Hive安装与操作
目录
环境
数据
实验步骤与结果
(1)环境启动
(2)Hive基本操作
环境
Hadoop集群开发环境、mysql、Hive环境
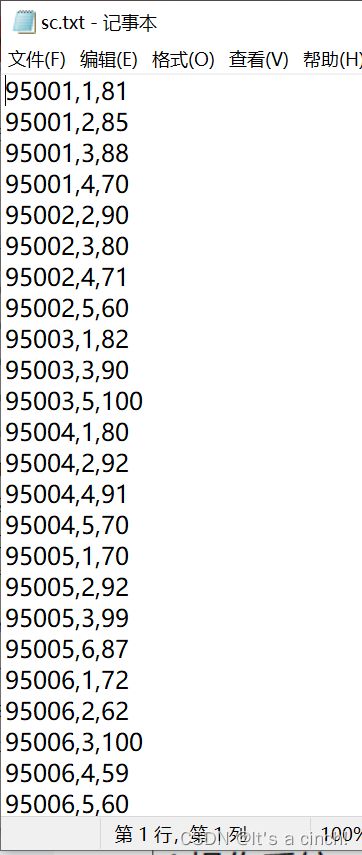
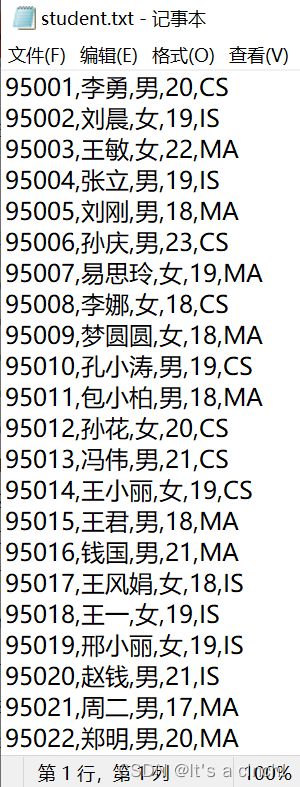
数据
course.txt、sc.txt、student.txt

实验步骤与结果
(1)环境启动
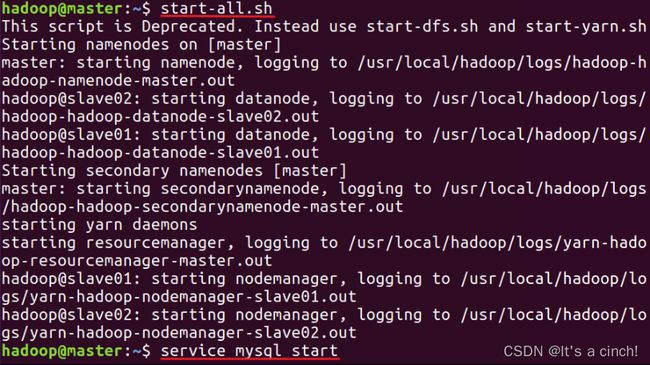
①执行命令:“start-all.sh” #启动hadoop服务,
②执行命令:“service mysql start” #启动mysql服务
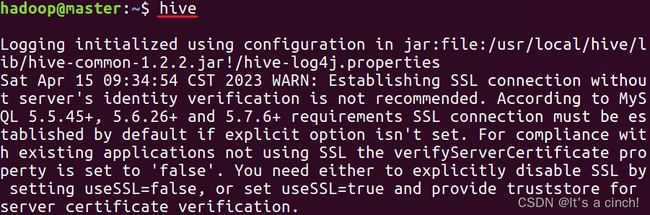
③执行命令:”hive” #启动hive
执行命令:“mysql -uroot -p” #启动mysql,需输入密码进入
如果正确,结果就如下图

(2)Hive基本操作
①表的基本操作
hive的清屏命令 ctrl+l
删除表 :hive> drop table if exists表名;
看一下数据库

创建数据库 输入:create database studentInfo;

接下来在studentInfo这个数据库中建表
输入:use studentInfo;

建表 输入: create table student(Sno int,Sname string,Sex string,Sage int,Sdept string) row format delimited fields terminated by ‘,’ stored as textfile;

create table course(Cno int,Sname string) row format delimited fields terminated by ‘,’ stored as textfile;

create table sc(Sno int,Cno int,Grade int) row format delimited fields terminated by ‘,’ stored as textfile;

(先进库才能show tables)

②数据加载与录入
在hadoop家目录下导入表
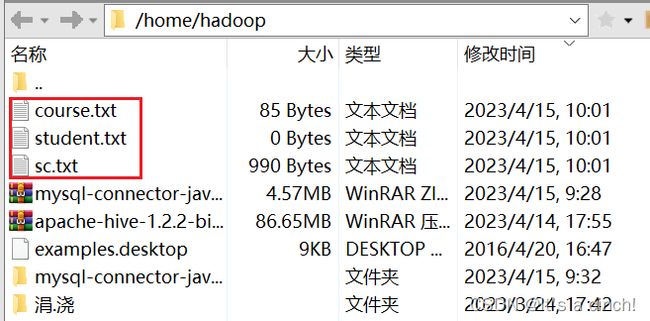

接着去hive下输入:load data local inpath ‘/home/hadoop/student.txt’ overwrite into table student;

同时还有另外两个表
输入:load data local inpath ‘/home/hadoop/course.txt’ overwrite into table course;
输入:load data local inpath ‘/home/hadoop/sc.txt’ overwrite into table sc;

③开始测试(类SQL语句)
(注意要在自己的那个数据库里 use database)
查询全体学生的学号和姓名,输入:select Sno,Sname from student;

查询选修课程的学生姓名,输入:select distinct Sname from student inner join sc on student.Sno=Sc.Sno (select distinct用于返回唯一不同的值。inner join内连接)(每一次这种查找都会通过mapreduce进行操作可以看到 )

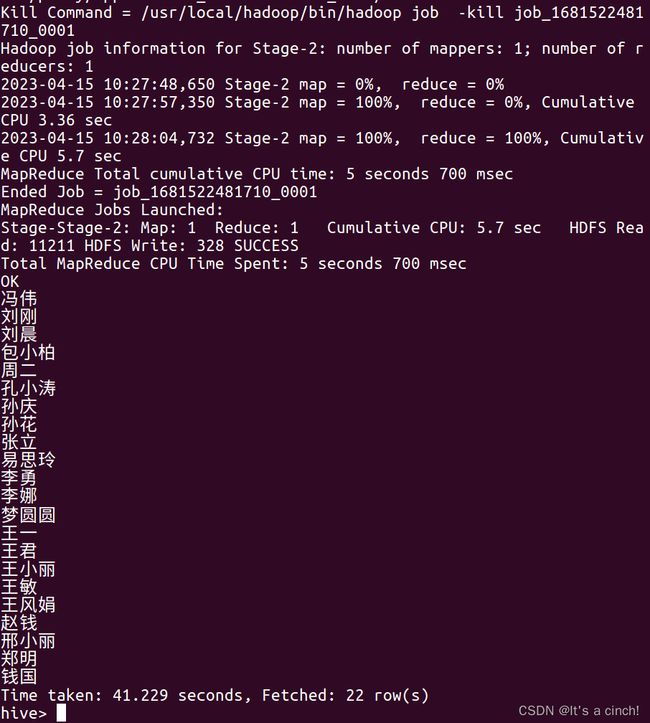
查询学生的总人数,输入:select count(*) from student
![]()
