数据分析师 ---- SQL强化(2)
数据分析师 ---- SQL强化(2)
文章目录
- 数据分析师 ---- SQL强化(2)
-
- 题目一:SQL实现文本处理
- 题目二:语种播放量前三高所有歌曲
- 总结:
题目一:SQL实现文本处理
现有试卷信息表examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长)
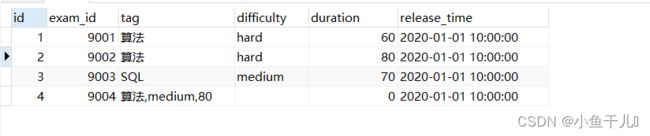
录题同学有一次手误将部分记录的试题类别tag、难度、时长同时录入到了tag字段,
请帮忙找出这些录错了的记录,并拆分后按正确的列类型输出。
由示例数据结果输出如下:

创建表
drop table if exists examination_info,exam_record;
CREATE TABLE examination_info (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
exam_id int UNIQUE NOT NULL COMMENT '试卷ID',
tag varchar(32) COMMENT '类别标签',
difficulty varchar(8) COMMENT '难度',
duration int NOT NULL COMMENT '时长',
release_time datetime COMMENT '发布时间'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
INSERT INTO examination_info(exam_id,tag,difficulty,duration,release_time) VALUES
(9001, '算法', 'hard', 60, '2020-01-01 10:00:00'),
(9002, '算法', 'hard', 80, '2020-01-01 10:00:00'),
(9003, 'SQL', 'medium', 70, '2020-01-01 10:00:00'),
(9004, '算法,medium,80','', 0, '2020-01-01 10:00:00');
题意分析:
通过题意我们能明白,题目主要让做的就是将数据填充错误的行进行分割字符串,让正确的数据放到对应的字段中
select exam_id,
substring_index(tag,",",1) tag,
substring_index(substring_index(tag,",",-2),",",1) difficulty,
substring_index(tag,",",-1) duration
from examination_info
where difficulty=''
涉及知识点:
字符串拆分:substring_index(str, delim, count)
| 参数名 | 解释 |
|---|---|
| str | 需要拆分的字符串 |
| delim | 分隔符,通过某字符进行拆分 |
| count | 当 count 为正数,取第 n 个分隔符之前的所有字符; 当 count 为负数,取倒数第 n 个分隔符之后的所有字符。 |
可以嵌套使用
也可以使用
regexp_substr函数使用正则表达式进行切分
题目二:语种播放量前三高所有歌曲
歌曲表:songplay
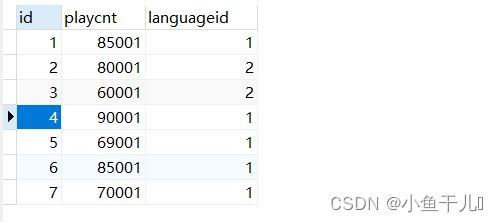
语种表:languageid
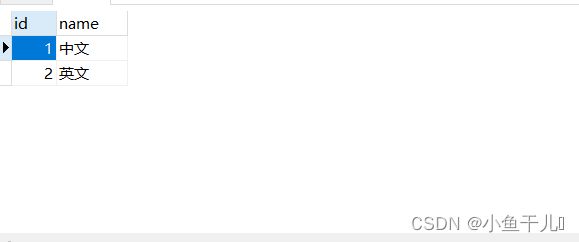
创建表:
drop table if exists songplay;
create table `songplay`(
`id` int,
`playcnt` int,
`languageid` int
);
insert into songplay values(1,85001,1);
insert into songplay values(2,80001,2);
insert into songplay values(3,60001,2);
insert into songplay values(4,90001,1);
insert into songplay values(5,69001,1);
insert into songplay values(6,85001,1);
insert into songplay values(7,70001,1);
drop table if exists language;
create table `language`(
`id` int,
`name` varchar(255)
);
insert into language values(1,'中文');
insert into language values(2,'英文');
题意分析:
题目是要查询不同语种播放量前三高所有歌曲,当播放量一样的时候排名一样,所以这时候就需要考虑使用dense_rank函数先建立排名,最后在取排名每个排名为前3的歌曲。
DENSE_RANK()函数对序号进行并列排序,并且不会跳过重复的序号,比如序号为1、1、2
select language_name,songid,playcnt
from (
select s.id songid,
l.name language_name,s.playcnt,
# 关键
dense_rank() over(partition by name order by s.playcnt desc) rank_num
from songplay s join language l
on s.languageid = l.id
# 排序
order by l.id
) tmp
where rank_num<4
注意这个题目中隐层了一个要求,就是返回语种的顺序需要和语种表中出现的顺序一致,所以就需要
order by l.id
关键代码解读:
dense_rank() over(partition by name order by s.playcnt desc) rank_num
使用窗口函数dense_rank() 不跳过序号排序,
partition by name 按照name进行分组
order by s.playcnt desc 按照 s.playcnt进行进行降序排序
总结:
这次两道SQL试题比较基础,题目一主要考察的是substring_index函数的应用,题目二考察的是窗口函数中dense_rank()和over()的运用。