0.0001)')
parser.add_argument('--refine', default='', type=str, metavar='PATH', help='path to the pruned model to be fine tuned')
parser.add_argument('--batch-size', type=int, default=64, metavar='N', help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=256, metavar='N', help='input batch size for testing (default: 256)')
parser.add_argument('--epochs', type=int, default=160, metavar='N', help='number of epochs to train (default: 160)')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N', help='manual epoch number (useful on restarts)')
parser.add_argument('--lr', type=float, default=0.1, metavar='LR', help='learning rate (default: 0.1)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M', help='SGD momentum (default: 0.9)')
parser.add_argument('--weight-decay', '--wd', default=1e-4, type=float, metavar='W', help='weight decay (default: 1e-4)')
parser.add_argument('--resume', default='', type=str, metavar='PATH', help='path to latest checkpoint (default: none)')
parser.add_argument('--no-cuda', action='store_true', default=False, help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S', help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=100, metavar='N', help='how many batches to wait before logging training status')
parser.add_argument('--save', default='./logs', type=str, metavar='PATH', help='path to save prune model (default: current directory)')
parser.add_argument('--arch', default='vgg', type=str, help='architecture to use')
parser.add_argument('--depth', default=19, type=int, help='depth of the neural network')
args = parser.parse_args()
return args
def updateBN():
# 更新Batch Normalization中的gamma参数,使用L1正则化来实现稀疏训练
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
m.weight.grad.data.add_(args.s * torch.sign(m.weight.data))
def train(epoch):
model.train() # 将模型设置训练模式
for batch_idx, (data, target) in enumerate(train_loader):
if args.cuda:
data, target = data.cuda(), target.cuda()
optimizer.zero_grad() # 梯度清零
output = model(data) # 前向传播
loss = F.cross_entropy(output, target)
loss.backward() #反向传播
if args.sr:
updateBN() # 稀疏训练,更新BN层的gamma参数
optimizer.step() # 参数更新
if batch_idx % args.log_interval == 0: # 消息打印
print('Train Epoch: {} [{}/{} ({:.1f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data),
len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.item()))
if __name__ == '__main__':
args = parse_opt()
args.cuda = not args.no_cuda and torch.cuda.is_available()
model = VGG()
if args.cuda:
model.cuda()
train_loader = create_train_loader()
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
train(epoch=1)
5.3 test
测试函数实现的示例代码如下:
def test():
model.eval() # 将模型设置为测试模式
test_loss = 0
correct = 0
with torch.no_grad(): # 不进行梯度计算
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
output = model(data) # 前向传播得到预测结果
test_loss = F.cross_entropy(output, target, reduction='sum').item() # 计算损失
pred = output.data.max(1, keepdim=True)[1] # 获取预测类别
correct += pred.eq(target.data.view_as(pred)).cpu().sum() # 统计正确的数量
test_loss /= len(test_loader.dataset) # 计算平均损失
# 打印测试结果
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.1f}%)\n'.format(
test_loss, correct,
len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
return correct / float(len(test_loader.dataset)) # 返回测试准确率
5.4 save_checkpoint
保存模型的示例代码如下:
import os
import shutil
def save_checkpoint(state, is_best, filepath):
torch.save(state, os.path.join(filepath, 'checkpoint.pth'))
if is_best:
shutil.copyfile(os.path.join(filepath, 'checkpoint.pth'), os.path.join(filepath, 'model_best.pth'))
5.5 完善示例代码
完整的train.py示例代码如下:
import os
import torch
import argparse
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from models.vgg import VGG
from utils import get_training_dataloader, get_test_dataloader, save_checkpoint
def parse_opt():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch Slimming CIFAR training')
parser.add_argument('--dataset', type=str, default='cifar10', help='training dataset (default: cifar100)')
parser.add_argument('--sparsity-regularization', '-sr', dest='sr', action='store_true', help='train with channel sparsity regularization')
parser.add_argument('--s', type=float, default=0.0001, help='scale sparse rate (default: 0.0001)')
parser.add_argument('--refine', default='', type=str, metavar='PATH', help='path to the pruned model to be fine tuned')
parser.add_argument('--batch-size', type=int, default=64, metavar='N', help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=256, metavar='N', help='input batch size for testing (default: 256)')
parser.add_argument('--epochs', type=int, default=160, metavar='N', help='number of epochs to train (default: 160)')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N', help='manual epoch number (useful on restarts)')
parser.add_argument('--lr', type=float, default=0.1, metavar='LR', help='learning rate (default: 0.1)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M', help='SGD momentum (default: 0.9)')
parser.add_argument('--weight-decay', '--wd', default=1e-4, type=float, metavar='W', help='weight decay (default: 1e-4)')
parser.add_argument('--resume', default='', type=str, metavar='PATH', help='path to latest checkpoint (default: none)')
parser.add_argument('--no-cuda', action='store_true', default=False, help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S', help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=100, metavar='N', help='how many batches to wait before logging training status')
parser.add_argument('--save', default='./logs', type=str, metavar='PATH', help='path to save prune model (default: current directory)')
parser.add_argument('--arch', default='vgg', type=str, help='architecture to use')
parser.add_argument('--depth', default=19, type=int, help='depth of the neural network')
args = parser.parse_args()
return args
# additional subgradient descent on the sparsity-induced penalty term
def updateBN():
for m in model.modules():
# Check if the module is a BatchNorm2d layer
if isinstance(m, nn.BatchNorm2d):
