跟姥爷深度学习2 TensorFlow的基本用法
一、前言
前面我们浅用TensorFlow做了个天气预测,虽然效果不咋样,但算是将整个流程跑通了。这一篇我们在之前基础上对TensorFlow的一些参数进行简单介绍,在接口文件的基础上了解各参数的简单含义和用法。
二、再次构建模型
我们先将之前的冗余代码都删除,做个简单的模型训练和预测。


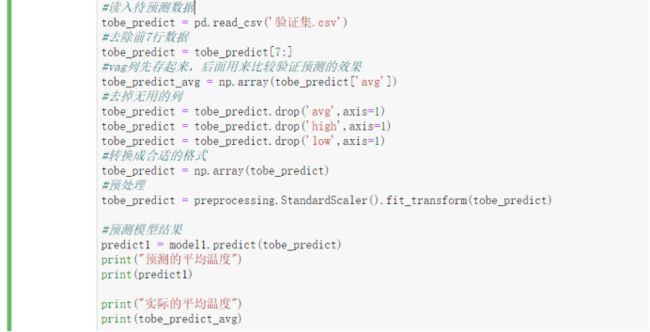
三、可以修改的参数
这些代码中我们主要能修改的包括:网络模型调整、网络配置修改、训练的方式。下面我们逐一来看。

1、网络模型构造
1)tf.keras.Sequential()
这一句的含义是实例化一个model1,再往model1里按顺序堆叠层组织就可以构建神经网络了(后面的model1.add操作)。
2)model1.add(layers.Dense(16))
这一句的含义是向model1里加一层神经网络,神经网络的样式由layers.Dense来定义。
3)layers.Dense(16)
这一句的含义是生成由16个神经元组成的一层神经网络,其中Dense的含义是“一个常规的全连接NN层”,也是比较常规常用的层。既然有Dense,那其实就还有其他类型的层结构,比较常见的有(参考链接:https://www.bbsmax.com/A/D854PnYW5E/):
Dense层:全连接层
Activation层:激活层对一个层的输出施加激活函数
dropout层:为输入数据施加Dropout。Dropout将在训练过程中每次更新参数时按一定概率(rate)随机断开输入神经元,Dropout层用于防止过拟合。
Flatten层:Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
Reshape层:Reshape层用来将输入shape转换为特定的shape
Permute层:Permute层将输入的维度按照给定模式进行重排,例如,当需要将RNN和CNN网络连接时,可能会用到该层。所谓的重排也就是交换两行
....(还有很多就不列举了)
目前我们也不用搞明白这些层具体的用法,知道有多种类型的神经网络结构就行了。目前我们就使用Dense即可。
4)Dense的参数

