数据挖掘分类算法的学习总结
一、中文摘要
大数据时代的我们每时每刻都在产生海量数据,如何快速准确获取其中有价值的数据一直是亟待解决的问题。数据挖掘技术的应运而生为该问题提供了解决手段,作为数据挖掘核心内容之一的分类算法同样发挥了至关重要的作用。本文主要对数据挖掘分类算法进行研究,介绍了常用分类算法的基本思想及其优缺点,有助于未来对算法进行相应的改进,再通过其部分实际应用展示了在不同领域中分类算法的良好分类效果。
关键词: 课程论文;研究生课程;数据管理;数据挖掘;分类算法
二、英文摘要
In the era of big data, we are generating massive data all the time. How to obtain valuable data quickly and accurately has always been an urgent problem to be solved. The emergence of data mining technology provides a means to solve this problem. As one of the core contents of data mining, classification algorithms also plays a vital role. This paper mainly studies the classification algorithms of data mining, introduces the basic ideas and advantages and disadvantages of common classification algorithms, which is helpful for the improvement of the algorithm in the future, and then shows the good classification effect of the classification algorithms in different fields through some practical applications.
Key words: course paper; graduate course; data management; data mining; algorithms of classification
三、引言
随着计算机技术的飞速发展和数据的爆炸式增长,让我们生活在一个数据时代。每天面对着质量参差不齐的海量数据,如何从中获取我们需要的数据,提高数据的查询速度和利用率一直是我们需要解决的问题。数据挖掘技术(Data Mining,DM)由此应运而生,可以帮助我们从海量数据中发现有价值的数据。简单理解,数据挖掘是融合了机器学习技术和数据库技术的一种在海量数据中寻找有用数据的过程,存储数据使用数据库技术,分析数据使用机器学习技术。数据挖掘被定义为“从数据库中的数据识别有效的、新颖的、先前未知的、潜在可用的信息以及最终可理解的模式的非核过程”[1]。
数据分类算法是数据挖掘的核心内容,其主要作用是通过对大量数据进行运算,提取有价值的信息和分析各类数据的独有特征从而发现分类规则进行合理分类,为研究人员做出进一步的预测提供参考基础。分类的目的是根据数据集的特点构造一个分类函数或分类模型,该函数或模型能把未知类别的样本映射到给定的一个类别中,完成分类任务。在用途上,我们既可以使用数据分类算法分析已有的数据,又可以使用数据分类算法预测未来的数据。
本文主要针对数据挖掘中的分类算法进行研究和讨论,首先从宏观视角简单说明各个分类算法的基本思想,其次从笔者阅读过的相关文献的微观视角简单介绍分类算法的实际应用,并给出笔者在学习过程中对数据分类和聚类区别的认识。本文的其余部分组织如下。在第二节中介绍了与数据挖掘分类算法相关的基础知识;在第三节中介绍了数据挖掘中常用的分类算法;在第四节中介绍了分类算法的一些实际应用;在第五节中对数据挖掘中的分类算法进行总结,并给出了数据挖掘中分类与聚类的区别认识。
四、相关基础知识
