human evaluation-Totto
human evaluation-Totto
- Totto
-
- case 1-1
- case 2-2
- case 3-5
- case 4-6
- case 5-9
- case 6-10
- case 7-14
- case 8-18
- case 9-19
- case 10-24
- case 11-25
- case 12-27
- case 13-30
- case 14-32
- case 15-33
- case 16-41
- case 17-42
- case 18-43
- case 19-49
- case 20-50
- case 21-55
- case 22-57
- case 23-60
- case 24-64
- case 25-65
- case 26-66
- case 27-69
- case 28-74
- case 29-75
- case 30-76
- case 31-82
- case 32-83
- case 33-88
- case 34-89
- case 35-90
- case 36-95
- case 37-96
- case 38-106
- case 39-109
- case 40-112
Totto
一共40个case,每个case包含一张表格,一个gold reference,以及两个模型分别得到的表格描述,我们希望能够对每个模型的描述进行人工评测,分别从fluency(流利度)、coverage(覆盖性,侧重和gold的重合度)、relevance(对于表格内容是否真实的反应以及关联程度)、overal quality(整体印象的评分),分数从1-5分,1分最差,5分最好。
[0, 1, 4, 5, 8, 9, 13, 17, 18, 23, 24, 26, 29, 31, 32, 40, 41, 42, 48, 49, 54, 56, 59, 63, 64, 65, 68, 73, 74, 75, 81, 82, 87, 88, 89, 94, 95, 105, 108, 111]
case 1-1
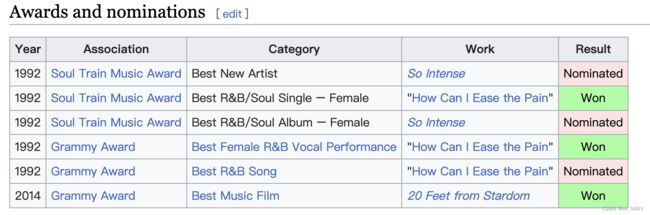
| link | https://en.wikipedia.org/wiki/Lisa_Fischer |
|---|---|
| gold | Fischer’s How Can I Ease the Pain won her a Grammy Award for Best Female R&B Vocal Performance in 1992 |
| 1 | Lisa Fischer won the 1992 Soul Train Music Award for Best R&B/Soul Album – Female |
| 2 | Fischer won the 1992 Grammy Award for Best Female R&B Vocal Performance for “How Can I Ease the Pain” |
| 3 | “How Can I Ease the Pain” was nominated for the 1992 Soul Train Music Award |
case 2-2
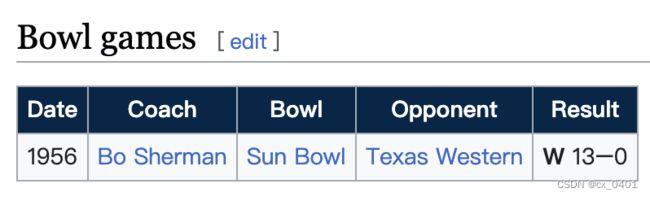
| link | http://en.wikipedia.org/wiki/George_Washington_Colonials_football |
|---|---|
| gold | In 1956, George Washington Colonials scored 13–0 against Texas Western at the Sun Bowl |
| 1 | George Washington Colonials won the 1956 Sun Bowl against Texas Western |
| 2 | George Washington Colonials beat Texas Western 13–0 in the Sun Bowl |
| 3 | George Washington Colonials defeated Texas Western 13–0 in the Sun Bowl |
case 3-5
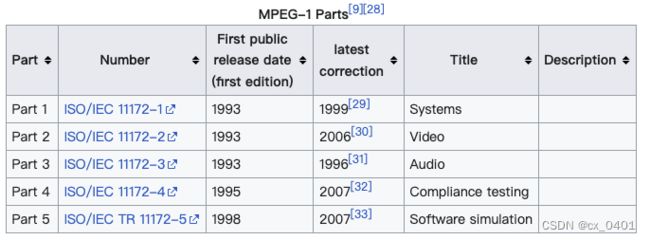
| link | http://en.wikipedia.org/wiki/MPEG-1 |
|---|---|
| gold | Part 1 of the MPEG-1 system is defined in ISO/IEC-11172-1 |
| 1 | ISO/IEC 11172-2 was first published in 1993 |
| 2 | In 1993, MPEG-1 was released as part of the ISO/IEC 11172-2 release |
| 3 | The first version of MPEG-1 was released in 1993 |
case 4-6
| link | https://en.wikipedia.org/wiki/Vartholomio |
|---|---|
| gold | Vartholomio´s population was 5,899 in 2011, of which 3,603 lived in the town |
| 1 | Vartholomio has a population of 3,216 |
| 2 | In 2011, Vartholomio had a population of 4,271 |
| 3 | In 2011 Vartholomio had a population of 3,603 |
case 5-9
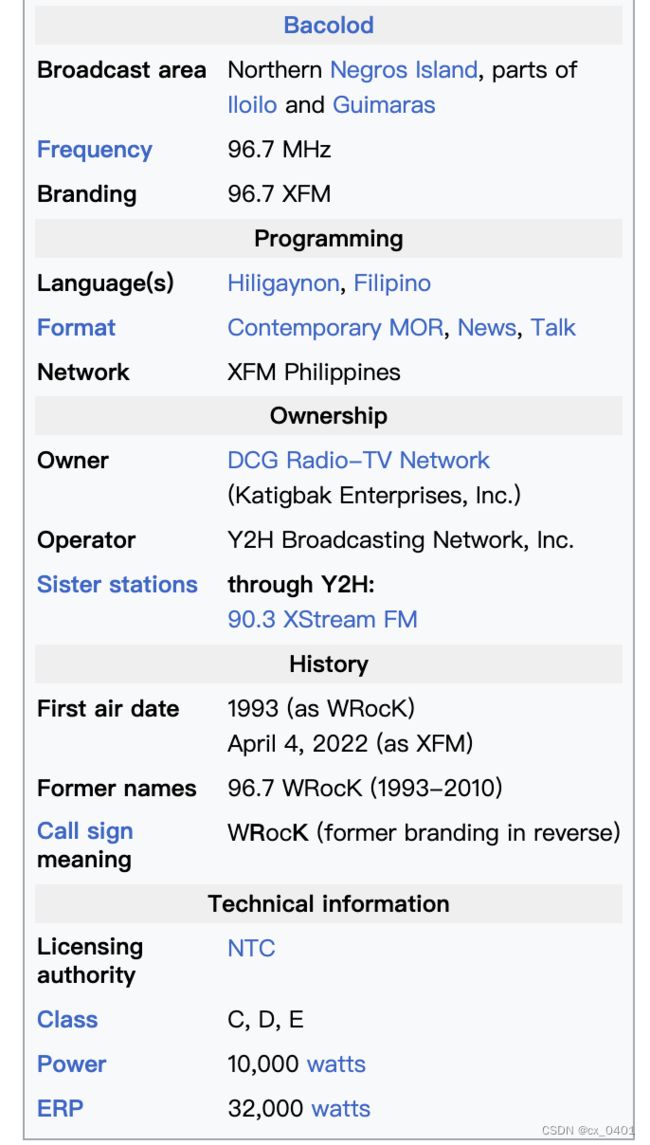
| link | http://en.wikipedia.org/wiki/DYKR |
|---|---|
| gold | DYKR FM was broadcasted as 96.7 WRocK Bacolod |
| 1 | WRocK Bacolod is a radio station in Bacolod, Cebu |
| 2 | Retro 95.5 (formerly WRocK Davao) has 95.5 MHz radio frequency |
| 3 | The DYKR-FM station is on 96.3 WRocK Cebu and 96.7 WRocK Bacolod |
case 6-10

