在 FPGA 上如何实现双线性插值的计算?
作者 | 殷庆瑜 责编 | 胡巍巍
目录
一、概述
二、What?什么是双线性插值?
二、Why?为什么需要双线性插值?
三、How?怎么实现双线性插值?
关键点1 像素点选择
关键点2 权重计算
升级1 通过查表减少计算量
升级2 通过数据锁存减少取数周期
升级3 通过换数信号兼容更多分辨率
一、概述
本文主要讨论了如何在FPGA上实现双线性插值的计算。Interp和Resize是Yolo_v2,Yolo_v3和Faster R-CNN等目标检测网络的关键层。主要的作用是使得图片的放大和缩小过程变得更为平滑。
二、What?什么是双线性插值?
双线性插值顾名思义是线性插值Pro,为了说明白什么是双线性插值,首先得先从线性插值说起。那么什么又是线性呢?用数学课本上的话来说,两个变量之间存在一次方函数关系,就称它们之间存在线性关系。可能这么说有些太抽象,下面举个生活中的例子来形象地说明一下线性插值。
如下图所示,女朋友每周生气次数和男生的直男程度是线性相关的。已知A男生直男程度为1,女朋友每周生气次数为4千次。另外一个B男生,直男程度为5,女朋友每周生气的次数为6千次。那么C男生直男程度为3,那么他女朋友每周的生气程度是可以根据A和B的情况被计算出来的。
由于他的直男程度是A和B的中间值,所以在A和B中间插值的结果为5千。如果C的直男程度向B的方向移动,则他女朋友生气的次数会更多。回到本文想讨论的双线性插值的话,计算出一个点数值需要这个点周围4个点的数值。

将单线性插值升维成双线性插值后,计算一个点的情况如下图所示。首先蓝色的点是水平方向单线性插值算出来的数,接着在垂直方向上2个蓝色的点线性插值出红色的点,经过两次单线性插值之后就完成了双线性插值的整个过程。

二、Why?为什么需要双线性插值?
在计算机图像的过程中,图片放大有很多种不同的方法。速度最快的就是最邻近法(简单图像缩放),它的原理就是直接把源图像距离最近的像素点值填充到放大图像的像素点。
缺点就是会在放大图片中出现很多的马赛克,图像放大非常不平滑。而双线性插值的方法则是每个点都通过前文介绍的线性插值的方法计算出来的,图片的缩放过程会比较平滑。下面的原理示意图对比了2种过程的不同。

从示意图中可以看出,简单图像缩放并没有增加任何图像信息,而双线性插值则根据原有的图片算出了原来并不存在的像素点。下面的实际对比图中也能看出两者的区别,双线性插值会使得图片缩放更加平滑。
三、How?怎么实现双线性插值?
Interp的算法简单来说就是用源图的四个点分别与各自的权重相乘然后再相加得到目标图片的一个值。所以这个算法的关键点有两个:
1. 源图4个像素点的选择;
2. 与4个像素点相乘的权重的计算。
实际上,无论是像素点的选择还是权重的计算都依赖源图片和目标图片长和宽像素点的比例关系。根据源图片和目标图片的比例关系可以先算出一个基础系数(Base_Parameter)。但这并不意味着一个2*2的图片扩大成4*4的图片,比例系数就由2/4直接得到,因为双线性插值的的点是指的每个像素点的中心点的值,如下图所示。
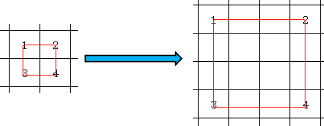
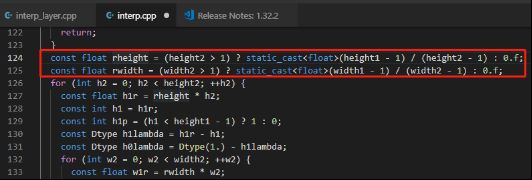
所以实际的比例关系计算应该是中心点距离的总和之间的比例关系,也就是像素点减一之后的比例关系。还是举例说明的话,2*2的图片扩大成4*4的图片应该就是(2-1)/(4-1)这样来得出比例关系。为了证明这个推导的正确性,下面是caffe里面interp层的c++代码,可以从图中看到的是选择像素点的代码,确实是需要进行减一操作的。
关键点1 像素点选择
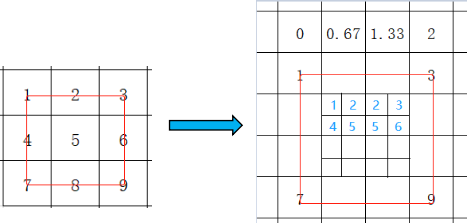
用3*3扩大成4*4的例子来举例说明。根据上面推导出的公式可以得到这个过程中的基础比例系数是(3-1)/(4-1)=0.67。如下图所示,目标图片的第二行第二列的点是由1,2,4,5四个点计算的。因为此时,选择像素点行的参数为0.67*1=0.67没有超过1且选择像素点水平方向和垂直方向的参数为0.67*1=0.67没有超过1。所以,参与计算的源图片像素点。
是最左最上的2*2矩阵。到计算目标图片的第二行第三列数时,水平方向的参数为0.67*2=1.34,这个值超过了1,所以源图片水平2*2的矩阵要向右移动一个像素的位置。而垂直方向的参数还是0.67,故而垂直方向无需移动。参与运算的数就从1、2、4、5变为了2、3、5、6。
关键点2 权重计算
还是用3*3扩大成4*4的例子来举例说明。现在需要计算0Base下(1,1)的数,也就是图中黄色的像素点。由于它的行坐标和列坐标都为1,所以这层的计算参数需要分别将行和列的基础系数乘1得到,也就是行为0.67,列为0.67。具体计算过程为1*(1-0.67)*(1-0.67) + 2*0.67(1-0.67) + 4*(1-0.67)*0.67 +5*0.67*0.67。其中红字的部分就是权重的计算过程。
小结:
1. 根据输入输出分辨率计算出基础系数。
2. 根据需要计算的像素点位置计算出计算参数。
3. 计算参数的整数部分作为index去选择像素点,小数部分作为权重去计算。
Difference?在FPGA上实现Interp有什么不同?
首先分析C++代码中,Interp的计算过程,下图是caffe中Interp的计算过程代码。