本小节主要包括三个部分:首先对数据挖掘中研究的分类问题进行简要概述,接着对分类任务的两个过程进行说明,最后介绍了对分类算法性能的评估指标。
4.1 分类问题概述
分类问题作为数据挖掘技术的重要研究方向,其目的是使用分类算法建立分类模型,模型的输入是样本的属性,输出的是样本的类别,主要用于对未知事物的预测。其实,分类问题本质上是由现实问题抽象得来,在我们的日常生活中无处不在。例如,在电商领域,可以将用户在淘宝上购买商品看作是一个二分类问题,即用户有买和不买两种选择,利用用户的历史购买商品的行为数据建立用户-商品对的分类模型,为用户进行精准的个性化推荐;在银行领域,通过建立分类模型对银行用户进行分类,可以实现为不同类别的用户推荐适合的理财产品和相应服务。总之,分类问题在数据挖掘中具有重要的研究价值和现实意义。
4.2 分类过程
数据分类是一个两阶段过程,包括学习阶段和分类阶段,具体过程如图1所示。首先我们需要了解两个基本概念:训练数据集和测试数据集,其中训练数据集由人工采集数据并对数据进行众包标注生成,测试数据集用来对从训练数据集上学习的分类模型进行验证,一般情况下,训练数据集的数据量远大于测试数据集,以此希望可以得到分类效果最好的分类模型。

4.3 分类算法性能评估


值得我们注意的是,对于一个分类问题,精确率和召回率通常是相互制约的,即精确率高则一般召回率低,召回率高则一般精确率低。除了以上基于分类准确率的评估指标外,我们还可以从以下性能指标进行评估分类算法[2,p.240]:
(1)速度:指生成和使用分类模型的计算成本;
(2)鲁棒性:指当测试数据受到噪声干扰或有缺省值时,分类模型可以做出正确预测的能力;
(3)可伸缩性:指对于给定的大量数据集,能否高效地进行分类模型的构建;
(4)可解释性:指使用的分类模型是否能够容易地被理解和使用。
五、数据挖掘常用分类算法
本小节是对目前数据挖掘中常用的分类算法基本思想的及其优缺点的简单介绍,注意数据挖掘中的分类算法及其改进算法非常多,由于笔者水平有限,仅对其中相对来说比较常用的分类算法进行说明,主要包括:决策树算法[3]、朴素贝叶斯算法[4]、神经网络算法、SVM算法[5]和KNN算法[6]。
5.1 决策树算法
决策树算法是非常典型的数据挖掘分类算法,通过贪心方法,自顶向下不回溯递归构造的策略,将一个训练集分解成更小的子集,其最终可以形成一个直观的树结构,并将训练集的特点清晰地展现出来[7]。决策树算法由一个树形结构表示,树中每个内部节点表示一个属性判断条件,每个叶节点表示一个类别。对于测试数据集中一个待分类的样本数据,从树的根节点开始测试样本数据的属性,根据属性判断结果将样本数据分配到根节点的子节点上,不断重复判断和分配的过程,直到将样本分配到叶子节点上,即可得到样本数据的所述类别。
其实,决策树算法的实现本质上一个递归过程,我们可以简单将决策树算法的过程分为以下三个步骤:
(1)从训练数据集中选择最重要最合适的属性作为决策树的根节点,然后根据根节点分割训练数据集,选择一个可以代表整个训练数据集的节点开始构造决策树。
(2)若训练数据对象全部属于一个类别,则使用该类的类标号对节点进行定义,此时全为叶子节点;若训练数据对象不属于同一个类别,则需要根据某个策略比如信息熵来衡量属性,选择一个属性作为需要测试的属性,即为测试节点。根据测试节点的不同特征,将训练数据集分成若干个子集,将刚才选择的属性从原始属性集删除。
(3)重复以上步骤,直至生成一棵可以将训练数据集完好分类的决策树。
决策树算法之所以在数据挖掘中被广泛应用,主要是因为其具有众多优点:第一,决策树算法逻辑清晰,树形结构的表示更加直观分明,其分类规则便于理解和使用;第二,决策树算法分类精度高,每个节点对应一个分类规则,可以准确将每个数据分类到叶节点;第三,决策树算法的计算成本低,时间开销小[8]。但是,决策树算法也有一些缺陷,比如对于连续型的变量需要离散化处理,容易出现过拟合的现象。
目前的决策树算法种类比较多,典型的决策树算法有ID3、C4.5、SPRINT和SLIQ等等,本文不再一一说明。
5.2 朴素贝叶斯算法

