Zero-Shot Out-of-Distribution Detection Based on the Pre-trained Model CLIP 论文解读
文章目录
-
-
- 前言
- Motivation
- Innovation
- Method
- Experiments
- Future work
-
前言
这篇是我关于zero-shot读的第2篇文章,和我之前读的关于OOD Detection方向的文章有了连接。但是OOD Detection相对于Zero-shot任务来说还是有所不同的,解释一下这两者的不同之处:
OOD(Out-of-Distribution) Detection
-
基本目的是区分(辨别)样本究竟是分布内的还是分布外的,如果是分布内,label为1;分布外label为0。任务更偏向于异常检测。全CV任务。
-
实验设置基本为采用大规模多标签数据集进行训练(如VOC, COCO, NUS-WIDE),采用多标签数据集+单标签OOD小规模数据集(如ImageNet中的20类、Texture等)进行测试,训练和测试样本来自于不同的数据集。
-
评价指标主要为AUROC, AUPR, FPR95。
Zero-shot learning
-
基本目的为通过对已知类别的图像和语义信息进行学习,构建出图像和语义之间的映射, 在未知类别语义信息的辅助下实现未知图像的识别。任务更偏向于多标签识别(即输出某类标签的score)。CV+NLP。
-
实验设置基本为采用大规模多标签数据集进行训练和测试(如 NUS-WIDE, Open Image),测试和训练样本基本都来自于同一数据集。该数据集的大部分标签可见,少部分的标签不可见。
-
评价指标主要为mAP, F1 score。
这篇文章主要讲的是用zero-shot的思路解决OOD Detection的问题,我希望能读完这篇文章之后产生用OOD解决zero-shot的思路!
Motivation
之前的方法都是基于封闭世界理论,训练出一个准确的分类器完成OOD Detection任务,没有用到预训练模型。并且都要使用可见类别的标记样本来训练分类器。本篇文章中作者使用了预训练模型CLIP完成2项任务:1) 识别测试样本属于可见类中的某一类。2)检测样本是否属于未见类。训练阶段本文没有刻意选择与可见标签对应的图像样本进行训练,而是用通用数据集进行训练,测试的时候直接用可见类别样本测试,所以没有用到任何直接与可见类相关的训练数据(当然,通用数据集中可能包含与可见类相关的样本)。
Innovation
- 把实现zero-shot任务的预训练模型CLIP拓展到OOD Detection任务中。主要是在CLIP图像编码器的基础上,训练一个伪OOD标签生成器。
- 上述标签生成器生成的标签作为图像的未见类候选标签
- 在可见标签和生成伪标签的基础上,定义了一个新的OOD confidence score。
Method
文中提出的方法称为ZOC( Zero-shot OOD detection based on CLIP)。文中提到的算法框架有 2 steps,对于集合也是有 2 sets,对于这篇文章我觉得创新性比较大的还是构建的unseen label generator,是依靠decoder架构的。下面依赖这张图来解释一下2 steps & 2 sets.
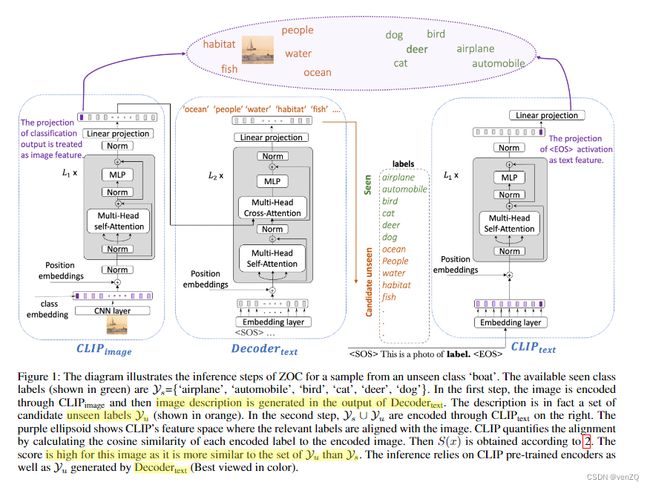
2 Sets
- the set of seen labels.
- the set of unseen labels which are unknown.
关于这些sets在图中的流向,我们会有以下的一些发现:
- 在图中标注着 “label” 的虚线方框中,上方绿色的为seen sets,下方橙色的为unseen sets。
- 在 D e c o d e r t e x t Decoder_{text} Decodertext上方的方框中,看出它的输出实际为那些candidate unseen sets。
- 两个sets的label会与一个templace组合(图中的"This is a photo of …"),作为 C L I P t e x t CLIP_{text} CLIPtext的输入。
- 在上方紫色椭圆形中,图像和label都被投影到同一个子空间中,在这里它们会做一些距离相似度的比较,以此划分样本为分布内还是分布外的。
2 Steps
- Training the Image Description Generator
- Inference in Testing
Step1主要包含了Fig.1中的 C L I P i m a g e CLIP_{image} CLIPimage和 D e c o d e r t e x t Decoder_{text} Decodertext两部分。
第一个框中的 C L I P i m a g e CLIP_{image} CLIPimage直接用了CLIP_ViT的预训练模型,实际上这个部分就是类似Transformer的Encoder部分,包含positional embedding, multi-head self attention, layer-norm, MLP那些个成分。需要注意的是,图像经过CNN backbone提取出image embedding后,该部分会多加入一维class embedding,这一维我们也认为是图像的一个特征。该模块的输出设为 z o u t z_{out} zout,作为图像的语义空间表示。语义空间就是紫色椭圆表示的空间。
第二个框中,第一个框输出的 Z o u t Z_{out} Zout作为 D e c o d e r t e x t Decoder_{text} Decodertext的key和value输入进来,而query是训练数据集的label+template。如使用COCO训练,里面有个标签person,输入进来的就是"This is a photo of person." 经过Decoder模块,最后一层输出还需要经过一个线性层投影到vocabulary space,以此来生成candidate label。使用一个时序优化的loss function,保证预测尽量靠近我们输入的语句(有点类似最近chatgpt语句生成的思想),我们希望生成的类别语义与图片越相关越好。