基础系数的计算需要用到除法,然后每个像素点的计算参数计算需要用基础系数和像素的index相乘来得到。在FPGA上,乘法是一件非常消耗资源的事,虽然Xilinx和Altera这样的FPGA厂商会在每块FPGA板上设计dsp来专门应对乘法、除法等复杂运算。但dsp的数量是十分有限的,dsp的使用水平很大程度上决定了整个FPGA的计算速度。
一个dsp可以当作一个乘法器使用,而一个除法器则需要多个DSP级联组成。除此以外,除法器消耗的周期也是十分巨大的,这就意味着除了dsp之外,也需要增加很多寄存器来同步数据,这样又会降低很多计算性能,还使得FPGA的布线更加困难。
FPGA之所以能提高神经网络的运算速度,很重要的一个原因就是它是一个灵活可变的架构,无数不同的设计最终可以实现同样的效果。雪湖之所以能在相对低端的板子上跑运算量巨大的网络,本质的原因也是公司内部有着大量优秀的FPGA开发工程师。
通过对Interp代码的仔细研究,工程师们发现了其中的计算规律。只要输入和输出的分辨率固定,基础系数可以在FPGA外部提前算出,去掉除法器。同时,每个像素点的计算参数也会根据基础系数提前算出,到时候通过导入二进制文件的方式进入FPGA的计算单元,减少DSP的使用。
升级1 通过查表减少计算量

在caffe的Interp代码当中,每次计算出插值的时候都需要进行除法运算,来计算出一个基础系数,然后根据这个插值在目标图片的具体位置计算出计算参数。
经过雪湖的FPGA工程师的大胆假设,精心设计和仔细验证等过程,一套通过查表来减少计算量的方法被应用到了Interp层的计算。具体的实现方法如下:
首先,目标图片的相关参数被输入地址产生器这个函数,当地址产生器这个函数开始运行时,会输出相应的地址去到权重BRAM。
权重BRAM中存着提前输入的的参数,如前文所述,计算参数的整数部分为INDEX用于选数,小数部分为权重用于计算。所以当权重BRAM的数据取出数,这个数据会被截断。
前半部分是INDEX,会被作为数据BRAM的地址用于取出对应的2x2窗口数据。后半部分则是对应的权重部分,会被放到寄存器中同步周期,等待窗口数据被取出。
当窗口数据和权重数据同步到达计算函数的时候,dsp会对数据进行一步乘法处理,然后进行加法和截断的操作(具体计算过程见上文)。最后插值的数据会被总线输出到内存当中。
小结:
1. 由于输入输出的分辨率在每一层网络是固定的,所以部分需要计算量可以在FPGA外部做好,然后存进BRAM。通过查表的方式来减少计算量,实现资源最大化利用。
2. INDEX和对应PARA需存在BRAM的同一个地址,方便通过地址发生器来控制参数的取出和调用,一次解决窗口选择和权重计算两个问题。
升级2 通过数据锁存减少取数周期
如前文介绍,计算一个插值需要有4个源图片像素点。由于BRAM每个周期只能将一个地址位上的数据读出来。这就意味着如果将一个feature map的所有像素点都存在一个BRAM里的话,读出一个2x2窗口数据就需要用4个周期。
这样做相当于DSP会在3/4的时间上处于空置状态。所以在这层实现的时候,采用了一个2行缓存BRAM的方案。如下图所示,一个BRAM存源图片的一行数据。
这样在进数的时候,使用双口BRAM,开启先读后写的功能就可以让数据做一个整行的位移。也就是第二行BRAM的数据推进到第一行的BRAM里面,第二行BRAM再写入新的数据。在取数的时候,从权重BRAM传来的地址就代表了数据的水平方向的位置。