朴素贝叶斯算法是应用最为广泛的一种基本贝叶斯算法,其有如下优点:第一,朴素贝叶斯算法逻辑思想简单,性能稳定,不会因为数据自身特征不同而对分类结果产生较大影响;第二,朴素贝叶斯算法的训练数据集的数据之间独立性越强,其分类的结果将越准确。当然,这也是朴素贝叶斯算法的最大缺陷,它是基于条件独立性假设的前提,这显然是一个理想状态,一般情况下数据之间都存在或多或少的关联,会降低分类的准确性,难以达到理论上的最佳分类效果。
5.3 神经网络算法
神经网络是网络拓扑知识为基础模拟人脑的结构及功能形成的一种有效运算模型,主要包括三部分:输入层、隐藏层和输出层。神经网络是由大量节点相互连接构成,每个节点代表一种特定输出函数,每两个节点间的连接都代表通过该连接信号的加权值,即权重。每层节点对输入信息的加权求和并进行非线性变换后输出,其输出值作为下一层的输入值,以此类推直到最后分类节点[9]。
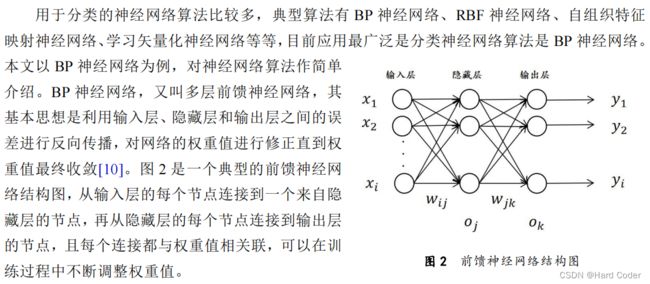
基于神经网络的数据挖掘分类算法有以下优点:第一,神经网络具有很强的学习能力,可以达到非常好的分类效果;第二,由于权重值可以进行调整,神经网络对噪声数据具有鲁棒性;第三,神经网络可以处理规则复杂的数据关系,因为其本质上属于非线性模型。同时神经网络分类算法的缺点也比较突出,主要是神经网络的建立比较困难,涉及激活函数、损失函数、权重值微调等方面,对最终的分类准确性影响较大。此外,基于神经网络分类算法的训练时间长,学习分类规则的速度比较慢。
5.4 SVM算法
支持向量机(SVM)算法是一种针对二分类问题的分类算法,即对线性和非线性数据进行分类的方法。SVM的基本原理是通过非线性映射,将原训练数据映射到较高的维上。在新的维上,搜索最佳分离超平面,即无论是线性数据还是非线性数据都会被超平面分成两部分,生成一个分类器以进一步处理新样本数据[2,p.265]。
SVM算法已经成为数据分类中最标准、最有帮助的技术之一,其具有以下优点:第一,SVM算法可以处理发信息数据集,比如处理文本分类、图像检测、人脸识别等问题;第二,SVM算法对于数据特征之间的相关性不敏感,可以提高泛化性能。当样本数据集比较大时,SVM算法需要较长的训练时间,效率较低,这是SVM算法最大的不足。关于SVM未来的研究目标主要是提高训练和检验的迅速,可以为超大型数据集服务。
5.5 KNN算法

KNN算法的基本优点主要有:第一,KNN算法不需要复杂的训练过程,其分类原理易于理解且易于实现,因为直接可以使用欧式距离公式进行距离计算;第二,KNN算法通过对待分类样本的周围样本点就行推测,可以充分利用训练数据集中的样本的某个或多个特征属性,极大降低分类过程中产生的误差;第三,KNN算法支持多分类,且分类准确率高。但KNN算法也存在不足之处,简要介绍如下:第一,KNN算法属于一种懒惰学习算法,在进行训练时,需要存储全部的训练样本;第二,KNN算法使用欧式距离作为距离度量,需要进行大量计算,同时可能存在无用的样本点会被重复计算,速度较慢;第三,KNN算法在对各个类别的边缘部分进行分类,可能会因为训练数据集中的各个类别数量分布不均匀导致分类结果产生误判。总之,目前对于KNN算法的研究热点是在保证分类效率的前提条件下,进一步提高分类的准确率。
六、分类算法实际应用
数据挖掘分类算法已经在各行各业取得广泛而深入的应用,本文不再逐一介绍,仅以笔者所阅读的两篇文献为例,分别从医学图像和需求分类视角简要介绍分类算法在其中的实际应用。
6.1 一种混合CNN-SVM阈值分割方法用于MRI脑图像肿瘤检测与分类[11]
笔者的主要研究方向是关于图像处理方面,曾经阅读过关于医学图像方面的文献。其中,文献[11]使用到了本文涉及的数据挖掘分类算法SVM。
由于目前对于脑肿瘤的判断主要依赖于影像学的表现,其中磁共振成像(MRI)是判断脑肿瘤最重要的工具。又由于深度学习(DL)方法已经在图像分类中取到良好分类效果,Khairandish等人[11]提出了一种在MRI脑图像肿瘤检测方面使用基于阈值的图像分割方法,在MRI脑图像肿瘤分类方面结合使用CNN和SVM。我们重点关注MRI脑图像肿瘤分类方面,将脑图像分类为良性和恶性肿瘤。提出的CNN-SVM混合模型通过将CNN的最后一层替换为SVM,即将CNN的全连接层的输出变成SVM的输入,其结构图如图3所示。此时,CNN模型在具有55卷积的2828特征图和具有22卷积的1414特征图的基础上分别进行不同的卷积和子采样,旨在加快训练过程和测试过程的信息提取。此后,SVM模型将CNN的全连接层输出作为输入,可以更好地分别训练特征向量,进行分类和决策。
