MySQL的基本概念与操作
MySQL的基本概念与操作
2019年05月28日 14:44:40 44478788 阅读数:138
数据库的基本概念
- 什么是数据库?
用于存储和管理数据的仓库。 - 数据库的特点:
持久化存储数据的。其实数据库就是一个文件系统
方便存储和管理数据
使用了统一的方式操作数据库 – SQL - 数据库的分类:
数据库根据存储采用的数据结构的不同可以分为许多种,其中包含早期的层次式数据库、网络式数据库。
目前占市场主流的是关系型数据库。当然还有非关系(NoSQL)型数据库(键值对数据库,例如:MongoDB、Redis)等其他类型的数据库 - 常见的关系型数据库:
SQL Server : 微软提供(收费、Java中使用不多)
Oracle 甲骨文公司(收费、功能强大、性能优异,Java中使用者很多)
DB2 : IBM(收费、中型/大型、银行/电信等企业)
MySQL : 瑞典MySQL AB(免费开源、小型、性能也不差、适用于中小型项目、可集群)
SQLite : 迷你数据库,嵌入式设备中
…
MySQL数据库软件
-
安装
参考该博客: [https://blog.csdn.net/zhujialiang18/article/details/79780131] -
卸载
推荐使用Total Uninstall 6傻瓜式卸载 -
启动
MySQL服务启动1. cmd--> services.msc 打开服务的窗口 2. 使用管理员打开cmd net start mysql : 启动mysql的服务 net stop mysql:关闭mysql服务- 1
- 2
- 3
- 4
MySQL登录
1. mysql -uroot -p密码 2. mysql -hip -uroot -p连接目标的密码 3. mysql --host=ip --user=root --password=连接目标的密码- 1
- 2
- 3
MySQL退出
1. exit 2. quit- 1
- 2
SQL
-
什么是SQL?
Structured Query Language:结构化查询语言 其实就是定义了操作所有关系型数据库的规则。每一种数据库操作的方式存在不一样的地方,称为“方言”。- 1
- 2
-
SQL通用语法
1. SQL 语句可以单行或多行书写,以分号结尾。 2. 可使用空格和缩进来增强语句的可读性。 3. MySQL 数据库的 SQL 语句不区分大小写,关键字建议使用大写。 4. 3 种注释 单行注释: -- 注释内容 或 # 注释内容(mysql 特有) 多行注释: /* 注释 */- 1
- 2
- 3
- 4
- 5
- 6
-
SQL分类
1. DDL(Data Definition Language)数据定义语言 用来定义数据库对象:数据库,表,列等。关键字:create, drop,alter 等 2. DML(Data Manipulation Language)数据操作语言 用来对数据库中表的数据进行增删改。关键字:insert, delete, update 等 3. DQL(Data Query Language)数据查询语言 用来查询数据库中表的记录(数据)。关键字:select, where 等 4. DCL(Data Control Language)数据控制语言(了解) 用来定义数据库的访问权限和安全级别,及创建用户。关键字:GRANT, REVOKE 等- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
DDL:操作数据库、表
1. 操作数据库:CRUD
(1) C(Create):创建
创建数据库:
create database 数据库名称;
创建数据库,判断不存在,再创建:
create database if not exists 数据库名称;
创建数据库,并指定字符集
create database 数据库名称 character set 字符集名;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
(2) R(Retrieve):查询
查询所有数据库的名称:
show databases;
查询某个数据库的字符集:查询某个数据库的创建语句:
show create database 数据库名称;
- 1
- 2
- 3
- 4
(3) U(Update):修改
修改数据库的字符集
alter database 数据库名称 character set 字符集名称;
- 1
(4)D(Delete):删除
删除数据库
drop database 数据库名称;
判断数据库存在,存在再删除
drop database if exists 数据库名称;
- 1
- 2
- 3
- 4
(5) 使用数据库
查询当前正在使用的数据库名称
select database();
使用数据库
use 数据库名称;
- 1
- 2
- 3
- 4
2. 操作表
(1) C(Create):创建
创建表:
create table 表名(
列名1 数据类型1,
列名2 数据类型2,
....
列名n 数据类型n
);
注意:最后一列,不需要加逗号(,)
约束:对表中的数据进行限定,保证数据的正确性、有效性和完整性
* 非空约束:not null,值不能为null。保证所约束的列必须是不为空的,即在插入记录时,该列必须要赋值,例如:用户注册时,保存的密码不能为空。
创建表时添加约束
creare table stu(
id int,
name varchar(20) not null -- name为非空
);
* 唯一约束:unique,值不能重复。保证所约束的列必须是唯一的,即不能重复出现,例如:用户注册时,保存的用户名不可以重复。
创建表时,添加唯一约束
creare table stu(
id int,
phone_number varchar(20) unique -- 添加了唯一约束
);
* 注意mysql中,唯一约束限定的列的值可以有多个null
* 主键约束:primary key。唯一且不能为空,一张表只能有一个字段为主键。
在创建表时,添加主键约束
create table stu(
id int primary key,-- 给id添加主键约束
name varchar(20)
);
4. 自动增长:如果某一列是数值类型的,使用 auto_increment 可以来完成值得自动增长。
在创建表时,添加主键约束,并且完成主键自增长
create table stu(
id int primary key auto_increment,-- 给id添加主键约束
name varchar(20)
);
5. 外键约束:foreign key,让表于表产生关系,从而保证数据的正确性。
在创建表时,可以添加外键
create table 表名(
....