| link | http://en.wikipedia.org/wiki/Lucius_Neratius_Marcellus |
|---|---|
| gold | Marcellus was consul twice, first in 95 and again in 129 |
| 1 | Lucius Neratius Marcellus was consul with Lucius Neratius Marcellus |
| 2 | Lucius Neratius Marcellus was consul with Titus Flavius Clemens |
| 3 | Lucius Neratius Marcellus was the consul with Titus Avidius Quietus in 88 |
case 7-14
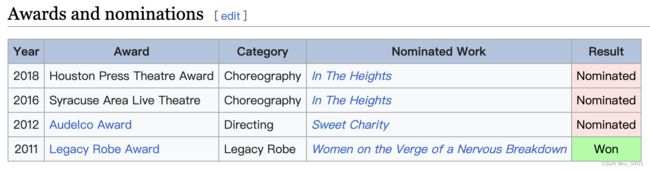
| link | http://en.wikipedia.org/wiki/Julio_Agustin |
|---|---|
| gold | In 2012, Agustin directed Sweet Charity at The New Haarlem Arts Theatre |
| 1 | Agustin directed the 2007 show, Out of Line, at the Pennsylvania Center Stage |
| 2 | In 2008, Julio Agustin played the role of Director / Choreographer in Whistle Down the Wind |
| 3 | Julio Agustin worked as a Director/Choreographer for the North Carolina Theatre, in 2008, and as Director for the 2012 show Sweet Charity at the New Haarlem Arts Theatre |
case 8-18