| units |
正整数,输出空间的维度。可以理解就是神经元个数。 |
| activation |
要使用的激活函数。如果未指定任何内容,则不应用任何激活(即。“线性”激活:a(x) = x)。激活函数非常有用,我们下面还要详细说。 |
| use_bias |
网络层是否使用偏差向量。作用就是决定卷积层输出是否有b。默认都是True的,在一些特殊场景下可能需要设置False。 |
| kernel_initializer |
这个是设置神经网络内部如何进行初始化,默认的glorot_uniform含义是“均匀分布初始化器”。自然还有其他初始化方式,后面要详细说。 |
| bias_initializer |
偏置向量的初始值设定项。也就是设置b如何初始化。我们理解这个b也是神经网络的一部分就行了。默认的zeros就是初始值为0。它与kernel_initializer一样有很多种初始化方式,后面详细说。 |
| kernel_regularizer |
应用于核权重矩阵的正则化器函数。正则项在优化过程中层的参数或层的激活值添加惩罚项。用处是防止过拟合。 |
| bias_regularizer |
应用于偏置向量的正则化器函数。就是施加在b上的惩罚项,也是用于防止过拟合。 |
| activity_regularizer |
应用于层输出的正则化器函数。就是施加在激活函数上的惩罚项,还是防止过拟合。 |
| kernel_constraint |
应用于核权重矩阵的约束函数。简单来说就是让神经网络中的参数值限定在某个范围,还是防止过拟合,不过很少使用。 |
| bias_constraint |
应用于偏置向量的约束函数。同上,还是不常用的。 |
5)Dense参数与神经网络的结构
如果单看前面Dense参数的解释你大概率会云里雾里,但如果对神经网络的内部结构有一点了解的话,就比较容易理解了,下面我尝试三言两语来描述一下神经网络的内部细节,看是否会有点帮助。
(建议结合很久以前写的博文:https://mbb.eet-china.com/blog/3887969-408491.html)
简单来说,神经网络内部大体由4个函数组成:
传播函数、激活函数、反向传播函数、损失函数
这4个函数要实现的核心功能包括:
向前预测、输出映射、反向优化、损失计算
用一个公式来表达:
Y = w*f(X)+b
其中X是我们的输入,Y是预测结果,“标注”我们可以用label_Y来标识,含义是理论上应该正确的Y值。
那么所谓的训练就是:
- 随机给一个w和b值,再输入X计算得到Y(向前预测)
- 计算得到的Y不能直接使用,我们再用激活函数将Y运算一下得到真正的Y值(激活函数)
- 比较label_Y与Y的值得到损失loss(与标注对比)
- 根据损失来优化w和b(反向传播)
当我们输入大量的X和Y值后,就能将w和b调教成更加合适的数值,w、b的值也就是我们的训练出来的模型,这样当我们需要预测时,输入一个X1就能得到一个合适的Y1。
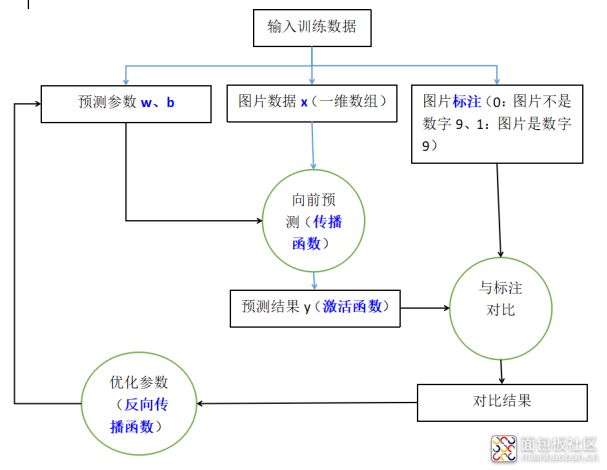
所以,类比来看:
- features = pd.read_csv('训练集.csv')是导入训练数据X
- model1 = tf.keras.Sequential();model1.add(layers.Dense(16))是生成并初始化了w和b,要注意w和b不是一个数,而是一组数字。
- labels_avg = np.array(features[avg])是将“标注”存起来,也就是label_Y
- model1.fit()执行的训练就是传播函数+激活函数+对比结果+反向传播
- 反向传播的目的就是更新w和b(优化参数)。
接着我们再看一下Dense的参数就比较好理解了。
| units |
设置神经元的个数,同时也就是设置了w和b的数值维度(一部分)。w和b的数值维度由神经元个数和神经网络层数共同决定。 |
| activation |
设置激活函数。通过w*f(X)+b计算出Y后,再对Y执行的一个运算就是激活函数,这里设置使用什么样的运算 |
| use_bias |
设置是否使用b,不使用的话公式就变成了w*f(X) |
| kernel_initializer |
设置w的初始化值,比如全部初始化成0,或者初始化成一些随机数,或者是符合正态分布的随机数。 |
| bias_initializer |
设置b的初始化值 |
| kernel_regularizer |
设置对w施加的正则化函数。每一次预测优化w的值后,为了让w不过拟合(w的值过于向训练数据优化),就做一次惩罚运算,让w的值更随机一点。 |
| bias_regularizer |
设置对b施加的正则化函数。防止过拟合,原理同上。 |
| activity_regularizer |
设置对Y施加的正则化函数。防止过拟合,原理同上。 |
| kernel_constraint |
设置让w的值限定在某个范围,还是防止过拟合,很少使用。 |
| bias_constraint |
设置让b的值限定在某个范围,同上,还是不常用的。 |
6)Dense的可选参数
| Units 神经元的个数 |
正整数。比如10就是这一层网络使用10个神经元 用法:model1.add(layers.Dense(10)) |
| Activation 激活函数 |
用法:model1.add(layers.Dense(10,activation=’relu’)) activation=’softmax’ activation=’softplus’ activation=’softsign’ activation=’relu’ activation=’tanh’ activation=’sigmoid’ activation=’hard_sigmoid’ activation=’linear’ 这么多知道啥意思也没用,可以挨个试试看,最常用的就是relu |
| use_bias 是否使用b |
默认就是True 用法:model1.add(layers.Dense(10,use_bias=True)) |
| kernel_initializer w的初始化值 |
用法:model1.add(layers.Dense(10,kernel_initializer=’glorot_uniform’)) kernel_initializer=’zeros’ 全0初始化 kernel_initializer=’one’ 全1初始化 kernel_initializer=’constant’ 初始化为固定值 kernel_initializer=’random_uniform’ 均匀分布 kernel_initializer=’random_normal’ 正态分布 kernel_initializer=’truncated_normal’ 产生截断的正态分布 kernel_initializer=’identity’ 单位矩阵 kernel_initializer=’orthogonal’ 正交 kernel_initializer=’glorot_normal’ 正态化的Glorot初始化,即Xavier kernel_initializer=’glorot_uniform’ Glorot均匀分布 除了全0全1,其他都看不懂,反正都可以填进去跑一跑试一试。 |
| bias_initializer b的初始化值 |
用法:model1.add(layers.Dense(10,bias_initializer=’zeros’)) 可选设置同kernel_initializer |
| kernel_regularizer 对w施加的正则化 |
用法:model1.add(layers.Dense(10,kernel_regularizer=regularizers.l2(0.01))) kernel_regularizer=regularizers.l2(0.01) kernel_regularizer=regularizers.l1(0.01) |
| bias_regularizer 对b施加的正则化 |
同上 |
| activity_regularizer 对Y施加的正则化 |
同上上 |
| kernel_constraint w的值限定 |
一般不使用就不多说了 |
| bias_constraint b的值限定 |
一般不使用就不多说了 |
7)Dense修改参数的实例
A.啥参数也不加

