机器学习---集成学习报告
1.原理以及举例
1.1原理
集成学习(Ensemble Learning)是一种机器学习策略,它通过结合多个基学习器(base learners)的预测来提高模型的性能。集成学习的目标是创建一个比单个基学习器更准确、更稳定的最终预测模型。这种方法可以减少过拟合、提高泛化能力,并在很多情况下,显著提高预测性能。
集成学习的主要原理包括:
多样性(Diversity):基学习器应该在某种程度上具有差异,从而降低它们共同犯错的概率。多样性可以通过使用不同的训练数据、不同的基学习算法或不同的参数设置来实现。
结合策略(Combining Strategy):集成学习需要一个合适的策略来结合基学习器的预测结果。常见的结合策略包括投票法(Majority Voting,用于分类任务)、平均法(Averaging,用于回归任务)和加权法(Weighted Voting/Averaging,根据基学习器的性能分配权重)。
集成学习的常见方法包括:
Bagging(Bootstrap Aggregating):通过自助采样(Bootstrap Sampling)的方法从原始数据集中抽取多个子集,并训练多个基学习器。最终预测结果通过投票(分类任务)或平均(回归任务)得到。
Boosting:Boosting 是一种迭代方法,每个基学习器在训练时对前一个学习器犯错的样本进行加权,从而关注这些难以分类或预测的样本。预测结果通过加权投票(分类任务)或加权平均(回归任务)得到。常见的 Boosting 算法包括 AdaBoost、Gradient Boosting 和 XGBoost。
Stacking(Stacked Generalization):训练多个基学习器,然后使用一个新的学习器(称为元学习器或次级学习器)将基学习器的输出作为输入进行训练。元学习器负责将这些基学习器的预测结果进行组合,生成最终预测结果。
通过这些方法,集成学习可以提高模型的预测性能、减少过拟合,并提高泛化能力。
1.2举例
假设我们有一个二分类问题,数据集包含以下数据:
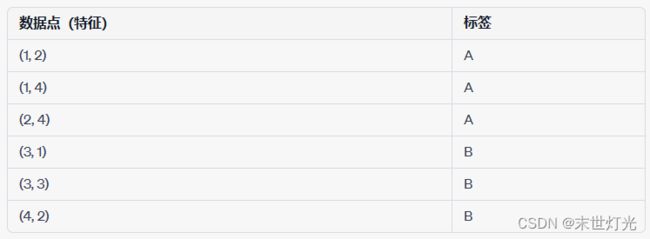
我们将使用Bootstrap Aggregating(Bagging)方法结合3个决策树分类器(DT1,DT2,DT3)来解决这个问题。
对于每个基分类器,我们从原始数据集中随机抽样(有放回)一定数量的样本,形成新的训练集。例如,每个基分类器的训练集可能如下:
DT1 训练集: (1, 2, A), (2, 4, A), (3, 1, B), (3, 3, B)
DT2 训练集: (1, 4, A), (2, 4, A), (3, 3, B), (4, 2, B)
DT3 训练集: (1, 2, A), (1, 4, A), (3, 1, B), (4, 2, B)
使用这些新训练集分别训练3个决策树分类器。
对于新的未知数据点,例如(2, 3),我们使用这3个分类器进行预测,然后根据它们的输出进行投票:
DT1 预测:A
DT2 预测:A
DT3 预测:B
结果是类别 A 获得了2票,类别 B 获得了1票。因此,Bagging 预测该数据点属于类别 A。
通过这种方法,Bagging结合了多个基分类器的预测,降低了单个分类器的过拟合风险,并提高了整体模型的泛化能力。
2.设计思路以及代码
2.1设计思路
我们将使用scikit-learn库实现一个Bagging分类器。我们将:
(1)从scikit-learn库中导入所需的工具和数据集。
(2)实现一个Bagging分类器,其中基分类器为决策树。
(3)使用三个不同的数据集对分类器进行评估。
2.2代码实现
import numpy as np
from sklearn.datasets import load_iris, load_wine, load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
datasets = {
'Iris': load_iris(),
'Wine': load_wine(),
'Breast Cancer': load_breast_cancer()
}
# 初始化决策树和Bagging分类器
base_classifier = DecisionTreeClassifier()
bagging_classifier = BaggingClassifier(base_estimator=base_classifier, n_estimators=10, random_state=42)
# 评估Bagging分类器在不同数据集上的性能
results = {}
for dataset_name, dataset in datasets.items():
X_train, X_test, y_train, y_test = train_test_split(dataset.data, dataset.target, test_size=0.3, random_state=42)
bagging_classifier.fit(X_train, y_train)
y_pred = bagging_classifier.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
results[dataset_name] = accuracy
print("Bagging分类器在不同数据集上的准确率:")
for dataset_name, accuracy in results.items():
print(f"{dataset_name}: {accuracy:.4f}")
3.测试结果
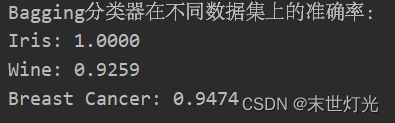
根据测试结果,我们可以看到Bagging分类器在这三个数据集上的表现都非常好。这表明Bagging方法可以有效地减少过拟合,提高模型的泛化能力。