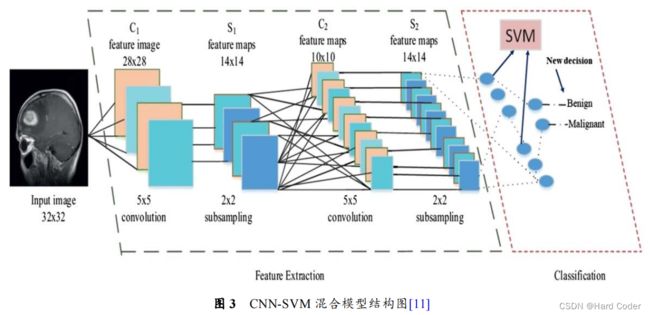
通过实验得出:基于SVM模型单独分类正确率为72.5536%,基于CNN模型单独分类正确率为97.4394%,基于SVM-CNN混合模型分类正确率为98.4959%,可以看出基于CNN-SVM混合模型取得更为先进的分类效果。同时,我们可以在未来考虑将传统数据挖掘分类算法和深度学习相结合,实现更好的分类精度。
6.2 基于深度学习的小数据集环境在线反馈用户需求分类[12]
笔者本学期在学习软件需求工程这门课过程中,曾研读文献[12]进行论文汇报,其中对于需求进行分类使用到了本文涉及到的数据挖掘分类算法SVM和朴素贝叶斯算法。
用户在访问应用商店和社交媒体平台时,可能会留下用户反馈,如何从存在网络俚语、快捷语法和糟糕格式等大量噪音的用户反馈中提取出有用的用户需求,对产品改进和竞争分析至关重要。Mekala等人[12]开发出了一个集成系统,对各种最先进的基于机器学习和基于深度学习的分类器进行整体开发和验证需求分类的精确率、召回率和F1值,提出的系统架构如图4所示。其中,基于机器学习的分类器分为基于TF-IDF分类器和朴素贝叶斯分类器。基于TF-IDF分类器使用TF-IDF技术计算出用户反馈文档中每个单词的TF-IDF值,然后将其构造成向量输入到SVM中对分类目标进行训练。朴素贝叶斯分类器对用户反馈文档进行需求分类时,首先需要计算用户反馈文档中每个单词和每个类的先验概率,其中单词的先验概率是单词特定评论类出现的次数与该类评论总数的比值,类的先验概率是该类评论数量与文档中总评论数量的比值;然后使用贝叶斯决策规则计算每个评论的类条件概率,最后根据贝叶斯定理计算取出概率最大值类别即可。
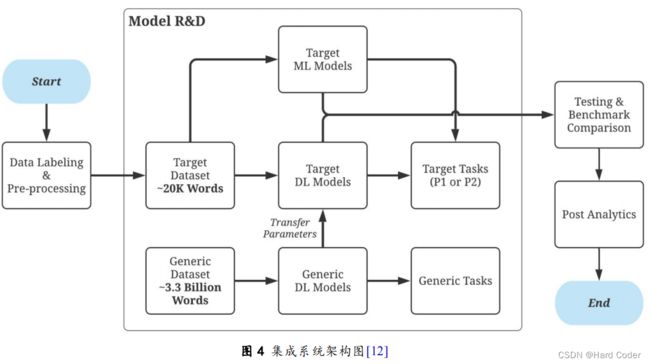
其实,作者只是将基于机器学习的分类器作为一个参考基准来与基于深度学习的分类器进行比较,来体现基于深度学习的分类器的更好分类效果。但从最终的实验结果来看,基于TF-IDF分类器和朴素贝叶斯分类器的分类指标评估只是稍逊色于基于深度学习的分类器,同时相对深度学习的分类器来说,基于机器学习的分类器的处理和训练时间非常短。
七、总结
大数据时代的到来,让社会各行各业和我们的日常学习及生活都充斥着海量数据,数据挖掘的重要性日趋明显。而作为数据挖掘的核心内容——分类算法,同时在发挥其不可或缺的作用。本文通过对数据挖掘分类算法的研究,完成的主要工作如下:
(1)本文对数据挖掘中的分类问题进行简要概述,又介绍了分类问题可以分为学习阶段和分类阶段两个过程,同时说明对于二分类问题的算法性能评估指标:准确率、精确率、召回率和F1值,同时也包括非分类精度的度量:速度、鲁棒性、可伸缩性和可解释性。
(2)本文介绍了目前数据挖掘常用的分类算法的基本思想和优缺点,包括:决策树算法、朴素贝叶斯算法、神经网络算法、SVM算法和KNN算法。不同的分类算法各有特点,应根据实际应用场景选择合适的算法以确保最佳的分类效果。
(3)本文通过阅读过的两篇文献,从医学图像和需求分类两个角度简单介绍了数据挖掘分类算法的实际应用,在不同领域中分类算法均取得了令人满意的分类效果。
在学习数据挖掘的分类算法过程中,笔者曾将分类和聚类的概念混淆,现将两个概念的区别总结如下:
(1)分类属于有监督的算法,而聚类是无监督的算法;
(2)分类时类别是已经预先定义好的,而聚类时某个对象所属类别并不是预定义的;
(3)分类完成的工作是进行预测,而聚类完成的工作是进行降维;
(4)分类处理数据时是一个一个处理的,而聚类处理数据时是一堆一堆处理的;
(5)常见数据挖掘分类算法本文已说明,而常见的数据挖掘聚类算法有K-Means算法、K-Means++算法、FCM算法、EM算法、LDA算法和DBSCAN算法等等。
八、参考文献