| link | http://en.wikipedia.org/wiki/Ink_(song) |
|---|---|
| gold | “Ink” peaked at number 156 on the UK Singles Chart |
| 1 | Ink (song) peaked at number 156 on the UK Singles chart |
| 2 | Ink peaked at number 156 on the UK Singles chart |
| 3 | Ink peaked at 156 on the UK Singles Chart |
case 9-19

| link | http://en.wikipedia.org/wiki/Singular_(band) |
|---|---|
| gold | In 2010, Singular released its first single, “24.7 (Twenty-Four Seven)” |
| 1 | Single is Bao Bao (Tender) |
| 2 | Singular’s single, Bao Bao, peaked at number 1 on the 2010 chart |
| 3 | Singular (band) reached number 3 on the Billboard 200, with 24.7 (Twenty-Four Seven) |
case 10-24
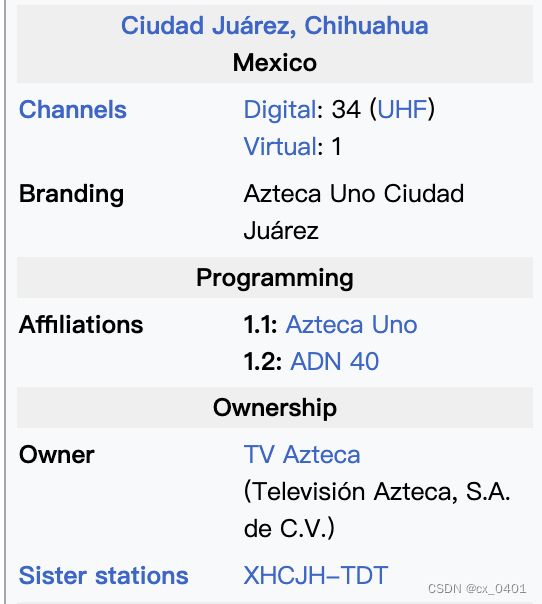
| link | http://en.wikipedia.org/wiki/XHCJE-TDT |
|---|---|
| gold | XHCJE broadcast the Proyecto 40 network on digital subchannel 34.3 (PSIP 1.2) |
| 1 | XHCJE 3 is a digital subchannel with 34.1 DT and 1.2 PSIP |
| 2 | The XHCJE channel Azteca 13 has a 16:9 DT on 1080i |
| 3 | The XHCJE-TDT has a resolution of 34.1 DT |
case 11-25

| link | http://en.wikipedia.org/wiki/Ogl%C4%99d%C3%B3w |
|---|---|
| gold | In 2002, there were 392 people residing in Oględów, of which 47.7% were male and 52.3% were female |
| 1 | According to the 2002 census, there were 392 people residing in Ogldów, of whom 50.5% were male and 49.5% were female |
| 2 | According to the 2002 census, there were 392 people residing in Ogldów, of whom 50.5% were male and 49.5% were female |
| 3 | According to the 2002 census, there were 392 people residing in Ogldów, of whom 50.8% were male and 49.2% were female |
case 12-27
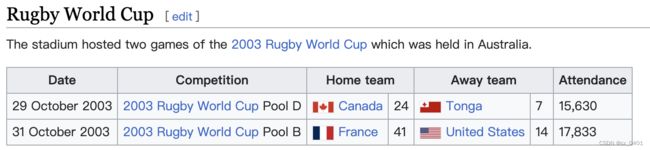
| link | http://en.wikipedia.org/wiki/Wollongong_Showground |
|---|---|
| gold | Wollongong Showground hosted two pool games in the 2003 Rugby World Cup. Canada defeated Tonga 24–7 in front of 15,630 fans, and France defeated the United States 41–14 in front of a crowd of 17,833 |
| 1 | On 29 October 2003, Canada hosted the 2003 Rugby World Cup Pool D at the Wollongong Showground |
| 2 | Canada defeated Tonga in the 2003 Rugby World Cup Pool B |
| 3 | In 2003 Rugby World Cup Pool D, Canada hosted the United States and Tonga |
case 13-30

