Bidding模型训练新范式:阿里妈妈生成式出价模型(AIGB)详解
导读:今天以ChatGPT为代表的生成式大模型让科技行业重新兴奋起来,也为广告营销注入了新的想象力。生成式大模型几乎一定会带来用户与互联网产品交互模式的改变,进而颠覆广告营销模式。广告技术人,你们准备好了吗?阿里妈妈技术已提前在该方向布局,并推出了新的广告营销智能技术体系,今天将揭露出其神秘面纱的一角,窥探背后的思考和实践。
▐ 摘要
出价产品智能化成为行业趋势,极简产品背后则是强大的自动出价的支撑,其技术不断演进走过了3个大的阶段:PID控制、RL-based Bidding、SORL(Sustainable Online RL),那么下一步代际性技术升级是什么?今天以ChatGPT为代表的生成式大模型以汹涌澎湃之势到来,几乎一定会颠覆广告营销模式,一方面,新的用户交互模式会孕育新的商业机会,给自动出价的产品带来巨大改变;另一方面,新的技术理念和技术范式也会给自动出价算法带来革命性的升级。阿里妈妈技术团队提前布局,以智能营销决策大模型AIGA(AI Generated Action)为核心重塑了广告智能营销的技术体系,并衍生出以AIGB(AI Generated Bidding)为代表的各种领域技能模型。AIGB是一种基于生成式模型构造的出价模型优化方案,与以往解决序列决策问题的强化学习视角不同,其将策略建模为条件生成模型,从而消除了以往强化学习视角下的复杂性问题。具体实现上,将出价、优化目标和约束等具备相关性的指标视为一个联合概率分布,并以优化目标和约束项为条件,生成相应出价策略的条件分布。训练时将历史次优投放轨迹数据作为训练样本,以最大似然估计的方式拟合轨迹数据中的分布特征;推断时基于约束和优化目标,以符合分布规律的方式输出出价策略。本文提出的方案可避免传统RL方案中的分布偏移和策略退化问题,又具备满足不同出价类型和不同约束的灵活性。通过AIGB的技术研究和线上实践,我们愈发地感受到新的技术浪潮正在朝我们奔来,AIGB只是这一切的开始...
一、背景
1.1 出价产品智能化成为行业趋势
广告平台吸引广告主持续投放的核心在于给广告主带来更大的投放价值,出价产品的智能化已成为行业趋势并加以重点建设的能力(如图1)。以阿里妈妈为代表的互联网广告平台不断地探索流量的多元化价值,并设计更能贴近营销本质的自动出价产品,广告主只需要简单的设置就能清晰的表达出营销诉求。极简产品背后则是强大的出价策略支撑,广告主出价策略从海量数据中挖掘更好的营销模式,提升广告主对特定价值的优化能力,赋能广告主投放。
 图1:出价产品的演进趋势,智能化逐步成为互联网广告产品的标配
图1:出价产品的演进趋势,智能化逐步成为互联网广告产品的标配
1.2 自动出价技术的不断演进
阿里妈妈技术团队多年来致力于极致的优化自动出价策略,帮助广告主获得最好的投放效果,其自动出价策略的技术演进可以大体分为三个大的阶段,具体如下图。
 图2:典型的自动出价技术演进路线,从预算消耗控制->RL-based Bidding->SORL,下一步代际性升级是什么?
图2:典型的自动出价技术演进路线,从预算消耗控制->RL-based Bidding->SORL,下一步代际性升级是什么?