训练结果:
B.增加激活函数relu

训练结果:看起来差别不大

C.增加激活函数softmax
训练结果:更差了。所以这个激活函数得选择合适的,而不是瞎选。

D.不使用b

训练结果:完全没法看了

E.设置w的初始化值为random_uniform

训练结果:效果也是不明显

后面的大家可以自己试,累了。
2、对网络的配置
1)model1.compile()
作用是设置优化器、损失函数和准确率评测标准。


| optimizer 设置优化器 |
用法: model1.compile( optimizer=tf.keras.optimizers.SGD(0.001), loss='mean_squared_error' ) optimizers.SGD(0.001) optimizers.Adagrad(0.001) optimizers.Adadelta(0.001) optimizers.Adam(0.001) 这里0.001是学习率,简单来说,这个数值就是每次对w和b进行优化的幅度。太大太小都不合适。 |
| loss 损失函数 |
用法: model1.compile( optimizer=tf.keras.optimizers.SGD(0.001), loss='mean_squared_error' ) loss='mean_squared_error' # 均方误差 loss='mean_absolute_error' # 平均绝对误差 loss='mean_absolute_percentage_error' # 平均绝对百分比误差 loss='mean_squared_logarithmic_error' # 均方对数误差 loss='kullback_leibler_divergence' 损失函数的目的是计算模型在训练期间应寻求最小化的数量 |
| metrics 评价函数 |
用法: model1.compile( optimizer=tf.keras.optimizers.SGD(0.001), loss='mean_squared_error', metrics=’accuracy’ ) metrics=’accuracy’ metrics=’sparse_accuracy’ metrics=’sparse_categorical_accuracy’ 评价函数用于评估当前训练模型的性能 |
| loss_weights |
这4个参数用的极少,也找不到啥资料,所以忽略吧。 |
| sample_weight_mode |
|
| weighted_metrics |
|
| target_tensors |
2)compile修改参数的实例
A.SDG

训练结果:

B.Adagrad

训练结果:

C.Adadelta

训练结果:

D.Adam
、

训练结果:

Loss就不演示了,大家自己改着玩吧。
3、对训练函数的配置

| x |
输入数据 |
| y |
标签,也就是训练数据里的正确答案 |
| batch_size |
每次训练使用的数据量,一般设置成32、64、128这样,比如有10000个数据,这里你设置成64,那就是将所有数据分成156个组,每次将一组的数据放进去一起训练。主要就是加快训练速度,不然一个一个来得多久。 |
| epochs |
总训练次数,比如我们设置的是50,那就是将输入的数据放到模型里训练50次,也就是对模型进行了50次的优化 |
| verbose |
日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录 |
| callbacks |
回调函数,在每个training/epoch/batch结束时,如果我们想执行某些任务,例如模型缓存、输出日志。这个现在用不到不多说。 |
| validation_split |
0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。 |
| validation_data |
形式为(X,y)的tuple,是指定的验证集。此参数将覆盖validation_spilt。也就是不使用训练数据里的数据作为验证集,而是从外部另外输入。实际上这个验证集对训练没有影响,只是方便你看现在训练的效果。 |
| shuffle |
表示是否在训练过程中随机打乱输入样本的顺序 |
| class_weight |
很少用到 |
| sample_weight |
|
| initial_epoch |
四、模型的存储和调用
我们训练好以后,想要保存起来咋弄呢,非常简单。

五、回顾
本篇我们将TensorFlow主要用到的方法和参数进行简单的介绍,大家可以自己挨个换着试试。另外还将模型的保存和调用也演示了一下。