| link | http://en.wikipedia.org/wiki/List_of_ambassadors_of_the_United_States_to_Italy |
|---|---|
| gold | Porter was appointed as Minister to Italy in 1889 |
| 1 | George P. Marsh served as the U.S. ambassador to Italy from 1871 to 1882 |
| 2 | George P. Marsh served as a U.S. ambassador to Italy from 1871 to 1882 |
| 3 | George P. Marsh was the U.S. Ambassador to Italy from 1871 to 1882 |
case 14-32
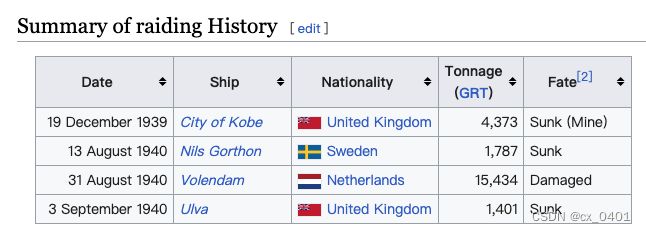
| link | http://en.wikipedia.org/wiki/German_submarine_U-60_(1939) |
|---|---|
| gold | U-60 sank three ships for a total of 7,561 (GRT) and damaging one other of 15,434 GRT |
| 1 | U-60 sank a 4,373 ton German submarine in Kobe on 19 December 1939 |
| 2 | On 19 December 1939, the German submarine U-60 raided Ulva with 4,373 tons |
| 3 | U-60 sank one ship a total of 4,373 gross register tons (GRT) |
case 15-33
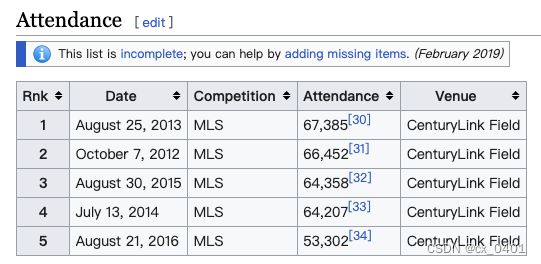
| link | http://en.wikipedia.org/wiki/Portland_Timbers%E2%80%93Seattle_Sounders_rivalry |
|---|---|
| gold | On October 7, 2012, Portland played against Seattle in MLS, with the second-largest crowd of 66,452 at CenturyLink Field |
| 1 | The Portland Timbers hosted the Seattle Sounders at CenturyLink Field on August 25, 2013 |
| 2 | The Portland Timbers–Seattle Sounders rivalry was held on August 25, 2013 at the CenturyLink Field |
| 3 | The Portland Timbers and Seattle Sounders rivalry was announced on August 25, 2013 in front of 67,385 fans at CenturyLink Field |
case 16-41

| link | http://en.wikipedia.org/wiki/Fiat_Croma |
|---|---|
| gold | Fiat Croma petrol engines, 1.8 L with 140 PS (103 kW), followed by the 2.2 L with 147 PS (108 kW) |
| 1 | The Fiat Croma-Petrol has a displacement of 1,796 cc and 140 PS (103 kW; 138 hp) at 6,300 rpm |
| 2 | Fiat Croma has 2,198 cc of torque and 147 PS (108 kW; 145 hp) at 5,800 rpm |
| 3 | The Fiat Croma is offered with an I4 DOHC 16V engine that generates 140 PS (103 kW; 138 hp) at 6,300 rpm |
case 17-42

