AWS 设计高可用程序架构——Glue(ETL)部署与开发
依赖:本文需要了解AWS 架构设计基础知识
AWS Glue 是一项完全托管的 ETL(提取、转换和加载)服务,使您能够轻松而经济高效地对数据进行分类、清理和扩充,并在各种数据存储和数据流之间可靠地移动数据。AWS Glue 由一个称为 AWS Glue Data Catalog的中央元数据存储库、一个自动生成 Python 或 Scala 代码的 ETL 引擎以及一个处理依赖项解析、作业监控和重试的灵活计划程序组成。AWS Glue 是无服务器服务,因此无需设置或管理基础设施。
AWS Glue 设计用于处理半结构化数据。它引入了一个称为动态帧 的组件,您可以在 ETL 脚本中使用该组件。动态框架与 Apache Spark DataFrame 类似,后者是用于将数据组织到行和列中的数据抽象,不同之处在于每条记录都是自描述的,因此刚开始并不需要任何架构。借助动态帧,您可以获得架构灵活性和一组专为动态帧设计的高级转换。您可以在动态帧与 Spark DataFrame 之间进行转换,以便利用 AWS Glue 和 Spark 转换来执行所需的分析。
您可以使用 AWS Glue 控制台发现数据,转换数据,并使数据可用于搜索和查询。控制台调用底层服务来协调转换数据所需的工作。您还可以使用 AWS Glue API 操作来与 AWS Glue 服务交互。使用熟悉的开发环境来编辑、调试和测试您的 Python 或 Scala Apache Spark ETL 代码。
一、部署Glue
利用cloudformation部署glue,包括数据库、连接、爬网程序、作业、触发器。
创建IAM角色
附加策略
AmazonS3FullAccess
AmazonSNSFullAccess
AWSGlueServiceRole
AmazonRDSFullAccess
SecretsManagerReadWrite
AWSLambdaRole
信任关系
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "glue.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
创建Glue
AWSTemplateFormatVersion: '2010-09-09'
Parameters:
Environment:
Type: String
Default: DEV
EnvironmentName:
Type: String
Default: d
CustomerName:
Description: The name of the customer
Type: String
#TODO:
Default: your-company-name
ProjectName:
Description: The name of the project
Type: String
#TODO:
Default: your-project-name
CrawlerRoleARN:
Type: String
#TODO:
Default: XXXXXXXXXXXXX
ScriptLocation:
Type: String
#TODO: a empty file
Default: s3://XXXXXX-s3/aws-glue-scripts
SSLCertificateLocation:
Type: String
#TODO:a pem file
Default: s3://XXXXXX-s3/aws-glue-scripts/xxxxxxx.pem
ConnAvailabilityZone:
Description:
The name of the AvailabilityZone,Currently the field must be populated, but it will be
deprecated in the future
Type: String
#TODO:
Default: cn-northwest-xxx
ConnSecurityGroups:
Description: The name of the Secret
Type: List::EC2::SecurityGroup::Id>
#TODO:
Default: sg-xxxxxxxxx, sg-xxxxxxxxx
ConnSubnetId:
Description: The name of the Secret
Type: String
#TODO:
Default: subnet-xxxxxxxxx
OriginSecretid:
Description: The name of the Secret
Type: String
#TODO:
Default: xxxxxxxxxxxxxxxxx
OriginJDBCString:
Type: String
#TODO: jdbc:postgresql://{database ARN}:{port}/{databasename}
Default: jdbc:postgresql://xxxx:xxx/xxxx
OriginJDBCPath:
Type: String
#TODO: Database/Schema/%
Default: xxxx/xxxx/%
Resources:
#Create Origin to contain tables created by the crawler
OriginDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: !Sub ${CustomerName}-${ProjectName}-origin-${EnvironmentName}-gluedatabase
Description: 'AWS Glue container to hold metadata tables for the Origin crawler'
#Create Origin Connection
OriginConnectionPostgreSQL:
Type: AWS::Glue::Connection
Properties:
CatalogId: !Ref AWS::AccountId
ConnectionInput:
Description: 'Connect to Origin PostgreSQL database.'
