EfficientNet(ICML 2019)原理与代码解析
paper:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
code:mmclassification/efficientnet.py at master · open-mmlab/mmclassification · GitHub
背景
扩展scale up卷积网络被广泛用来获得更好的精度,比如ResNet可以通过堆叠更多的卷积层从ResNet-18扩展到ResNet-200。而缩小卷积网络则可以减小计算量获得更快的推理速度。常用的缩放维度包括深度depth、宽度channel和输入图像大小resolution。在之前的缩放方法中,通常只缩放三个维度中的一个,虽然可以任意的缩放两个或三个维度,但任意缩放需要繁琐的手工调参,而且通常仍然只能得到次优的精度和效率。
本文的创新点
本文通过研究发现平衡深度、宽度、分辨率三个维度非常重要,并且发现这种平衡可以通过一个常量缩放因子来实现。基于此提出了一种复合缩放方法compound scaling method,与传统的任意缩放某个维度的方法不同,该方法用一组固定的缩放系数均匀地同时缩放三个维度。例如,如果我们想要用 \(2^{N}\) 倍的计算资源,可以简单地通过系数 \(\alpha^{N},\beta^{N},\gamma^{N}\) 来分别增加网络的深度、宽度、分辨率。其中 \(\alpha,\beta,\gamma\) 是常量系数,通过在原始的基础模型上通过网格搜索得到。
此外,缩放方法的有效性很大程度上取决于baseline模型,因此作者通过neural architecture search设计了一个新的基线模型,然后通过本文的缩放方法得到了一系列的模型EfficientNets。
方法介绍
作者根据经验观察到不同尺度的维度之间并不是相互独立的,对于更高分辨率的输入,应该增加网络深度来得到更大的感受野,并且需要更多的通道来提取更细粒的特征模式。因此在缩放时,应该协调和平衡好三个维度之间的关系,而不是只缩放其中一个维度。
本文提出一个复合缩放方法,利用符合系数 \(\phi\) 来统一的缩放深度、宽度、分辨率:

其中 \(\alpha,\beta,\gamma\) 是常量系数,通过在原始的基础模型上通过网格搜索得到。\(\phi\) 是用户指定的系数,用来控制模型有多少可用的计算资源。本文作者限制 \(\alpha \cdot \beta ^{2} \cdot \gamma ^{2}\approx 2\),从而对于任意的 \(\phi\) 值,模型的FLOPS大约增加 \(2^{\phi}\) 倍。作者通过NAS得到了一个新的baseline模型EfficientNet-B0,结构如下
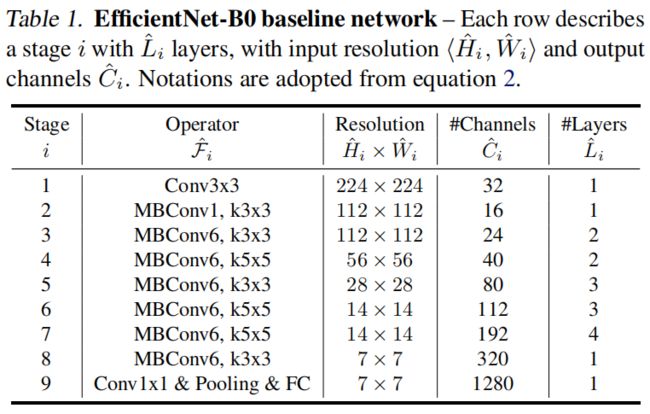
其中的MBConv和MobileNet v3中的InvertedResidualBlock类似,只不过换了激活函数并且加入了SE模块。
通过固定 \(\phi=1\),然后在B0上进行网格搜索得到最优值 \(\alpha=1.2,\beta=1.1,\gamma=1.15\)。然后固定 \(\alpha,\beta,\gamma\),通过式(3)调整 \(\phi\) 值大小,得到EfficientNet-B1~B7。
实验结果
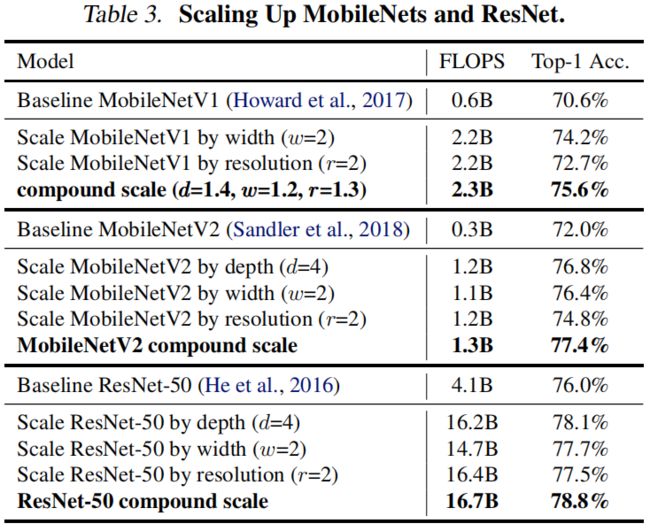
作者首先在MobileNets和ResNets上验证了本文提出的复合缩放方法,结果如下,可以看出,与之前只缩放一个维度相比,本文提出的复合缩放方法在相似的FLOPS下均获得了最高的精度。
然后作者比较了EfficientNet-B0~B7和其它模型在ImageNet上的精度,结果如下,可以看出,和不同大小的模型相比,在相似的精度下,EfficientNet的FLOPS降低了2.6~8.4倍。

代码解析
这里以mmclassification中的实现为例,首先定义了layer_settings和arch_settings,layer_settings是网络层结构的配置,'b'指的是上面的B0~B7,这里默认为基线模型B0,即Tabel 1中的结构。注意,表1中一共9个stage,而这里len(layer_settings)==7是因为将stage56合并为一层,stage78合并为一层。'e'是EdgeTPU的结构,这里不做介绍。arch_settings是缩放系数的配置,分别为width、depth的缩放因子和输入图片大小。这里没有按文中给出B0~B7具体的 \(\phi\) 值,让我们自己根据 \(\alpha,\beta,\gamma\) 计算,而是直接给出了计算好的结果,实际的 \(\phi\) 值也并不是按B0~B7对应为0~7。