第一阶段:预算消耗控制,通过控制预算的消耗速度尽可能平滑来优化效果,一般通过经典的控制算法,如PID等。在假设竞价环境中流量价值分布均匀的情况下,这种方法能够达到比较好的效果。
第二阶段:RL-based Bidding,现实环境中的竞价环境是非常复杂且动态变化的,只控制预算无法满足更多样的出价计划的进一步优化。AlphaGo的惊艳表现,展现了强化学习的力量,而自动出价是一个非常典型的序列决策问题,在预算周期内,前面花的好不好会影响到后面的出价决策,而这正是强化学习的强项,因此第二阶段我们用了基于强化学习的Bidding。Simulation basedbidding 的一些工作[1]奠定了我们在广告主报价领域的领先地位。
第三阶段:SORL,它的特点是针对强化学习中离线仿真环境与在线环境不一致。我们直接在在线环境中进行可交互的学习,这是工程设计和算法设计联合的例子。SORL[2]上线之后,很大程度上解决了强化学习强依赖于仿真平台的问题。
今天以ChatGPT为代表的生成式大模型让科技行业重新兴奋起来,也为广告营销注入了新的想象力。生成式大模型几乎一定会带来用户与互联网产品交互模式的改变,例如,多模态交互式对话方式会取代搜索引擎的地位,以广告位拍卖为基础的互联网广告的逻辑也会发生改变。一方面,新的用户交互模式会孕育新的商业机会,给自动出价的产品带来颠覆的改变;另一方面,新的技术理念和技术范式也会给自动出价算法带来革命性的升级。
如今,革命性升级已经到来!
二、相关工作
2.1 自动出价建模
考虑到广告目标、预算和个KPI约束,计划的诉求可以通过(LP1)表示为统一的带约束竞价问题。
如果已经知道流量集合的全部信息,包括能够触达的每条流量i的流量价值 和成本 等,那么可以通过解决线性规划问题(LP1)来获得最优解 。然而,在实际应用中,我们需要在流量集合未知的情况下进行实时竞价。由于在线广告池的动态变化以及每天访问用户的随机性,很难通过准确的预测来构建流量集合。因此,常规的线性规划解决方法并不完全适用。所以在实际应用中,通过对上述出价公式的一些变换,构造一个最优出价公式,将原问题转化为求解最优参数的问题,从而大大降低了在线情况下求解此问题的难度。
最优的出价公式为:
其中,是常数项,是参数,其范围为:。如果约束j是CR,则 ;如果约束 j 是NCR,则 。证明过程详见论文[1]。
最优出价公式共包含 m+1 个核心参数 , ∈ [0, ..., ],公式中其余项为在线流量竞价时可获得的流量信息。由于最优出价公式存在,对于具有预算约束和 M 个 KPI约束、且希望最大化赢得流量的总价值的问题,最优解可以通过找到 M+1 个最优参数并根据公式进行出价,而不是分别为每个流量寻找最优出价。理想情况下,通过求解最优参数 ,即能直接获得每个广告计划的最优出价。我们可以通过 PID 或者 RL 来逼近真实环境中的最优参数。
2.2 生成式模型
生成式模型近年来得到了迅速的发展,在图像生成、文本生成、计算机视觉等领域取得了重大突破,并催生出了近期大热的ChatGPT等。生成式模型主要从数据分布的角度去理解数据,并通过拟合训练数据集中的样本分布来进行特征提取,最终生成符合数据集分布的新样本。目前常用的生成式模型包括Transformer[3]、Diffusion Model[4]等。Transformer主要基于自注意力机制,能够对样本中跨时序和分层信息进行提取和关联,擅长处理长序列和高维特征数据,如图像、文本和对话等。而Diffusion Model则将数据生成看作一个分阶段去噪的过程,将生成任务分解为多个步骤,逐步加入越来越多的信息,从而生成目标分布中的样本。这一过程与人类进行绘画过程较为相似,由此可见,Diffusion Model擅长处理图像生成等任务。
依靠生成式模型强大的信息生成能力,我们也可以引入生成式模型将序列决策问题建模为一个序列动作生成问题。模型通过拟合历史轨迹数据中的行为模式,达到策略输出的目标。Decision Transformer(DT)[5] 和 Decision Diffuser(DD)[6] 分别将Transformer以及Diffusion Model应用于序列决策,在通用数据集中,相比主流的RL方法[7,8]取得了较好的效果提升。这一结果为我们的Bidding建模提供了一个可用的迭代方案。
三、AIGB(AI Generated Bidding)
3.1 智能营销技术体系的重塑
早在生成式模型如ChatGPT惊艳之前,阿里妈妈技术团队就已经开始尝试用生成式和大模型重塑智能营销的技术体系,并持续投入相应的团队和资源,设计了一套全新的智能营销技术体系。