ConnectionType: 'JDBC'
PhysicalConnectionRequirements:
AvailabilityZone: !Ref ConnAvailabilityZone
SecurityGroupIdList: !Ref ConnSecurityGroups
SubnetId: !Ref ConnSubnetId
ConnectionProperties:
{
'JDBC_CONNECTION_URL': !Ref OriginJDBCString,
# If use ssl
'JDBC_ENFORCE_SSL': true,
'CUSTOM_JDBC_CERT': !Ref SSLCertificateLocation,
'SKIP_CUSTOM_JDBC_CERT_VALIDATION': true,
'USERNAME': !Join [ '', [ '{{resolve:secretsmanager:', !Ref OriginSecretid, ':SecretString:username}}' ] ],
'PASSWORD': !Join [ '', [ '{{resolve:secretsmanager:', !Ref OriginSecretid, ':SecretString:password}}' ] ]
}
Name: !Sub ${CustomerName}-${ProjectName}-origin-${EnvironmentName}-glueconn
#Create Target to contain tables created by the crawler
TargetDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: !Sub ${CustomerName}-${ProjectName}-target-${EnvironmentName}-gluedatabase
Description: 'AWS Glue container to hold metadata tables for the Target crawler'
#Create Target Connection
TargetConnectionPostgreSQL:
Type: AWS::Glue::Connection
Properties:
CatalogId: !Ref AWS::AccountId
ConnectionInput:
Description: 'Connect to Target PostgreSQL database.'
ConnectionType: 'JDBC'
PhysicalConnectionRequirements:
AvailabilityZone: !Ref ConnAvailabilityZone
SecurityGroupIdList: !Ref ConnSecurityGroups
SubnetId: !Ref ConnSubnetId
ConnectionProperties:
{
'JDBC_CONNECTION_URL': !Ref TargetJDBCString,
# If use ssl
'JDBC_ENFORCE_SSL': true,
'CUSTOM_JDBC_CERT': !Ref SSLCertificateLocation,
'SKIP_CUSTOM_JDBC_CERT_VALIDATION': true,
'USERNAME': !Join [ '', [ '{{resolve:secretsmanager:', !Ref TargetSecretid, ':SecretString:username}}' ] ],
'PASSWORD': !Join [ '', [ '{{resolve:secretsmanager:', !Ref TargetSecretid, ':SecretString:password}}' ] ]
}
Name: !Sub ${CustomerName}-${ProjectName}-target-${EnvironmentName}-glueconn
#Create a crawler to crawl the Origin data in PostgreSQL database
OriginCrawler:
Type: AWS::Glue::Crawler
Properties:
Name: !Sub ${CustomerName}-${ProjectName}-origin-${EnvironmentName}-gluecrawler
Role: !Sub arn:aws-cn:iam::${AWS::AccountId}:role/${CrawlerRoleARN}
Description: AWS Glue crawler to crawl Origin data
DatabaseName: !Ref OriginDatabase
Targets:
JdbcTargets:
- ConnectionName: !Ref OriginConnectionPostgreSQL
Path: !Ref OriginJDBCPath
TablePrefix: !Sub ${ProjectName}_${EnvironmentName}_
SchemaChangePolicy:
UpdateBehavior: 'UPDATE_IN_DATABASE'
DeleteBehavior: 'LOG'
Tags:
ApplName: your-app-name
#Create a crawler to crawl the Target data in PostgreSQL database
TargetCrawler:
Type: AWS::Glue::Crawler
Properties:
Name: !Sub ${CustomerName}-${ProjectName}-target-${EnvironmentName}-gluecrawler
Role: !Sub arn:aws-cn:iam::${AWS::AccountId}:role/${CrawlerRoleARN}
Description: AWS Glue crawler to crawl Target data
DatabaseName: !Ref TargetDatabase
Targets:
JdbcTargets:
- ConnectionName: !Ref TargetConnectionPostgreSQL
Path: !Ref TargetJDBCPath
TablePrefix: !Sub ${ProjectName}_${EnvironmentName}_