| link | http://en.wikipedia.org/wiki/Minus_the_Bear |
|---|---|
| gold | Interpretaciones del Oso, an album of remixed songs from the album Menos el Oso, was released in 2007, by Suicide Squeeze Records |
| 1 | Menos el Oso was released on Suicide Squeeze Records in 2007 |
| 2 | In 2007, Minus the Bear remixed the album, Interpretaciones del Oso |
| 3 | In 2007, Minus the Bear remixed the albums Interpretaciones del Oso by Suicide Squeeze Records |
case 18-43
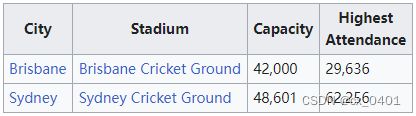
| link | http://en.wikipedia.org/wiki/Rugby_League_World_Cup_venues |
|---|---|
| gold | The Sydney Cricket Ground Stadium has a spectator capacity of 48,000 and was used as a Rugby League World Cup venue in 1957 |
| 1 | Brisbane hosted the Rugby League World Cup in 1957 |
| 2 | The Rugby League World Cup took place in 1957 at the Brisbane Cricket Ground in Brisbane, with 29,636 spectators |
| 3 | The Rugby League World Cup venues in Australia were Brisbane Cricket Ground, Sydney Cricket Ground and the Sydney Cricket Ground |
case 19-49
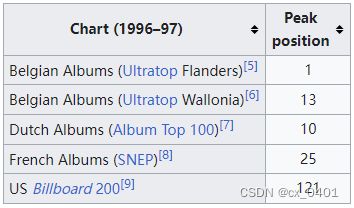
| link | http://en.wikipedia.org/wiki/Paradise_in_Me |
|---|---|
| gold | The Paradise in Me album reached #121 on the U.S. Billboard 200 chart |
| 1 | Paradise in Me peaked at #112 on the Billboard 200 and #112 on the Billboard 200 |
| 2 | Paradise peaked at number 121 on the Billboard 200 |
| 3 | Paradise in Me peaked at number 121 on the Billboard 200 chart |
case 20-50

| link | http://en.wikipedia.org/wiki/Qamdo_Bamda_Airport |
|---|---|
| gold | At an elevation of 4,334 m (14,219 ft) above sea level, Qamdo Airport was the highest airport in the world |
| 1 | Qamdo Bamda Airport is a reference airport to El Alto International Airport |
| 2 | Qamdo Bamda Airport was preceded by El Alto International Airport |
| 3 | Qamdo Bamda Airport is the 3rd largest airport in the United States, and is surpassed by El Alto International Airport |
case 21-55

| link | http://en.wikipedia.org/wiki/1906_Boston_Americans_season |
|---|---|
| gold | Jesse Tannehill with winning record, at 13–11, while Bill Dinneen had the lowest ERA, at 2.92 |
| 1 | George Winter had a record of 207 23 |
| 2 | Cy Young led the 1906 Boston Americans season with a 3.19 ERA |
| 3 | Cy Young led the 1906 Boston Americans season with a 3.19 ERA |
case 22-57