 图3:以智能营销决策大模型为核心的智能营销技术体系
图3:以智能营销决策大模型为核心的智能营销技术体系
其中,在营销层,革新了以往功能繁多操作麻烦的BP,给广告主带来一种新的对话式交互体验,广告主只需要通过简单的自然语言的描述,即可实现全部的营销流程,大大简化了广告主的操作和学习成本。而这些都依赖于强大的智能营销决策大模型AIGA(AI Generated Action), 以及衍生出来的各种领域技能模型,典型的领域技能模型AIGB(AI Generated Bidding)是专门服务于自动出价算法的模型。这些模型的训练基于阿里集团自研的高性能硬件以及相应的框架。
3.2 AIGB建模方案
AIGB是一种基于生成式模型构造的出价模型优化方案。与以往解决序列决策问题的强化学习视角不同,AIGB将策略建模为条件生成模型,从而消除了以往强化学习视角下的复杂性问题。我们进一步考虑额外的条件变量,展示了将出价策略建模为条件生成模型的优势。在训练过程中,对约束进行条件化,使得推断时的行为可以同时满足多个约束组合。我们的研究结果表明,使用条件生成式模型来解决出价问题中的序列决策问题是一个好的选择。
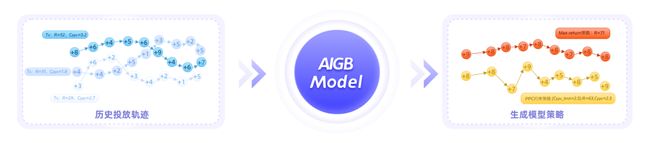 图4:图左历史投放轨迹中,颜色深浅代表计划return的不同。右图为AIGB模型根据不同需求生成的新策略。整个模型看作一个分布处理pipeline,输入历史非最优但存在有效信息的广告投放轨迹,输出符合优化目标的新策略。
图4:图左历史投放轨迹中,颜色深浅代表计划return的不同。右图为AIGB模型根据不同需求生成的新策略。整个模型看作一个分布处理pipeline,输入历史非最优但存在有效信息的广告投放轨迹,输出符合优化目标的新策略。
从生成式模型的角度来看,我们可以将出价、优化目标和约束等具备相关性的指标视为一个联合概率分布,从而将出价问题转化为条件分布生成问题。这意味着我们可以以优化目标和约束项为条件,生成相应出价策略的条件分布。图4直观地展示了生成式出价(AIGB)模型的流程:在训练阶段,模型将历史次优投放轨迹数据作为训练样本,以最大似然估计的方式拟合轨迹数据中的分布特征。这使得模型能够自动学习出价策略、状态间转移概率、优化目标和约束项之间的相关性。在线上推断阶段,生成式模型可以基于约束和优化目标,以符合分布规律的方式输出出价策略。总的来说,生成式模型的优势在于:
训练阶段,条件生成式模型通过最大似然估计进行训练,可以最大程度地避免分布偏移和策略退化问题。
推断阶段,条件生成式模型可以根据不同的出价类型生成不同的出价轨迹,以实现不同约束项的满足。
3.2.1 模型结构:
 图5:AIGB 结构
图5:AIGB 结构
如图5,给定当前轨迹信息 和策略生成条件 ,AIGB模型可以逐个生成未来的出价策略:
。
其中出价策略 是由未来的最优状态和与之对应的最优出价组成的序列。生成条件包括了优化目标(购买量最大化、点击量最大化)以及约束项(PPC、ROI、投放平滑性)等。被用来估计条件概率分布。模型基于当前的投放状态信息以及策略生成条件输出未来的投放策略,相比于以往的RL策略仅仅黑盒输出单步action,AIGB策略可以被理解为在规划的基础上进行决策,更擅长处理长序列问题。这一优点有利于我们在实践中进一步减小出价间隔,提升策略的快速反馈能力。与此同时,基于规划的出价策略也具备更好的可解释性,能够帮助我们更好地进行离线策略评估,方便专家经验与模型深度融合。
3.2.2 训练方法:
 图6:AIGB模型训练过程
图6:AIGB模型训练过程
AIGB模型通过最大似然估计历史数据集D中轨迹 和策略生成条件 所对应的轨迹信息进行训练,从而最大限度拟合历史轨迹的分布信息:
。
拟合历史分布的过程可以通过引入 Diffusion Model 或 Transformer 等生成式模型来完成。以我们真实使用的扩散模型为例,我们将序列决策问题看作一个条件扩散过程,包括正向过程 和反向过程 。整个训练过程如图6所示,k表示正向过程的迭代步,在正向过程,高斯噪声 转化为历史投放轨迹分布 ;反向过程则表示从 转变为 的过程。每一次 到 的转换均通过加入含有一定信息的高斯扰动实现。除此之外,在反向过程中,我们还希望能够表达 与 的相关性,因此可以引入DD模型中使用的 Classifier-free 方法,利用