# Calculate the L1 regularization term and add it to the weight gradients
# args.s is a scalar value that determines the strength of the regularization
# torch.sign(m.weight.data) returns the sign of the weight parameters
m.weight.grad.data.add_(args.s*torch.sign(m.weight.data)) # L1
def train(epoch):
# Set the model to training mode
model.train()
# Loop through the batches in the training data
for batch_idx, (data, target) in enumerate(train_loader):
# Move the data and target tensors to the GPU if args.cuda is True
if args.cuda:
data, target = data.cuda(), target.cuda()
# Zero out the gradients in the optimizer
optimizer.zero_grad()
# Forward pass: compute the output of the model on the input data
output = model(data)
# Compute the loss between the output and target labels
loss = F.cross_entropy(output, target)
# Backward pass: compute the gradients of the loss w.r.t. the model parameters
loss.backward()
# If args.sr is True, apply L1 regularization to the Batch Normalization layers
if args.sr:
updateBN()
# Update the model parameters using the optimizer
optimizer.step()
# Print the training loss and progress at regular intervals
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.1f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data),
len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.item()))
def test():
# Set the model to evaluation mode
model.eval()
# Initialize test loss and correct predictions
test_loss = 0
correct = 0
# Turn off gradient calculation during inference
with torch.no_grad():
# Loop through the test data
for data, target in test_loader:
# Move the data and target tensors to the GPU if args.cuda is True
if args.cuda:
data, target = data.cuda(), target.cuda()
# Compute the output of the model on the input data
output = model(data)
# Compute the test loss and add it to the running total
test_loss += F.cross_entropy(output, target, reduction='sum').item()
# Compute the predictions from the output using the argmax operation
pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
# Compute the number of correct predictions and add it to the running total
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
# Compute the average test loss and accuracy
test_loss /= len(test_loader.dataset)
# Print the test results
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.1f}%)\n'.format(
test_loss, correct,
len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
return correct / float(len(test_loader.dataset))
if __name__ == '__main__':
# Parse command line arguments
args = parse_opt()
# Check if CUDA is available and set args.cuda flag accordingly
args.cuda = not args.no_cuda and torch.cuda.is_available()
# Set the random seed for PyTorch and CUDA if args.cuda is True
torch.manual_seed(args.seed)
if args.cuda:
torch.cuda.manual_seed(args.seed)
# Create the save directory if it does not exist
if not os.path.exists(args.save):
os.makedirs(args.save)
# Set kwargs to num_workers=1 and pin_memory=True if args.cuda is True,
# otherwise kwargs is an empty dictionary
kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
# Create data loaders for the CIFAR10 dataset
# using the get_training_dataloader() and get_test_dataloader() functions
if args.dataset == 'cifar10':
train_loader = get_training_dataloader(batch_size=args.batch_size, **kwargs)
test_loader = get_test_dataloader(batch_size=args.test_batch_size, **kwargs)
# Load a pre-trained VGG model if args.refine is not None,
# otherwise create a new VGG model
if args.refine:
checkpoint = torch.load(args.refine)
model = VGG(depth=args.depth, cfg=checkpoint['cfg'])
model.load_state_dict(checkpoint['state_dict'])
else:
model = VGG(depth=args.depth)
# Move the model to the GPU if args.cuda is True
if args.cuda:
model.cuda()
# Set up the optimizer with Stochastic Gradient Descent (SGD)
# and the specified learning rate, momentum, and weight decay
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay)
if args.resume:
# Check if the checkpoint file exists
if os.path.isfile(args.resume):
# If the checkpoint file exists, print a message indicating that it's being loaded
print("=> loading checkpoint '{}'".format(args.resume))
# Load the checkpoint file
checkpoint = torch.load(args.resume)
# Update the start epoch and best precision variables from the checkpoint
args.start_epoch = checkpoint['epoch']
best_prec1 = checkpoint['best_prec1']
# Load the model state dictionary and optimizer state dictionary from the checkpoint
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
# Print a message indicating that the checkpoint has been loaded
print("=> loaded checkpoint '{}' (epoch {}) Prec1: {:f}"
.format(args.resume, checkpoint['epoch'], best_prec1))
else:
# If the checkpoint file does not exist, print an error message
print("=> no checkpoint found at '{}'".format(args.resume))
# Initialize the best test accuracy to 0
best_prec1 = 0.
# Loop through the epochs, starting from args.start_epoch and continuing until args.epochs
for epoch in range(args.start_epoch, args.epochs):
# If the current epoch is at 50% or 75% of the total epochs,
# reduce the learning rate by a factor of 10
if epoch in [args.epochs*0.5, args.epochs*0.75]:
for param_group in optimizer.param_groups:
param_group['lr'] *= 0.1
# Train the model on the training data for the current epoch
train(epoch)
# Evaluate the model on the test data and compute the top-1 test accuracy
prec1 = test()
# Check if the current test accuracy is better than the previous best test accuracy
is_best = prec1 > best_prec1
# Update the best test accuracy and save a checkpoint of the model and optimizer state
best_prec1 = max(prec1, best_prec1)
save_checkpoint({
'epoch': epoch + 1,
'state_dict': model.state_dict(),
'best_prec1': best_prec1,
'optimizer': optimizer.state_dict(),
}, is_best, filepath=args.save)
# Print the best test accuracy achieved during training
print("Best accuracy: "+str(best_prec1))
总结
本次剪枝课程主要学习了实战的前置知识,认识了CIFAR10数据集,并搭建了经典的VGG网络,同时学习了Batch Normalize,并对BN层的gamma参数进行L1正则化进行稀疏训练,最后实现了VGG网络模型稀疏训练CIFAR10具体实现流程。