【股票分析一】Tushare获取股票基础数据,日线数据,历史分笔数据
Tushare ID:421411
股票基础数据和日线数据的接口用的是新版的tushare,分笔数据的接口只有在旧版才有。
1.设置token,获取api
# getdata.py
import numpy as np
import pandas as pd
import tushare as ts
import datetime
import time
import datetime
import csv
import os
ts.set_token('你的tushare用户的token的一串字符')#设置token,只需设置一次
pro = ts.pro_api()#初始化接口
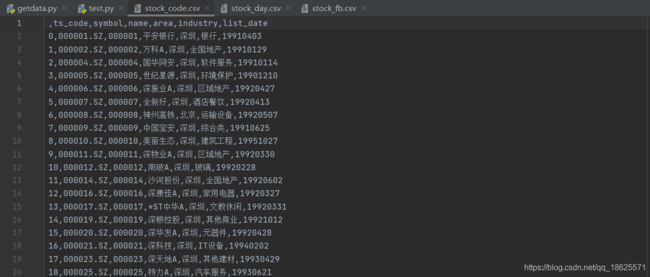
2.获取股票基本信息,存储到CSV文件
def get_stock_basicData(basic_file):
#获取股票基本信息,存储到CSV文件
# basic_file:股票基本信息的文件名(含后缀)
# basic_file='stock_code.csv'
# list_status='L' L:股票状态为上市
stock_code=pro.stock_basic(exchange='', list_status='L', fields='ts_code,symbol,name,area,industry,list_date') #新版tushare的接口
stock_code.to_csv(basic_file)
print('get_stock_basicData ok')
3.截取股票
def get_stock_code(date,basic_file):
# date:截取1992-01-01前上市的股票
# 如 date='1992-01-01' basic_file='stock_code.csv'
code=pd.read_csv(basic_file,index_col='list_date',parse_dates=['list_date'])
code=code[:date] #截取date前上市的股票
print('get_stock_code ok')
return code
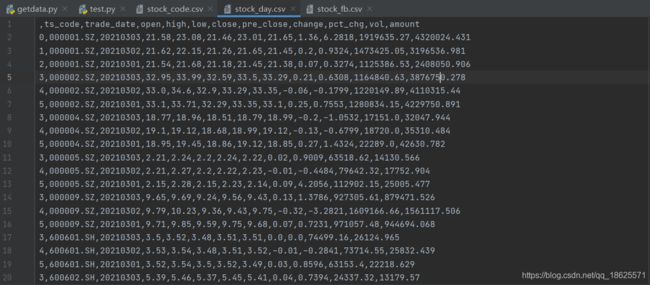
4.获取截取的股票指定日期间的日线行情,存储到CSV文件
def get_stock_data_dailyData(code,start,end,day_file):
#获取20210301到20210303所有股票的日线
#格式:code=get_stock_code返回的值 start='20210301' end='20210303' day_file='stock_day.csv' 字符类型
len_code=len(code)
df=pro.daily(ts_code=str(code.iloc[0]['ts_code']), start_date=start, end_date=end) #新版tushare的接口
df.to_csv(day_file)
df = pd.read_csv(day_file)
len_df=len(df)
for j in range(1,len_code):
df1=pro.daily(ts_code=str(code.iloc[j]['ts_code']), start_date=start, end_date=end)
df1=np.array(df1)
df2=[] #用于定位
len_df1 = len(df1)
for i in range(0,len_df1):
df2.append(i+len_df)
df2=np.array(df2)
df1=np.c_[df2,df1] #格式化
if os.path.isfile(day_file): #写入csv
with open(day_file,'a') as f: #‘a’:循环写入防止覆盖
writer=csv.writer(f,lineterminator='\n') #lineterminator 去掉多余的行
writer.writerows(df1)
print('get_stock_data_dailyData ok')
5.获取截取的股票指定日期间的历史分笔数据,存储到CSV文件
def get_stock_fbData(code,start,end,fb_file):
# 获取2021-03-01到2021-03-31所有股票的分笔数据
# 格式:code=get_stock_code返回的值 start='2021-03-01' end='2021-03-31' fb_file='stock_fb.csv' 字符类型
# 1. 创建文件对象
f = open(fb_file, 'w', encoding='utf-8')
# 2. 基于文件对象构建 csv写入对象
writer = csv.writer(f)
# 3. 构建列表头
writer.writerow(['', 'date', 'time', 'price', 'change', 'volume', 'amount', 'type', 'code'])
f.close()
len_code=len(code)
#直接把日期字符串拆分转换成 年 / 月 / 日 对应的整数
begin = datetime.date(*map(int, start.split('-'))) # str 转为 datetime.date
end = datetime.date(*map(int, end.split('-')))
delta = datetime.timedelta(days=1)
df=pd.read_csv(fb_file)
len_df=len(df)
for j in range(0,len_code):
d = begin #日期
while d <= end:
da=d.strftime("%Y-%m-%d")
zb=ts.get_tick_data(str(code.iloc[j]['symbol']).zfill(6),date=str(da), src='tt') #旧版tushare的接口获取分笔数据, zfill(6):高位填充0位6位数
zb=np.array(zb)
if zb.all() is not None: #该股票改日有分笔数据
len_zb=len(zb)
date=np.array([str(da)]*len_zb) #日期
c=np.array([str(code.iloc[j]['symbol']).zfill(6)]*len_zb) #股票代码
zb=np.c_[date,zb[:,0:],c]
df2=[]
for i in range(0,len_zb):
df2.append(i+len_df)
len_df += len_zb
df2=np.array(df2)
zb=np.c_[df2,zb] #格式化
if os.path.isfile(fb_file): #写入
with open(fb_file,'a',encoding='utf-8') as f:
writer=csv.writer(f,lineterminator='\n')
writer.writerows(zb)
d += delta
print('get_stock_fbData ok')
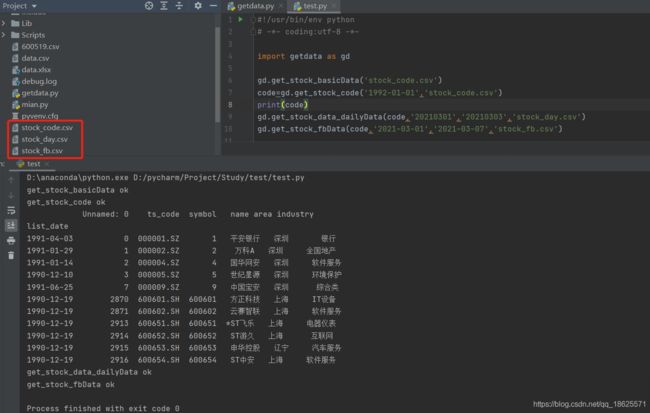
6.测试
# test.py
import getdata
getdata.get_stock_basicData('stock_code.csv')
code=getdata.get_stock_code('1992-01-01','stock_code.csv')
print(code)
getdata.get_stock_data_dailyData(code,'20210301','20210303','stock_day.csv')
getdata.get_stock_fbData(code,'2021-03-01','2021-03-07','stock_fb.csv')
7.结果