# Parameters to build layers.
# 'b' represents the architecture of normal EfficientNet family includes
# 'b0', 'b1', 'b2', 'b3', 'b4', 'b5', 'b6', 'b7', 'b8'.
# 'e' represents the architecture of EfficientNet-EdgeTPU including 'es',
# 'em', 'el'.
# 6 parameters are needed to construct a layer, From left to right:
# - kernel_size: The kernel size of the block
# - out_channel: The number of out_channels of the block
# - se_ratio: The sequeeze ratio of SELayer.
# - stride: The stride of the block
# - expand_ratio: The expand_ratio of the mid_channels
# - block_type: -1: Not a block, 0: InvertedResidual, 1: EdgeResidual
layer_settings = {
'b': [[[3, 32, 0, 2, 0, -1]],
[[3, 16, 4, 1, 1, 0]],
[[3, 24, 4, 2, 6, 0],
[3, 24, 4, 1, 6, 0]],
[[5, 40, 4, 2, 6, 0],
[5, 40, 4, 1, 6, 0]],
[[3, 80, 4, 2, 6, 0],
[3, 80, 4, 1, 6, 0],
[3, 80, 4, 1, 6, 0],
[5, 112, 4, 1, 6, 0],
[5, 112, 4, 1, 6, 0],
[5, 112, 4, 1, 6, 0]],
[[5, 192, 4, 2, 6, 0],
[5, 192, 4, 1, 6, 0],
[5, 192, 4, 1, 6, 0],
[5, 192, 4, 1, 6, 0],
[3, 320, 4, 1, 6, 0]],
[[1, 1280, 0, 1, 0, -1]]
],
'e': [[[3, 32, 0, 2, 0, -1]],
[[3, 24, 0, 1, 3, 1]],
[[3, 32, 0, 2, 8, 1],
[3, 32, 0, 1, 8, 1]],
[[3, 48, 0, 2, 8, 1],
[3, 48, 0, 1, 8, 1],
[3, 48, 0, 1, 8, 1],
[3, 48, 0, 1, 8, 1]],
[[5, 96, 0, 2, 8, 0],
[5, 96, 0, 1, 8, 0],
[5, 96, 0, 1, 8, 0],
[5, 96, 0, 1, 8, 0],
[5, 96, 0, 1, 8, 0],
[5, 144, 0, 1, 8, 0],
[5, 144, 0, 1, 8, 0],
[5, 144, 0, 1, 8, 0],
[5, 144, 0, 1, 8, 0]],
[[5, 192, 0, 2, 8, 0],
[5, 192, 0, 1, 8, 0]],
[[1, 1280, 0, 1, 0, -1]]
]
} # yapf: disable
# Parameters to build different kinds of architecture.
# From left to right: scaling factor for width, scaling factor for depth,
# resolution.
arch_settings = {
'b0': (1.0, 1.0, 224),
'b1': (1.0, 1.1, 240),
'b2': (1.1, 1.2, 260),
'b3': (1.2, 1.4, 300),
'b4': (1.4, 1.8, 380),
'b5': (1.6, 2.2, 456),
'b6': (1.8, 2.6, 528),
'b7': (2.0, 3.1, 600),
'b8': (2.2, 3.6, 672),
'es': (1.0, 1.0, 224),
'em': (1.0, 1.1, 240),
'el': (1.2, 1.4, 300)
}函数model_scaling是根据缩放系数去调整对应的维度,实现如下,其中做了一些注释。
def model_scaling(layer_setting, arch_setting):
"""Scaling operation to the layer's parameters according to the
arch_setting."""