Step2主要是推理过程,使用训练好的 D e c o d e r t e x t Decoder_{text} Decodertext作为description generator. 而unseen label是以上述生成的description为基础去检索出来的。根据每一个时间节点,选出一个具有最大概率的label。
assuming the maximum generation length is T , at each position pi of {p1, p2, …, pT }, we pick the top k words from the vocabulary with highest probabilities. The union of all these words is Y_u.
然后把定义的seen labels set(set1) 和刚刚生成的unseen label set(set2) 合并,搭配template放进 C L I P t e x t CLIP_{text} CLIPtext里面,这里也是直接用CLIP的预训练权重来做的。图中 C L I P t e x t CLIP_{text} CLIPtext的输出又经过了一个线性投影,才投影到公共子空间的(也就是我们刚才说的语义空间),这个时候它与image feature的维度是一样的,可以作相似度比较。
对于计算相似度后得出来的logits,做一下softmax,然后把关于seen label set的概率相加,根据下面的公式得出OOD Score:

PS: 这里有个问题,我不知道投影到紫色椭圆子空间的是image feature(就是那多加的1维),还是整个z_out,这个得根据实际的代码看看,有空再去学习。
如果看不懂上面的讲解,可以看一下伪代码。2 steps的伪代码如下:

Experiments

关于各个数据集的setting在这里就不细讲了,但他们的openness是不一样的,可以从原文中查找。Table 1 表格的前8种方法都是用train classifer from scratch的方法来做的,而本文采用的是结合预训练CLIP来做,AUROC有较高的提升。同时作者还用预训练CLIP结合了部分传统方法来做,也是有一定提升的。CLIP+MSP证明了CLIP在OOD Detection具有的固有实力。

Fig. 2 主要是体现了ZOC方法的部分识别实例,体现了它能够完成开头提出的2个任务。虽然有的图片会识别错误,但是识别的label也是非常贴近groundtruth的意义。右边的图是概率直方图,比较有趣的是tractor和school bus的对比,几乎可以说是互补的,因为他们俩含义比较像,模型错分的几率比较大。
本文并没有进行消融实验,因为提出的创新模块也仅有 D e c o d e r t e x t Decoder_{text} Decodertext一个部分,也没有什么特殊的threshold需要调,没有一个模块是可以drop掉的。
Future work
- use a larger corpus to train the image description generator
- Explore the relations between the unseen labels.