这样的设计在取数时,也变得十分方便。在取数的时候,从权重BRAM传来的地址就代表了数据的水平方向的位置。与此同时,每个BRAM的输出口接一个锁存器,锁存2x2窗口左侧的2个数据。
当窗口滑动的时候,前面的函数传来一个使能信号,让锁存器能够进行换数操作。这里存在一个问题,正常卷积层的的窗口滑动是存在这一个固定步长的,而在双线性插值这种非卷积层,滑动的周期是不固定的。所以在卷积层使用的计数器滑动窗口这种常规手段完全失效,那么下一个小结会讨论滑动的信号如何产生。
小结:
1. 2行BRAM缓存的方案降低了进数和取数的复杂程度。
2. BRAM和出数后接的锁存器使得一个周期取出2x2窗口数据成为可能。
升级3 通过换数信号兼容更多分辨率
在一个FPGA芯片当中,DSP和BRAM都是十分关键的资源。所有入门的FPGA开发工程师在DSP的使用率上,几乎不会有太大的差距,而在BRAM的实用设计上差距就很大了。
原因在于,一个完整的feature map被塞入BRAM是一件非常简单的事。但代价就是这种做法直接对分辨率较大或者通道数较多的feature map宣判了死刑。另外一个坏处就是,一个层占用太多资源的话,对层合并来说也不是个好消息,直接会降低运算速度。

雪湖在这个问题上是采用了切feature map的方式来解决的。在同一个时间段内,只有2行的数据被存进了BRAM,在保证了一行插值计算所需的数据量的基础上,最少占用BRAM存储空间。
在权重BRAM的数据被取出时,INDEX的一个作用就是被用来取数,另外一个作用就是被用来与上一个周期的INDEX作比较。在双线性插值中,会产生2个维度的INDEX。
当包含行信息的INDEX(垂直方向)发生改变时,比较器会发出一个换数信号,一行新的数据会通过总线输入进入BRAM。而当包含列信息的INDEX(水平方向)发生改变时,窗口则向右滑动一个步长。
小结:
1. 行INDEX改变进一行数,列INDEX改变窗口滑动一个步长。
众所周知,Faster R-CNN是一个全球公认的优秀二阶网络,它是拥有最高精度表现的。但是这样的目标检测网络却没有被大规模使用,其主要原因就是它算的慢。
那么为什么会算的慢呢?因为业界目前普遍使用GPU去跑Faster R-CNN,而这个网络实际上对GPU是不友好的。Faster R-CNN当中除了常规的卷积层,它还有大量的Proposal,Interp和ROI-Align等非卷积层。
因为GPU原来就是做图形图像处理,它对所有能展开的东西都是非常友好的。但是Faster R-CNN中这些特殊操作的层,GPU就无能为力了。然而这些层是真正赋予Faster R-CNN高精度特性的层。
在雪湖工程师不断地讨论和验证之后,终于摸索出一条能在fpga上将卷积层和非卷积层并行计算的技术道路。
这种办法的核心原理就是FPGA内部带宽巨大和资源调配灵活。而在fpga上实现这种非卷积层的加速运算则是解决Faster R-CNN计算速度慢的核心。
雪湖相信当我们的工程师将越来越多类似于Interp层这样GPU支持不友好的算子在FPGA上实现之后,一些原本很优秀却又无法在GPU上发挥最大价值的网络会在FPGA上迎来自己的春天。
作者简介:殷庆瑜,雪湖科技FPGA应用研发开发工程师,毕业于英国伯明翰大学并取得工学硕士学位。毕业后进入雪湖极客学院学习并取得优异成绩,现负责神经网络加速器产品开发。
【End】