MIT6.824 lab2C&2D实验总结
2C
就是持久化一些变量,日志,任期,投票给谁,2D(lastincludeterm, lastincludeindex, snapshot)。同时最难受的是Figure8Unreliable这个测试点,总是几百次出现一两个错误。最后发现是对论文一句话的歧义。这里讲解一下figure8
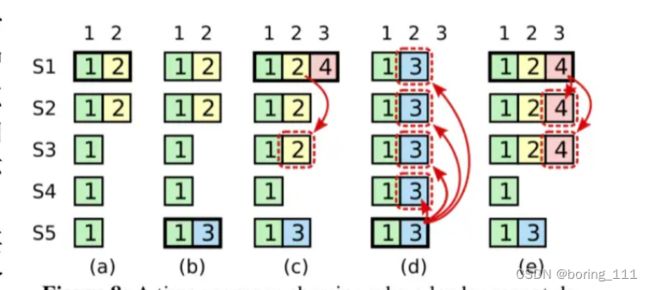
这张图主要是发现了一个问题,就是在b阶段,1是term3,然后减s3, s4也提到3,变成leader,得到一个command,c图s1超时(s2是leader)然后1,2,3获得选票,变成leader。得到一个term4的log。这个时候可以提交,但是如果我们提交只是到第二个log的话,根据选举约束,S5可能是leadr。但是你可能会问,s1,s2,s3的term都更大啊!是的,但是因为s5前s3要求选票的话,会将自己变成大term,变成follower,然后超时,又开始新一轮选举,变为leader。然后就覆盖了之前的提交。解决办法是在改变term的时候看看是不是最后一个log的term==rf.currentterm。这样就保障了大多数日志是最新的,强有力的保障了选举约束(日志最新)之前误解成apply提交阶段要这样,结果debug了快一天。。。还是英文比较好点。
2D
就是做快照,减少日志,如果前面的日志是下标的话,这个地方就要大改了。。。
snapshot持久化日志,对日志进行减少,但是要注意把第0个term要变成lastincludeterm,因为选举约束判断日志最新需要。
func (rf *Raft) Snapshot(index int, snapshot []byte) {
// Your code here (2D).
DPrintf("Node{%v} snapshot index{%v} snapshot{%v} 1", rf.me, index, snapshot)
rf.mu.Lock()
defer rf.mu.Unlock()
DPrintf("Node{%v} snapshot index{%v} snapshot{%v}", rf.me, index, snapshot)
if rf.lastIncludeIdx >= index {
DPrintf("snapshot invaild index{%v} preindex{%v} term{%v}", index, rf.lastIncludeIdx, rf.CurrentTerm)
return
}
snapshot_array := make([]LogEntry, 1)
snapshot_array[0].Log_Term = rf.Log_Array[index-rf.lastIncludeIdx].Log_Term
snapshot_array = append(snapshot_array, rf.Log_Array[index+1-rf.lastIncludeIdx:]...)
rf.Log_Array = snapshot_array
rf.lastIncludeIdx = index
rf.lastIncludeTerm = snapshot_array[0].Log_Term
rf.persist()
rf.persister.Save(rf.persister.raftstate, snapshot)
}然后就是向严重落后的follower发送快照rpc(preidx < rf.lastinclude_idx)
func (rf *Raft) InstallSnapshot(args *SnapArgs, reply *SnapReply) {
DPrintf("install rpc Node{%v} 1", rf.me)
rf.mu.Lock()
defer rf.mu.Unlock()
DPrintf("install rpc Node{%v}", rf.me)
reply.Term = rf.CurrentTerm
// my add
reply.LastIncludedIndex = args.LastIncludedIndex
if rf.CurrentTerm > args.Leader_Term {
DPrintf("InstallSnapshot node{%v} term{%v} large leader_term{%v} id{%v}", rf.me, rf.CurrentTerm, args.Leader_Term, args.Leader_Id)
return
}
rf.ToFollower()
rf.ResetElection()
if rf.CurrentTerm < args.Leader_Term {
rf.CurrentTerm = args.Leader_Term
rf.VoteFor = args.Leader_Id
rf.persist()
}
if rf.Committed_Idx >= args.LastIncludedIndex {
DPrintf("InstallSnapshot commit{%v} >= lastidx{%v} node{%v} term{%v} eader_term{%v} id{%v}", rf.Committed_Idx, args.LastIncludedIndex, rf.me, rf.CurrentTerm, args.Leader_Term, args.Leader_Id)
return
}
// may be
// if args.Data == nil {
// DPrintf("Node{%v} data nil", rf.me)
// return
// }
// DPrintf("Node{%v} snapshot index{%v} snapshot{%v}", rf.me, index, snapshot)
if rf.lastIncludeIdx >= args.LastIncludedIndex {
DPrintf("install snapshot invaild index{%v} preindex{%v} term{%v}", args.LastIncludedIndex, rf.lastIncludeIdx, rf.CurrentTerm)
return
}
snapshot_array := make([]LogEntry, 1)
snapshot_array[0].Log_Term = args.LastIncludedTerm
if args.LastIncludedIndex < rf.GetLastLog().Index {
snapshot_array = append(snapshot_array, rf.Log_Array[args.LastIncludedIndex+1-rf.lastIncludeIdx:]...)