SchemaChangePolicy:
UpdateBehavior: 'UPDATE_IN_DATABASE'
DeleteBehavior: 'LOG'
Tags:
ApplName: your-app-name
#Job sync from Origin to Target
JobDataSync:
Type: AWS::Glue::Job
Properties:
Name: !Sub ${CustomerName}-${ProjectName}-data-sync-${EnvironmentName}-gluejob
Role: !Ref CrawlerRoleARN
DefaultArguments: {'--job-language': 'python','--enable-continuous-cloudwatch-log': 'true','--enable-continuous-log-filter': 'true'}
# If script written in Scala, then set DefaultArguments={'--job-language'; 'scala', '--class': 'your scala class'}
Connections:
Connections:
- !Ref OriginConnectionPostgreSQL
- !Ref TargetConnectionPostgreSQL
Description: AWS Glue job for Data sync from Origin to Target
GlueVersion: 2.0
Command:
Name: glueetl
PythonVersion: 3
ScriptLocation:
!Sub ${ScriptLocation}/${CustomerName}-${ProjectName}-data-sync-gluejob.py
Timeout: 60
WorkerType: Standard
NumberOfWorkers: 2
ExecutionProperty:
MaxConcurrentRuns: 1
Tags:
ApplName: your-app-name
#Trigger
TriggerDataSync:
Type: AWS::Glue::Trigger
Properties:
Name: !Sub ${CustomerName}-${ProjectName}-data-sync-${EnvironmentName}-gluetrigger
Description: AWS Glue trigger for Data sync from Origin to Target
Type: SCHEDULED
Actions:
- JobName: !Ref JobDataSync
Schedule: cron(0 12 * * ? *)
StartOnCreation: true
Tags:
ApplName: your-app-name
二、Glue自动化部署(CD)
name: build-and-deploy
# Controls when the action will run. Triggers the workflow on push
# but only for the master branch.
on:
push:
branches: [ master ]
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains two jobs called "build" and "deploy"
build:
# The type of runner that the job will run on
runs-on: ubuntu-latest
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
# Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it
- uses: actions/checkout@v2
# Set up Python
- name: Set up Python 3.8
uses: actions/setup-python@v2
with:
python-version: '3.8'
# Install nbconvert to convert notebook file to python script
- name: Install nbconvert
run: |
python -m pip install --upgrade pip
pip install nbconvert
# Convert notebook file to python
- name: Convert notebook
run: jupyter nbconvert --to python traffic.ipynb
# Persist python script for use between jobs
- name: Upload python script
uses: actions/upload-artifact@v2
with:
name: traffic.py
path: traffic.py
# Upload python script to S3 and update Glue job
deploy:
needs: build
runs-on: ubuntu-latest
steps:
- name: Download python script from build
uses: actions/download-artifact@v2
with:
name: traffic.py
# Install the AWS CLI
- name: Install AWS CLI
run: |
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install
# Set up credentials used by AWS CLI
- name: Set up AWS credentials
shell: bash
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
run: |
mkdir -p ~/.aws
touch ~/.aws/credentials
echo "[default]
aws_access_key_id = $AWS_ACCESS_KEY_ID
aws_secret_access_key = $AWS_SECRET_ACCESS_KEY" > ~/.aws/credentials