外键列
constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称)
);
复制表:
create table 表名 like 被复制的表名;
数据库数据类型
tinyint:占用1个字节,相对于java中的byte
smallint:占用2个字节,相对于java中的short
int:占用4个字节,相对于java中的int
bigint:占用8个字节,相对于java中的long
float:4字节单精度浮点类型,相对于java中的float
double:8字节双精度浮点类型,相对于java中的double
date:日期,只包含年月日,yyyy-MM-dd
datetime:日期,包含年月日时分秒 yyyy-MM-dd HH:mm:ss
timestamp:时间戳型 包含年月日时分秒 yyyy-MM-dd HH:mm:ss
如果将来不给这个字段赋值,或赋值为null,则默认使用当前的系统时间,来自动赋值
char(n) 定长字符串,最长255个字符。n表示字符数
varchar(n):变长字符串,最长不超过 65535个字节,n表示字符数,一般超过255个字节,超过会使用text类型,例如
* name varchar(20):姓名最大20个字符
* zhangsan 8个字符 张三 2个字符;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
(2) R(Retrieve):查询
查询某个数据库中所有的表名称:
show tables;
查询表结构:
desc 表名;
- 1
- 2
- 3
- 4
(3)U(Update):修改
修改表名
alter table 表名 rename to 新的表名;
修改表的字符集
alter table 表名 character set 字符集名称;
修改列名称 类型
alter table 表名 change 列名 新列别 新数据类型;
alter table 表名 modify 列名 新数据类型
删除列
alter table 表名 drop 列名;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
(4) D(Delete):删除
删除表
drop table 表名;
判断表存在,存在再删除
drop table if exists 表名 ;
- 1
- 2
- 3
- 4
DML:增删改表中数据
-
添加数据
语法:insert into 表名(列名1,列名2,...列名n) values(值1,值2,...值n); 创建数据库,判断不存在,再创建: * 注意: 1.只能在给所有列插入值时, 才可以省略列列表, 否则会报错 2. 列名和值要一一对应。 3. 如果表名后,不定义列名,则默认给所有列添加值 insert into 表名 values(值1,值2,...值n) 4. 除了数字类型,其他类型需要使用引号(单双都可以)引起来 5. 插入数据时或者查询数据时先确保编码是否一致- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
删除数据
语法:delete from 表名 [where 条件]; * 注意: 1. 如果不加条件,则删除表中所有记录 2. 如果要删除所有记录 1. delete from 表名; -- 不推荐使用。有多少条记录就会执行多少次删除操作 2. TRUNCATE TABLE 表名; -- 推荐使用,效率更高 先删除表,然后再创建一张一样的表。- 1
- 2
- 3
- 4
- 5
- 6
查询某个数据库的字符集:查询某个数据库的创建语句:
show create database 数据库名称;- 1
-
修改数据
语法:update 表名 set 列名1 = 值1, 列名2 = 值2,... [where 条件]; * 注意: 如果不加任何条件,则会将表中所有记录全部修改 如果修改列存在null值时:null值和任何值计算结果还是null, 因此, 可以通过ifnull函数将null置为零对待.- 1
- 2
- 3
- 4
DQL:查询表中的记录
-
语法
select 字段列表 from 表名列表 where 条件列表 group by 分组字段 having 分组之后的条件 order by 排序 limit 分页限定- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
-
基础查询
(1) 多个列名的查询:select 列名1,列名2... from 表名; * 注意: * 如果查询所有,则可以使用*来替代列表- 1
- 2
- 3
(2)去除重复:
select distinct 列名 from 表名;- 1
(3)起别名:
select 列名1 as XXX, from 表名; as也可以省略- 1
- 2
-
条件查询
(1) where子句后跟条件......form 表名 where 子句;- 1
(2)运算符
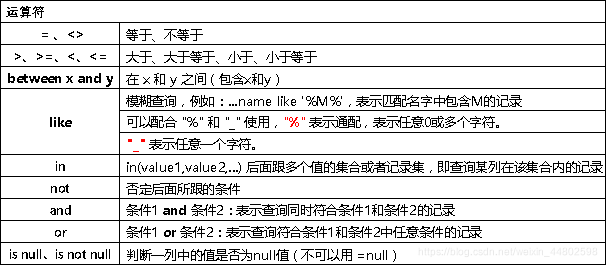
(3)排序查询-
语法:
order by 排序字段1 排序方式1 , 排序字段2 排序方式2...- 1
-
排序方式:
* ASC:升序,默认的 * DESC:降序- 1
- 2
-
注意:
如果有多个排序条件,则当前边的条件值一样时,才会判断第二条件- 1
(4)聚合函数
1. count:计算个数 2. max:计算最大值 3. min:计算最小值 4. sum:计算和 5. avg:计算平均值 * 注意:聚合函数的计算,排除null值。 解决方案: 1. 选择不包含非空的列进行计算 2. IFNULL函数- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
(5)分组查询
-
语法:
group by 列名- 1
where 和 having 的区别?
where 在分组之前进行限定,如果不满足条件,则不参与分组。having在分组之后进行限定,如果不满足结果,则不会被查询出来 where 后不可以跟聚合函数,having可以进行聚合函数的判断。- 1
- 2
(6)分页查询
1. 语法:
limit 开始的索引,每页查询的条数
2. 公式:
开始的索引 = (当前的页码 - 1) * 每页显示的条数
3. 注意:
limit 是一个MySQL"方言"