Human-centric Relation Segmentation: Dataset and Solution论文解读+基础知识介绍
1. Human-centric Relation Segmentation: Dataset and Solution (TPAMI2021)
论文链接:https://arxiv.org/abs/2105.11168
作者单位:北航、中国科学院、海洋人工智能实验室
摘要
1) 摘要首先叙述了现实问题:当机器人被告知要“把女孩的左手拿着的书给我”时,如果女孩用左手和右手分别拿着一本书,大多数现有的方法都会失败。因此视觉和语义理解还是存在一定的细粒度的问题。针对这个问题,该文介绍了一个新的任务,命名为Human-centric Relation Segmentation(HRS)–以人中心的关系分割,这个任务可以作为 human-object interaction detection (HOI-det)的一个细粒度案例。HRS旨在预测人类与周围实体之间的关系,并识别出相关的关系人体部分,用像素级掩模表示。例如对于上述的现实问题例子,HRS任务产生了关系三元组
2) 该文这个新任务收集了一个新的Person In Context (PIC)数据集,其中包含17122个高分辨率图像和密集标注的实体分割和关系,包括141个对象类别,23个关系类别和25个语义人体部分。
3) 该文提出了一个Simultaneous Matching and Segmentation (SMS)框架作为HRS任务的解决方案。它包含三个并行分支,分别用于实例分割(entity segmentation)、主体物体匹配(subject object matching)和人体解析(human parsing)。具体来说,实例分割分支通过动态生成的条件卷积获得实例掩模;主体物体匹配分支检测任何关系的存在,通过位移估计来链接相应的人体和物体并对交互的人体部分进行分类,并对相互作用的人体部分进行分类;人体解析分支生成像素级的人体部分标签。
Introduction
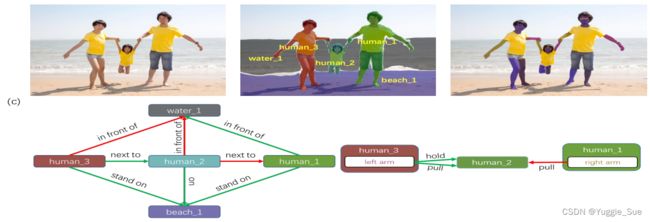
1)HRS任务
HRS: pixel-level 任务,目的是预测人类与周围实体之间的关系,并识别与之关系相关的人类部分,并用像素级掩模表示。
与其他任务的关系: 如下图下表所示
Visual Relation Detection (VRD): 旨在理解图像中实体之间的关系,三元组
human-object interaction detection (HOI-det): 旨在估计人类和周围物体之间的关系,三元组
| VRD | HOI-det | HRS | |
|---|---|---|---|
| Subject(主体) | entity | human | human+part |
| Object(物体) | entity | thing | entity |
| relation | action+geo | action | action+geo |
| Results | bbox | bbox | pixel-level mask |
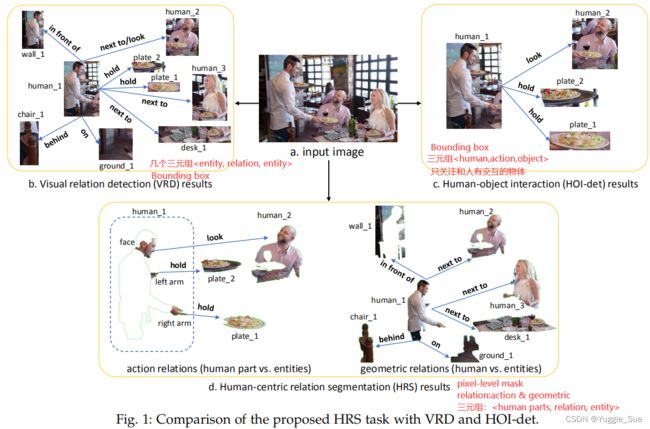
2)PIC数据集
原因:现有数据集既没有part-level的关系标注,也没有掩模的标注。
内容:17,122张同时带有分割和关系标签的图像。141种分割的实例对象,25种人体部位和16个人体关键点。14种action关系和9种geo关系。
3)SMS框架
SMS框架包含三个并行的分支:
1)实例分割(entity segmentation)分支。这个分支通过识别实例的中心和相应的掩模对图像中的实例进行分割。为了检测实例中心,该文估计了实例的中心热图,这个heatmap的最高响应对应于实例中心的位置和类别。为了生成掩码,该文并行地生成掩码内核和掩码特征。基于探测到的实例中心的位置,动态生成一个具体的location-aware掩模核,并与掩码特征进行卷积,以生成实例的掩模。
2)主体物体匹配( subject object matching)分支。这个分支将人与其交互的实例配对,并识别它们之间的关系。具体地说,该文检测到关系点(主体和实例物体的中间点),并且估计每个关系点与主体/对象之间的位移,并对参与交互的人体部分进行分类。由同一关系点连接的主体和对象成对并形成一个三元组。
3)人体解析( human parsing)分支。一个人体解析分支产生人体语义解析。
Related work
1)VRD
VRD就是检测输入图像中由主体、关系和对象组成的关系三元组。大多数现有的VRD方法遵循两阶段策略:目标检测->关系估计。现有的研究主要集中在第二阶段上。
2)HOI-det
HOI-det目的是检测主体为“人”和物体之间的关系,目前的方法大多遵循一个两阶段pipeline,先检测所有的候选主体和物体,然后检测他们之间的交互。
PIC数据集
1)相关challenge:
ECCV 2018 the 1st PIC workshop/challenge,ICCV 2019 the 2nd PIC workshop/challenge
2)数据收集
数据爬行(crawling)->数据筛选(过滤低分辨率或者没有人的图片)->数据平衡(缓解长尾分布)
3)数据标注
数据标注结果如下所示:

人类标注类别和关键点标注如下表: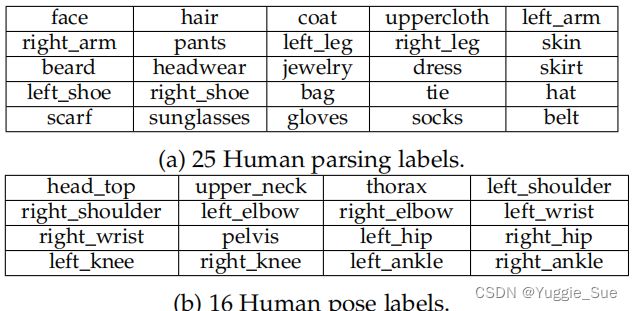
注意:一个图片之间可能共存不同的关系,一个人体part和一个entity之间也可能共存不同的关系。
4)数据集统计
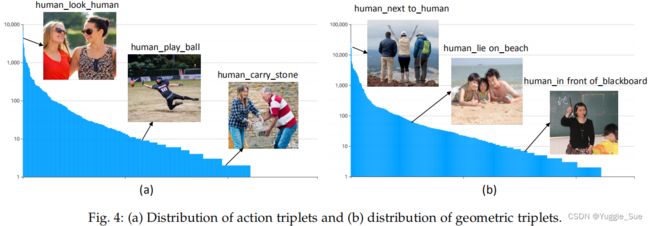
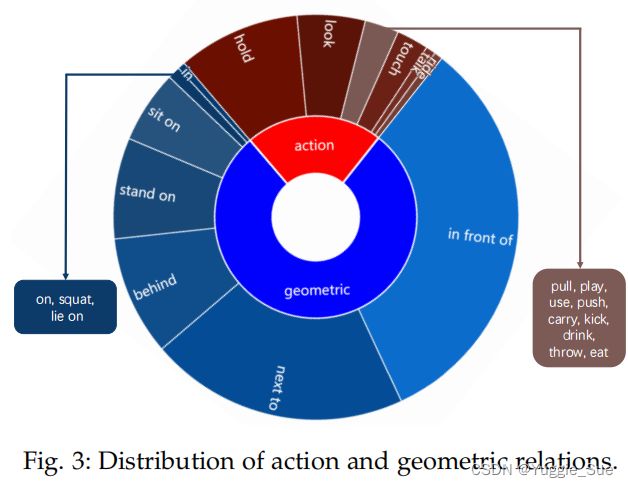
数据集中的数据分布如下,可以看到几何关系和动作关系都存在长尾分布。PIC分别分为12339、1916和2867张图像,分别用于训练、验证和测试集。
5)与其他数据集的比较

该文方法
1)整体框架
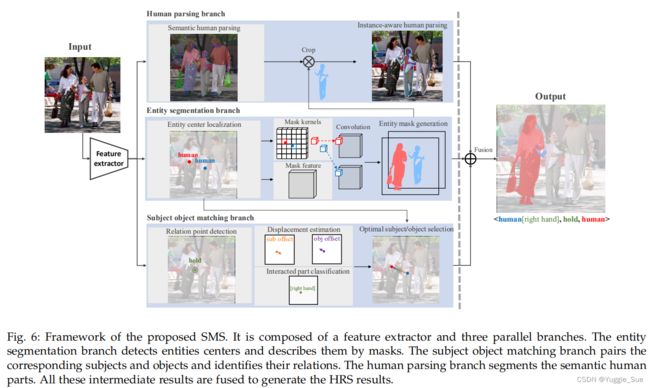
2)实例分割分支 entity segmentation branch
目的:输出实体(主体和物体)的像素级掩码
方法:一个实体中心定位模块+一个实体掩码生成模块
实例中心定位
目的:检测实例中心(x,y)及预测label c.
由于直接检测实例中心较为困难,因此使用了关键点估计方法( key-point estimation methods)[47]将一个点分解成一个具有高斯核的热图。
为了平衡正负样本点,在中心热图上使用了focal loss。