# Copy the file to the S3 bucket
- name: Upload to S3
run: aws s3 cp traffic.py s3://${{secrets.S3_BUCKET}}/traffic_${GITHUB_SHA}.py --region us-east-1
# Update the Glue job to use the new script
- name: Update Glue job
run: |
aws glue update-job --job-name "Traffic ETL" --job-update \
"Role=AWSGlueServiceRole-TrafficCrawler,Command={Name=glueetl,ScriptLocation=s3://${{secrets.S3_BUCKET}}/traffic_${GITHUB_SHA}.py},Connections={Connections=redshift}" \
--region us-east-1
# Remove stored credentials file
- name: Cleanup
run: rm -rf ~/.aws
三、低代码Glue开发(推荐)
AWS Glue Studio 是一個新的圖形介面,讓您可在 AWS Glue 中輕鬆建立、執行和監控擷取、轉換與載入 (ETL) 任務。您可以用視覺化方式撰寫資料轉換工作流程,並在 AWS Glue 的 Apache Spark 型無伺服器 ETL 引擎上順暢地執行它們。您可以在任務的每個步驟中檢查結構描述和資料結果。
Amazon Glue Studio
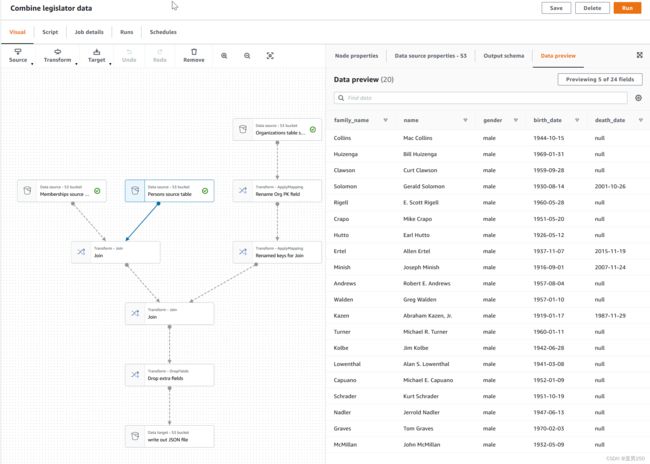
四、Python开发
基础信息python:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
4.1 引入数据源
PostgreSQLtable_node1 = glueContext.create_dynamic_frame.from_catalog(
database="[您创建的Glue连接源数据库名称]",
table_name="[通过爬网程序生成的表名]",
additional_options = {"jobBookmarkKeys":["[tablename表的书签字段,不能为空]"],"jobBookmarkKeysSortOrder":"[asc/desc选一个]"},
transformation_ctx="PostgreSQLtable_node1",
)
transformation_ctx是书签的名字,书签就是数据处理到什么位置的标记,就像看书一样;这个在增量同步中非常有用。
如果要让书签生效,必须满足:
1)glue的Job中"高级设置"->“启用书签”->“启用”;
2)additional_options 项启用才能生效。
4.2 引入字段映射
# Script generated for node ApplyMapping
ApplyMapping_node2 = ApplyMapping.apply(
frame=PostgreSQLtable_node1,
mappings=[
("id", "decimal(19,0)", "id", "decimal(19,0)"),
("updatetime", "timestamp", "updatetime", "timestamp"),
("value", "decimal(19,0)", "value", "decimal(19,0)"),
],
transformation_ctx="ApplyMapping_node2",
)
字段映射中的类型需要不断的尝试,比如直接定义decimal在超过8个字符时,数据导出会有问题,这需要一定的经验和试验。
4.3 增量插入数据
# Script generated for node PostgreSQL table
PostgreSQLtable_node3 = glueContext.write_dynamic_frame.from_catalog(
frame=ApplyMapping_node2,
database="[您创建的Glue目标数据库连接名称]",
table_name="[通过爬网程序生成的表名]",
transformation_ctx="PostgreSQLtable_node3",
)
transformation_ctx是书签的名字,书签就是数据处理到什么位置的标记,就像看书一样;这个在增量同步中非常有用。
4.4 全量插入数据(带清空表)
df = ApplyMapping_node2.toDF()
df.write.format("jdbc").mode('overwrite') \
.option("url", "jdbc:postgresql://[host主机]:5432/[数据库名称]") \
.option("user", "[账号]") \
.option("password", "[密码]") \
.option("dbtable", "[dbo.表名]") \
.option("truncate", "true") \
.save()
如果想在插入数据前,清空表在执行写入操作,请按以上动作进行。
4.5 使用配置参数并执行自定义SQL
import boto3
import psycopg2
data_frame = ApplyMapping_node2.toDF()
glue = boto3.client('glue')
connection = glue.get_connection(Name="[您创建的Glue目标数据库连接名称]")
pg_url = connection['Connection']['ConnectionProperties']['JDBC_CONNECTION_URL']
pg_url = pg_url.split('/')[2].split(':')[0]
pg_user = connection['Connection']['ConnectionProperties']['USERNAME']
pg_password = connection['Connection']['ConnectionProperties']['PASSWORD']
magento = data_frame.collect()
#以下代码中使用配置参数
db = psycopg2.connect(host = pg_url, user = pg_user, password = pg_password, database = "[数据库名]")
cursor = db.cursor()