提取数据集中与 相关度最高的部分。其中 为噪声模型,通过神经网络生成每一个时间步所增加的噪声。k步所对应的高斯扰动可以表示为:
其中 表示不同的目标或者约束, 用来调节 的权重。Classifier-free 方法可以较为优雅地处理多种优化目标和约束条件,避免以往RL训练过程中由于约束信号稀疏而效果下降的问题。我们将这一基于扩散模型进行出价建模的方法称为 Decision Diffuser based Generative Bidding(DDGB)。DDPG的Planning具体过程如下:

四、总结及未来展望
AIGB方案可以带来诸多优势,包括解决困扰 RL Bidding 在离线不一致问题,更好地训练多约束出价模型,更好的可解释性以及更为顺畅的与专家经验的结合能力等,这些优点可以帮助我们进一步提升模型迭代效率和效果上限。可以看出,生成式模型驱动的AIGB已经在以完全不同的方式重构自动出价的技术体系。但是,这仅仅是一个开始。阿里妈妈沉淀了亿级广告投放轨迹数据,是业界为数不多具备超大规模决策类数据资源储备的平台。这些海量数据资源可以成为营销决策大模型训练的有力保证,从而推动AIGA技术的发展。与此同时,用户和互联网产品的交互方式也将发生深刻的变化。重塑广告营销模式的机会之门已经在变化之中逐步显现,我们需要做的就是通过持续不断地探索和尝试来迎接变化。期待后续有机会与大家分享和交流我们的进展与实践。
▐ 参考文献
[1] He Y, Chen X, Wu D, et al. A unified solution to constrained bidding in online display advertising[C]//Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2021: 2993-3001.
[2] Mou Z, Huo Y, Bai R, et al. Sustainable Online Reinforcement Learning for Auto-bidding[J]. arXiv preprint arXiv:2210.07006, 2022.
[3] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[4] Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models[J]. Advances in Neural Information Processing Systems, 2020, 33: 6840-6851.
[5] Chen L, Lu K, Rajeswaran A, et al. Decision transformer: Reinforcement learning via sequence modeling[J]. Advances in neural information processing systems, 2021, 34: 15084-15097.
[6] Ajay A, Du Y, Gupta A, et al. Is Conditional Generative Modeling all you need for Decision-Making?[J]. arXiv preprint arXiv:2211.15657, 2022.
[7] Kumar A, Zhou A, Tucker G, et al. Conservative q-learning for offline reinforcement learning[J]. Advances in Neural Information Processing Systems, 2020, 33: 1179-1191.
[8] Kostrikov I, Nair A, Levine S. Offline reinforcement learning with implicit q-learning[J]. arXiv preprint arXiv:2110.06169, 2021.
END

也许你还想看
丨万字长文,漫谈广告技术中的拍卖机制设计(经典篇)
丨阿里妈妈展示广告智能拍卖机制的演进之路
丨面向在线广告全链路拍卖机制设计新突破 — Two-stage Auction
丨Deep GSP :面向多目标优化的工业界广告智能拍卖机制
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”ღ~
↓欢迎留言参与讨论↓