| link | http://en.wikipedia.org/wiki/1942_South_American_Championship |
|---|---|
| gold | The 1942 South American Championship featured a match between Argentina and Ecuador in which Argentina scored a 12–0 drubbing Ecuador |
| 1 | Argentina won the 1942 South American Championship, beating Ecuador 12–0 |
| 2 | Argentina defeated Ecuador 12–0 in the final round of the 1942 South American Championship |
| 3 | Argentina won the 1942 South American Championship beating Ecuador 12–0 in the final round |
case 23-60
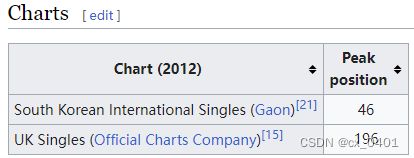
| link | http://en.wikipedia.org/wiki/The_Don_(Nas_song) |
|---|---|
| gold | “The Don” debuted on the UK Singles Chart at number 196 |
| 1 | The Don (Nas song) peaked at number 46 on the South Korean International Singles chart |
| 2 | The Don (Nas song) peaked at number 196 in the UK Singles |
| 3 | The Don (Nas song) peaked at number 196 on the UK Singles Chart |
case 24-64
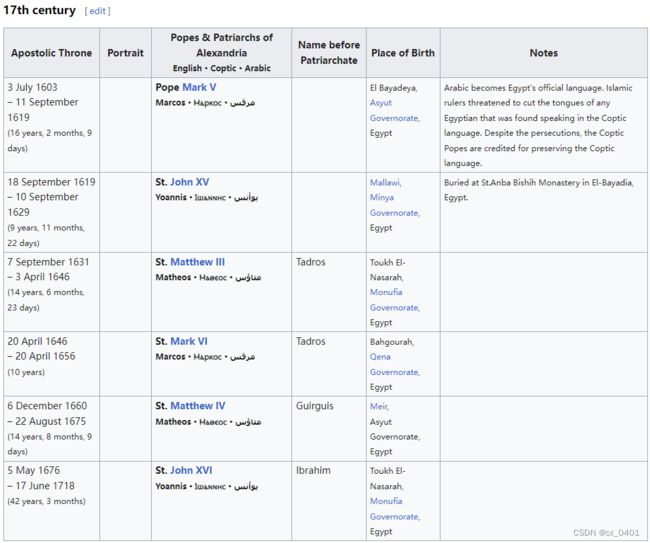
| link | http://en.wikipedia.org/wiki/List_of_Coptic_Orthodox_Popes_of_Alexandria |
|---|---|
| gold | Pope John XVI is Pope of Alexandria & Patriarch |
| 1 | Popes & Patriarchs of Alexandria were Popes Mark V Marcos, John XV Yoannis, and St. Matthew III Matheos |
| 2 | Popes & Patriarchs of Alexandria English were the Popes of Alexandria from 1603 to 1619 |
| 3 | St. Mark V Marcos was Pope of Alexandria & Patriarch |
case 25-65
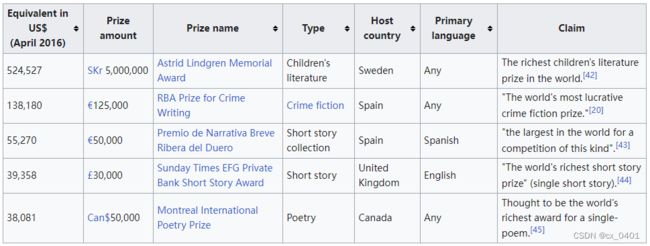
| link | http://en.wikipedia.org/wiki/List_of_richest_literary_prizes |
|---|---|
| gold | The award amount is €50,000, making it the largest in the world for an award of this kind |
| 1 | The RBA Prize for Crime Writing is the world’s most lucrative crime fiction prize |
| 2 | Astrid Lindgren Memorial Award was awarded as the richest children’s literature prize in the world |
| 3 | The Astrid Lindgren Memorial Award is the richest children’s literature prize in the world |
case 26-66

| link | http://en.wikipedia.org/wiki/Richard_Thompson_(sprinter) |
|---|---|
| gold | In 2014, Richard Thompson made a record in 100 m with a run of 9.82 s |
| 1 | Thompson’s personal best was 6.51 seconds in the 60 m at Fayetteville, United States |
| 2 | Richard Thompson had a personal best of 9.82 seconds on 30 May 2008 in Fayetteville |
| 3 | Thompson made a personal best of 6.51 seconds in the 60 m at the Fayetteville, United States |
case 27-69
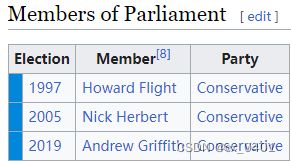
| link | http://en.wikipedia.org/wiki/Arundel_and_South_Downs_(UK_Parliament_constituency) |
|---|---|
| gold | Arundel and South Downs is a constituency of the UK Parliament represented by Nick Herbert of the Conservative Party since 2005 |
| 1 | Arundel and South Downs is a UK Parliament constituency represented since 2005 by Nick Herbert of the Conservative Party |
| 2 | The Arundel and South Downs constituency was represented by Nick Herbert in the 2005 election |
| 3 | Arundel and South Downs is a constituency of the UK Parliament represented since 2005 by Nick Herbert, a Conservative |
case 28-74