}
rf.Log_Array = snapshot_array
rf.lastIncludeIdx = args.LastIncludedIndex
rf.lastIncludeTerm = args.LastIncludedTerm
reply.Success = true
reply.LastIncludedIndex = rf.lastIncludeIdx
reply.LastIncludedTerm = rf.lastIncludeTerm
if rf.Last_Applied_Idx < rf.lastIncludeIdx {
rf.Last_Applied_Idx = rf.lastIncludeIdx
}
if rf.Committed_Idx < rf.lastIncludeIdx {
rf.Committed_Idx = rf.lastIncludeIdx
}
rf.persist()
rf.persister.Save(rf.persister.raftstate, args.Data)
applyMsg := ApplyMsg{
SnapshotValid: true,
Snapshot: args.Data,
SnapshotTerm: args.LastIncludedTerm,
SnapshotIndex: args.LastIncludedIndex,
}
rf.ApplyChanTemp <- applyMsg
}
第一个遇到的问题就是死锁问题。这里的死锁居然是因为和测试代码死锁了。
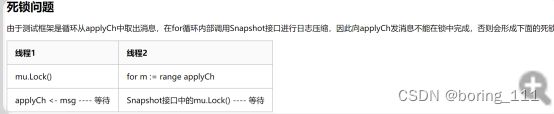
嗯,无语。解决办法就是把这个锁和这个chan分开,如果解锁的话,会导致不一致。但应该可以用一些额外条件解决。但我选择的是用一个中间chan
func (rf *Raft) applier() {
for msg := range rf.ApplyChanTemp {
rf.ApplyChan <- msg
}
}第二个问题就是发现一些边界条件没能很好的判断。导致了can't reach agreement。
这里记录两个典型思考
第一个就是如果我们一直发送给他的是小于lastincludeIndex的话,就一直被拒绝,所以我们应该在这个情况下发给他lastincludeidx。
if reply.LastIdx == 0 {
rf.Next_Idx[peer] = rf.GetIdxPreTermLogEntry(reply.PrevLogIndex)
if rf.Next_Idx[peer] < rf.Match_Idx[peer]+1 {
rf.Next_Idx[peer] = rf.Match_Idx[peer] + 1
}
DPrintf("leader node{%v} log{%v}", rf.me, rf.Log_Array)
} else {
rf.Next_Idx[peer] = reply.LastIdx + 1
DPrintf("Node{%v} to peer{%v} conflict and to the last_idx{%v} + 1", rf.me, peer, reply.LastIdx)
}还有就是match_idx的含义。match_idx应该是保守的,commit_idx不代表match_idx,代表的是大部分match_idx
func (rf *Raft) AppendNewEntries(command interface{}) LogEntry {
new_entries := LogEntry{Command: command, Log_Term: rf.CurrentTerm, Index: rf.lastIncludeIdx + len(rf.Log_Array)}
rf.Log_Array = append(rf.Log_Array, new_entries)
rf.persist()
for i := range rf.peers {
// rf.Match_Idx[i] = rf.Committed_Idx
rf.Next_Idx[i] = rf.GetLastLog().Index
}
rf.Match_Idx[rf.me] = rf.GetLastLog().Index
return new_entries
}虽然nextIndex和matchIndex通常同时更新为相似的值(具体来说,nextIndex = matchIndex + 1),但两者的用途却截然不同。nextIndex是关于领导者与给定追随者共享什么前缀的猜测。它通常是相当乐观的(我们分享一切),并且只有在出现负面反应时才会倒退。例如,当一个领导者刚刚被选举出来时, nextIndex在日志的末尾设置为索引索引。在某种程度上, nextIndex用于性能——你只需要将这些东西发送给这个对等点。 matchIndex用于安全。它是对领导者与给定追随者共享的日志前缀的保守测量 。matchIndex永远不能设置为太高的值,因为这可能会导致commitIndex向前移动太远。这就是为什么 matchIndex初始化为 -1(即,我们同意没有前缀),并且仅在跟随者肯定确认RPC 时才更新AppendEntries。么前缀的猜测。它通常是相当乐观的(我们分享一切),并且只有在出现负面反应时才会倒退。例如,当一个领导者刚刚被选举出来时, nextIndex在日志的末尾设置为索引索引。在某种程度上, nextIndex用于性能——你只需要将这些东西发送给这个对等点。
matchIndex用于安全。它是对领导者与给定追随者共享的日志前缀的保守测量 。matchIndex永远不能设置为太高的值,因为这可能会导致commitIndex向前移动太远。这就是为什么 matchIndex初始化为 -1(即,我们同意没有前缀),并且仅在跟随者肯定确认RPC 时才更新AppendEntries。