实例掩码生成
受SOLOv2 的启发,采用了一种位置感知实体掩码生成方法,首先并行学习掩码核和掩码特征,然后在掩码特征上应用1×1位置感知卷积核来产生掩码。具体来说,输入图像被分为SS个网格,每个网格代表了一个独特的位置感知卷积核,所以整个掩码核的大小为SSD。如果一个实例的中心落在一个网格中,则选择对应的掩码核大小为11D,与掩码特征HW*D卷积,生成掩码。

3)主体物体匹配分支Subject Object Matching Branch
假设存在M个实例,那么就存在M(M-1)种可能的relation组合。传统的VRD方法遍历所有组合,这是相当耗时的。该文引入了一个关系点relation point,是主体中心和物体中心之间的中点。那么可以得到关系中心点和物体中心点之间的偏移,以及关系中心点和主体中心点之间的偏移。关系点的估计也是通过关键点估计法进行的。
偏移估计:模型输出两个位移偏移图Ds和Do。偏移估计loss为:
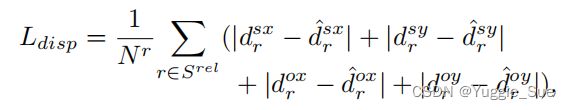
交互部分分类:如果是action关系,那么可以对主体的交互部分进行细化分类,例如将人细化为人的右手。为此,该文输出每个人类部分参与行动的概率。交互部分分类loss为BCELoss:
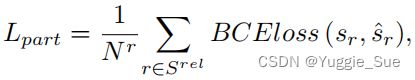
4)人体解析分支human parsing branch
目的:生成人体部分mask,loss如下:
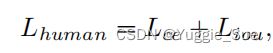
Liou是Lovasz loss[50],直接优化IoU.
训练的最终loss
总loss如下:此处的Lrel是relation point的loss,与Lent类似
![]()
推理过程
首先选取top-Ks、top-Ko、top-Kr个点作为物体中心点、主体中心点和关系点。每个检测到的关系点通过一个最优的主体/对象选择过程(如下)找到其对应的主体和对象:
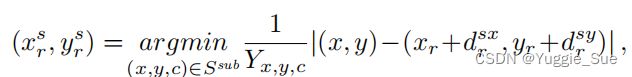
主体和物体的中心确定后,可以选取subject mask feature/kernel和object mask feature/kernel,从而获得两个的mask。如果是动作relation,则需要将人细化分类。
实验
1)metric
判断预测三元组是否正确的标准:一个和ground truth完全一致的三元组,或者三元组中人体和物体与ground truth的交并比大于一个阈值,则这个预测样本为TP样本。
指标:mean Recall@K(abbr. mR@K)[15],也就是Recall@K的平均值。AR:average Recall,mR@25, mR@50 and mR@100的平均值。
1)在PIC数据集上的结果
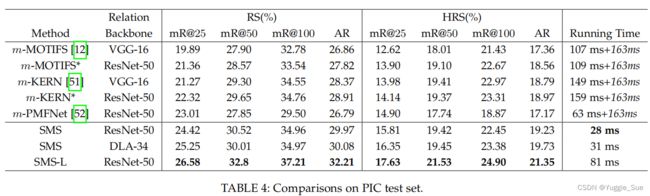
MOTIFS、KERN、PMFNET分别是VRD、VRD、和HOI-det任务上的SOTA算法,m-method分别是对这些方法进行了修改,主要修改内容在于将bbox变为mask,以及将backbone换为ResNet。SMS-L表示更大的SMS网络,拥有更多的参数,但是更耗时。

上表是不同种类关系之间的比较。
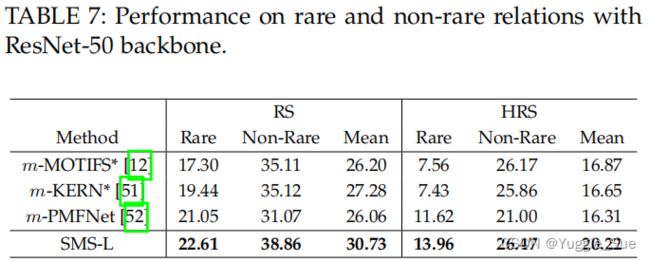
这里将出现次数少于800次的关系定义为rare关系,在rare关系和non-rare关系上进行了比较。
2)可视化实验