# scale width
new_layer_setting = copy.deepcopy(layer_setting)
for layer_cfg in new_layer_setting:
for block_cfg in layer_cfg:
block_cfg[1] = make_divisible(block_cfg[1] * arch_setting[0], 8)
# scale depth
split_layer_setting = [new_layer_setting[0]]
for layer_cfg in new_layer_setting[1:-1]: # 只scale中间的MBConv
tmp_index = [0]
for i in range(len(layer_cfg) - 1):
if layer_cfg[i + 1][1] != layer_cfg[i][1]:
tmp_index.append(i + 1)
tmp_index.append(len(layer_cfg))
# [0,1],[0,2],[0,2],[0,3,6],[0,4,5]
for i in range(len(tmp_index) - 1):
split_layer_setting.append(layer_cfg[tmp_index[i]:tmp_index[i +
1]])
split_layer_setting.append(new_layer_setting[-1])
# 原始的layer_setting把论文中stage56合并,78合并,这里又还原回去,一共9个stage
# [[[3, 32, 0, 2, 0, -1]],
# [[3, 16, 4, 1, 1, 0]],
# [[3, 24, 4, 2, 6, 0],
# [3, 24, 4, 1, 6, 0]],
# [[5, 40, 4, 2, 6, 0],
# [5, 40, 4, 1, 6, 0]],
# [[3, 80, 4, 2, 6, 0],
# [3, 80, 4, 1, 6, 0],
# [3, 80, 4, 1, 6, 0]],
# [[5, 112, 4, 1, 6, 0],
# [5, 112, 4, 1, 6, 0],
# [5, 112, 4, 1, 6, 0]],
# [[5, 192, 4, 2, 6, 0],
# [5, 192, 4, 1, 6, 0],
# [5, 192, 4, 1, 6, 0],
# [5, 192, 4, 1, 6, 0]],
# [[3, 320, 4, 1, 6, 0]],
# [[1, 1280, 0, 1, 0, -1]]]
num_of_layers = [len(layer_cfg) for layer_cfg in split_layer_setting[1:-1]] # [1,2,2,3,3,4,1]
new_layers = [
int(math.ceil(arch_setting[1] * num)) for num in num_of_layers
] # 层数向上取ceil
merge_layer_setting = [split_layer_setting[0]]
for i, layer_cfg in enumerate(split_layer_setting[1:-1]):
if new_layers[i] <= num_of_layers[i]: # 因为b1的depth scale系数都等于1.1,后面的更大,并且层数取ceil,所以这里进不来
tmp_layer_cfg = layer_cfg[:new_layers[i]]
else:
tmp_layer_cfg = copy.deepcopy(layer_cfg) + [layer_cfg[-1]] * (
new_layers[i] - num_of_layers[i]) # 一个stage中除了第一层的stride有可能不一样,所有层的配置都是一样的。这里扩充的层都是stage的最后一层。
if tmp_layer_cfg[0][3] == 1 and i != 0: # 这里相当于又把stage56合并,78合并了
merge_layer_setting[-1] += tmp_layer_cfg.copy()
else:
merge_layer_setting.append(tmp_layer_cfg.copy())
merge_layer_setting.append(split_layer_setting[-1])
# ## b1, depth scale factor = 1.1
# [[[3, 32, 0, 2, 0, -1]],
# [[3, 16, 4, 1, 1, 0],
# [3, 16, 4, 1, 1, 0]],
# [[3, 24, 4, 2, 6, 0],
# [3, 24, 4, 1, 6, 0],
# [3, 24, 4, 1, 6, 0]],
# [[5, 40, 4, 2, 6, 0],
# [5, 40, 4, 1, 6, 0],
# [5, 40, 4, 1, 6, 0]],
# [[3, 80, 4, 2, 6, 0],
# [3, 80, 4, 1, 6, 0],
# [3, 80, 4, 1, 6, 0],
# [3, 80, 4, 1, 6, 0],
# [5, 112, 4, 1, 6, 0],
# [5, 112, 4, 1, 6, 0],
# [5, 112, 4, 1, 6, 0],
# [5, 112, 4, 1, 6, 0]],
# [[5, 192, 4, 2, 6, 0],
# [5, 192, 4, 1, 6, 0],
# [5, 192, 4, 1, 6, 0],
# [5, 192, 4, 1, 6, 0],
# [5, 192, 4, 1, 6, 0],
# [3, 320, 4, 1, 6, 0],
# [3, 320, 4, 1, 6, 0]],
# [[1, 1280, 0, 1, 0, -1]]]
return merge_layer_setting最后根据实际的结构去搭建网络就好了,其中MBConv就是MobileNet v3中的InvertedResidualBlock,加上了SE模块,激活函数换成Swish。