for r in magento:
insertQry=""" INSERT INTO dbo.gluetest(id, updatetime, value) VALUES(%s, %s, %s) ;"""
cursor.execute(insertQry, (r.id, r.updatetime, r.value))
#可以考虑分页提交
db.commit()
cursor.close()
使用该方式需要引入psycopg2包(相当于docker在运行之前预安装的包)
glue的Job中"安全配置、脚本库和作业参数(可选)"->“作业参数”;
| Glue版本 | 键 | 值 |
|---|---|---|
| 2.0 | –additional-python-modules | psycopg2-binary==2.8.6 |
| 3.0 | –additional-python-modules | psycopg2-binary==2.9.0 |
4.6 Upsert (Insert & update)
增量更新数据,使用updatetime作为书签(非空),新数据插入、旧数据更新。
from py4j.java_gateway import java_import
sc = SparkContext()
java_import(sc._gateway.jvm,"java.sql.Connection")
java_import(sc._gateway.jvm,"java.sql.DatabaseMetaData")
java_import(sc._gateway.jvm,"java.sql.DriverManager")
java_import(sc._gateway.jvm,"java.sql.SQLException")
data_frame = PostgreSQLtable_node1.toDF()
magento = data_frame.collect()
source_jdbc_conf = glueContext.extract_jdbc_conf('[您创建的Glue目标数据库连接名称]')
page = 0
try:
conn = sc._gateway.jvm.DriverManager.getConnection(source_jdbc_conf.get('url') + '/[数据库名]',source_jdbc_conf.get('user'),source_jdbc_conf.get('password'))
insertQry="""INSERT INTO dbo.[表名](id, updatetime, value) VALUES(?, ?, ?) ON CONFLICT (id) DO UPDATE
SET updatetime = excluded.updatetime, value = excluded.value
WHERE dbo.gluetest.updatetime is distinct from excluded.updatetime;"""
stmt = conn.prepareStatement(insertQry)
conn.setAutoCommit(False)
for r in magento:
stmt.setBigDecimal(1, r.id)
stmt.setTimestamp(2, r.updatetime)
stmt.setBigDecimal(3, r.value)
stmt.addBatch()
page += 1
if page % 1000 ==0:
stmt.executeBatch()
conn.commit()
page = 0
if page > 0:
stmt.executeBatch()
conn.commit()
finally:
if conn:
conn.close()
job.commit()
要点:
以上是postgreSQL的处理方式,oracle使用Marge,sqlserver使用类似insert into update语法。
使用的spark原生的Jave包,无需导入新包,可作为"psycopg2"的替代方案。
"psycopg2"的缺点是安装包时间1分钟左右,对于时间敏感的操作,推荐用原生包。
五、本地Glue调试(辅助)
开发和测试 AWS Glue 任务脚本
将容器设置为使用 Visual Studio 代码
先决条件:
-
安装 Visual Studio 代码。
-
安装 Python。
-
安装 Visual Studio Code Remote - 容器
-
在 Visual Studio 代码中打开工作区文件夹。
-
选择 Settings。
-
请选择 Workspace(工作区)。
-
请选择 Open Settings (JSON)(打开设置(JSON))。
-
粘贴以下 JSON 并保存它。
{ "python.defaultInterpreterPath": "/usr/bin/python3", "python.analysis.extraPaths": [ "/home/glue_user/aws-glue-libs/PyGlue.zip:/home/glue_user/spark/python/lib/py4j-0.10.9-src.zip:/home/glue_user/spark/python/", ] }
步骤:
- 运行 Docker 容器。
docker run -it -v D:/Projects/AWS/Projects/Glue/.aws:/home/glue_user/.aws -v D:/Projects/AWS/Projects/Glue:/home/glue_user/workspace/ -e AWS_PROFILE=default -e DISABLE_SSL=true --rm -p 4040:4040 -p 18080:18080 --name glue_pyspark amazon/aws-glue-libs:glue_libs_3.0.0_image_01 pyspark
-
启动 Visual Studio 代码。
-
请选择左侧菜单中的 Remote Explorer,然后选择
amazon/aws-glue-libs:glue_libs_3.0.0_image_01。 -
右键单击并选择 Attach to Container(附加到容器)。如果显示对话框,请选择 Got it(明白了)。
-
打开
/home/glue_user/workspace/。 -
在VSCode中先运行以下命令:
export AWS_REGION=cn-northwest-x -
创建 Glue PySpark 脚本,然后选择 Run(运行)。
您将看到脚本成功运行。