| link | http://en.wikipedia.org/wiki/NunSexMonkRock |
|---|---|
| gold | NunSexMonkRock peaked at number 184 on the United States Billboard 200 |
| 1 | NunSexMonkRock peaked at number 27 in the German Albums chart, number 38 in New Zealand Albums chart and number 18 in Norwegian Albums chart |
| 2 | NunSexMonkRock peaked at number 184 on the Billboard 200 |
| 3 | NunSexMonkRock peaked at number 184 on the Billboard 200 |
case 29-75
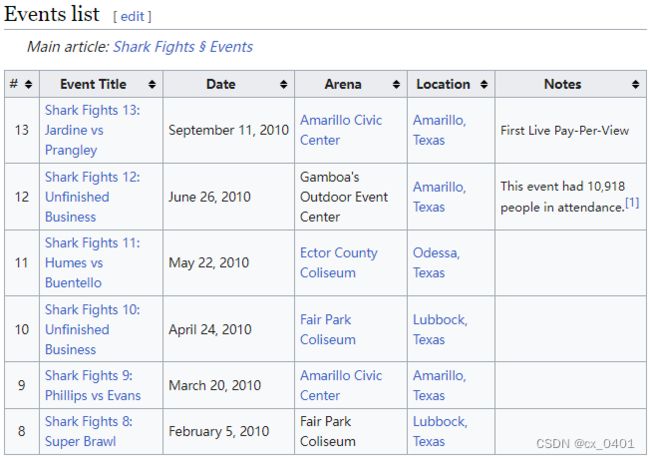
| link | http://en.wikipedia.org/wiki/2010_in_Shark_Fights |
|---|---|
| gold | The Shark Fights 11: Humes vs Buentello was an event held on May 22, 2010 at the Ector County Coliseum in Odessa, Texas |
| 1 | Shark Fights 12: Unfinished Business was an event held on June 26, 2010 at the Gamboa’s Outdoor Event Center in Amarillo, Texas |
| 2 | Shark Fights 12: Unfinished Business was an event held on June 26, 2010 at the Gamboa’s Outdoor Event Center in Amarillo, Texas |
| 3 | Shark Fights 12: Unfinished Business was an event held on June 26, 2010 at the Gamboa’s Outdoor Event Center in Amarillo, Texas |
case 30-76

| link | http://en.wikipedia.org/wiki/Anderson_and_Wise_(song) |
|---|---|
| gold | Chase’s version of Anderson and Wise was released on HMV HR 479 in 1972 |
| 1 | Nash Chase’s “Anderson And Wise” was released on HMV HR 479 in 1972 |
| 2 | In 1972, Anderson and Wise’s “Anderson And Wise” / “Yo Yo Mac” was released by Ode-50 |
| 3 | The 1972 Anderson and Wise song, “Yo Yo Mac”, was released on Ode-50 |
case 31-82
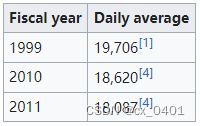
| link | http://en.wikipedia.org/wiki/Nishi-eifuku_Station |
|---|---|
| gold | In the fiscal year of 2011, Nishi-eifuku Station was used by an average of 18,087 passengers daily |
| 1 | In fiscal 2011, Nishi-eifuku Station was used by an average of 18,087 passengers daily |
| 2 | In fiscal 2011, Nishi-eifuku station was used by an average of 18,087 passengers daily |
| 3 | In fiscal 2011, the Nishi-eifuku Station was used by an average of 18,087 passengers daily |
case 32-83

| link | http://en.wikipedia.org/wiki/Bert_Richardson_(judge) |
|---|---|
| gold | In 1999, Richardson created state judgeship numbered 379 |
| 1 | Bert Richardson was the first judge in the United States |
| 2 | Bert Richardson (judge) was the judge of New judgeship |
| 3 | Bert Richardson was the first judge to serve as a consul for the 129th District of New York |
case 33-88
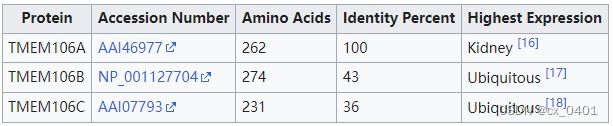
| link | http://en.wikipedia.org/wiki/TMEM106A |
|---|---|
| gold | TMEM106A has 262 amino acids |
| 1 | TMEM106B is a protein with 274 amino acids |
| 2 | TMEM106A is a protein with 262 amino acids, NP_001127704 |
| 3 | TMEM106B is a tetrasodium iodide with 274 amino acids |
case 34-89

| link | http://en.wikipedia.org/wiki/Leopard_2E |
|---|---|
| gold | The Leopard 2’s engine output options were M60A3’s 750 horsepower (559.27 kW) and the AMX-30EM2’s 850 horsepower (633.84 kW) engines |
| 1 | Leopard 2E has a capacity of 1,500 hp (1,479 hp, 1,103 kW) |
| 2 | The Leopard 2E weighs 63 t (69.45 tons) and is 750 hp (633.84 kW) |
| 3 | The Leopard 2E was rated 63 t (69.45 tons) and 55.6 t (63.68 tons) |
case 35-90

| link | http://en.wikipedia.org/wiki/List_of_heads_of_state_of_Yugoslavia |
|---|---|
| gold | Alexander I, was King of Yugoslavia from 1921 to 1934 |
| 1 | Paul was the Prince Regent for Peter II of Yugoslavia |
| 2 | Peter I was a heads of state of Yugoslavia from 1921 to 1921 |
| 3 | Peter I (29 June 1844 – 16 August 1921) was the head of state of Yugoslavia from 1921 until his death in 1921 |
case 36-95
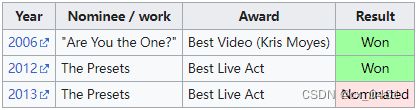
| link | http://en.wikipedia.org/wiki/The_Presets |
|---|---|
| gold | In 2012, The Presets won Best Live Act in the mix Awards |
| 1 | The Presets won Best Video at the Mix Awards for 2006’s “Are You the One?” and Best Video at the Mix Awards for 2012’s “The Presets” |
| 2 | “Are You the One?” was nominated for the Best Video Award in 2012 for The Presets |
| 3 | The Presets was nominated for the “Best Live Act” at the 2012 In the Mix Awards, and won the “Are You the One?” Award in 2006 |
case 37-96
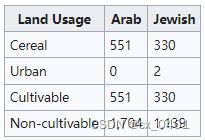
| link | http://en.wikipedia.org/wiki/Harrawi |
|---|---|
| gold | 551 dunums of land was devoted to the farming of cereals |
| 1 | Arab population of Harrawi is 1,704 and Jewish population is 1,139 |
| 2 | In the Harrawi-British Mandate era, there were 330 Arabs |
| 3 | In Harrawi, there was a population of 1,704 (Arab) people in the British Mandate era |
case 38-106

| link | http://en.wikipedia.org/wiki/1931%E2%80%9332_FA_Cup |
|---|---|
| gold | Newcastle United beat Arsenal 2–1 at Wembley |
| 1 | Newcastle United won the 1931–32 FA Cup beating Arsenal 2–1 |
| 2 | Newcastle United defeated Arsenal 2–1 in the 1931–32 FA Cup |
| 3 | Newcastle United won the 1931–32 FA Cup beating Arsenal by 2–1 |
case 39-109

| link | http://en.wikipedia.org/wiki/Idaho_Vandals_football |
|---|---|
| gold | Vandals defeated Bowling Green by a score of 43–42 in the 2009 Humanitarian Bowl |
| 1 | In 1998, Idaho Vandals defeated Southern Miss 42–35 in the Humanitarian Bowl |
| 2 | In 2016, Paul Petrino played the Famous Idaho Potato Bowl with Colorado State |
| 3 | The Idaho Vandals won the Humanitarian Bowl in 2009, and beat Bowling Green in the Humanitarian Bowl |
case 40-112
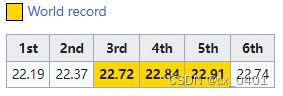
| link | http://en.wikipedia.org/wiki/Alessandro_Andrei |
|---|---|
| gold | In 1987 Alessandro Andrei broke the world record three times in the same competition with successive throws of 22.72, 22.84 & 22.91 m and finishing the sequence with a throw of 22.74 m |
| 1 | Alessandro Andrei holds the world record with a time of 22.19 seconds |
| 2 | Andrei finished the world record with 22.19 seconds and 22.74 seconds |
| 3 | Alessandro Andrei has set the record of 22.19 (22.37), 22.72 (22.72), 22.84 (22.84), 22.91 (22.91), 22.74 (22.74), and 22.74 (22.74) |