Language Conditioned Spatial Relation Reasoning for 3D Object Grounding【NeurIPS 2022】
文章目录
- 动机
- 方法
- 实验
- 参考文献
code: https://cshizhe.github.io/projects/vil3dref.html
author: 巴黎文理研究院
动机
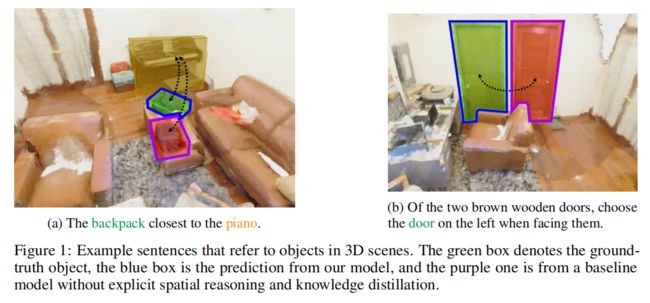
为了在现实世界中执行人类指令,机器人应该理解自然语言,并能够在3D环境中ground上述物体。语言表达通常是描述物体在3D场景中的relative spatial relations来指定物体的。比如上图中的这两个例子,就要消除同一类目标中的歧义目标。
鉴于 spatial language 的重要性,许多方法长时间莫3DVG中的空间关系。早期大家使用GNN来建模关系,但是他们只能捕捉最近邻的关系。近年来,Transformer架构被广泛采用,因为它可以直接建模 pair object之间的关系。然而,使用Transformer来理解用自然语言表达的三维空间关系仍然是一个开放的研究问题。
这篇文章中,作者提出了一个视觉和语言的三维关系推理模型(ViL3DRel)来解决三维物体接地中的上述问题。具体有以下贡献:
- 提出了一个空间自注意力模块来显式编码成对的3维空间关系,以促进语言条件下的空间理解。
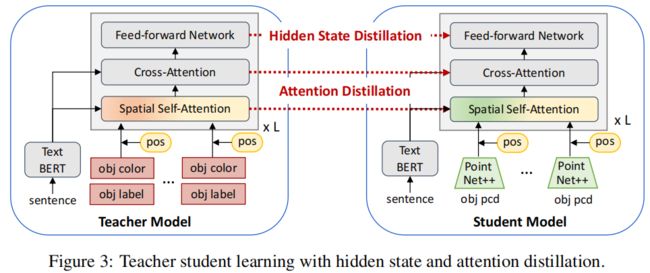
- 我们采用了一种teacher-student 训练策略,促进了跨模式的关系学习。
一阶段方法:[18,23,28]
detection-then-matching(两阶段):[1, 7, 8, 9,13,14,15,16,24]
3DVG-Transformer[13]最像本篇文章,编码了目标间的空间距离,本篇文章编码了目标间的相对距离和相对方向。
方法

给定一段有M个词的文本,用BERT的前三层进行编码,得到一个序列的词特征: s c l s , s 1 , . . . , s M s_{cls}, s_1, ... , s_M scls,s1,...,sM。 s c l s s_{cls} scls表示类别,在计算spatial attention matrix中被用到。 s 1 , . . . , s M s_1, ... , s_M s1,...,sM 表示每一个词的特征,用来在 cross-attention模块中使用。
给定N个proposals后,首先通过PointNet++提取出语义特征 o i 0 o^0_i oi0,经过l层self-attention后,得到了N个 o i l o^l_i oil embedding。将N个proposals各自对应的绝对空间位置特征 l i l_i li以位置编码的方式拼接到这N个 o i l o^l_i oil语义embedding中。每个proposal的绝对空间位置特征定义如下:
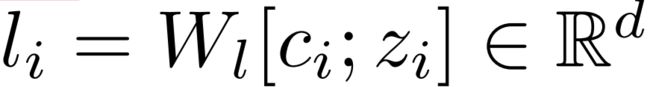
其中,ci是目标中心[cx,cy,cz]、zi是目标尺寸[zx,zy,zz],分别当作是目标点云Pi的平均值和空间范围。然后使用一个线性层将这两个信息映射为第i个目标的三维空间位置特征li。
基于这N个proposals的embedding,使用自注意力机制计算出语义相关性矩阵 Ω o \Omega^o Ωo:
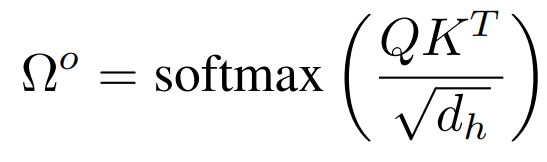
此外,为了建模objects之间的空间关系,作者在每个目标对 ( O i , O j ) (O_{i},O_{j}) (Oi,Oj)之间定义了一个空间特征 f i j i f^i_{ij} fiji,它由五个元素组成:
![]()
其中, d i j d_{ij} dij是目标 O i , O j O_{i},O_{j} Oi,Oj中心 c i , c j c_{i},c_{j} ci,cj之间的欧氏距离, θ h , θ v \theta_h,\theta_v θh,θv是水平角和垂直角,即这两个点出发的平行于坐标轴的线构成的三角形中的两个锐角。这样,目标间的空间关系就形成了一个NxN的矩阵F。但在language condition下,我们更关注的是文本中描述对象的空间关系。因此作者对这个F矩阵的每一行做了一个权重 g i s g^s_i gis:
![]()
其中 s c l s s_{cls} scls表示文本的cls token, o i l o^l_i oil表示第i个对象的embedding。 W S T W^T_S WST是一个可学习的矩阵。因此,我们就得到了一个NxN空间相关性矩阵 Ω s \Omega^s Ωs,它的每一个值 w i j s w^s_{ij} wijs定义如下:
![]()
最后,根据语义相关性矩阵 Ω o \Omega^o Ωo和空间相关性矩阵 Ω s \Omega^s Ωs重新设计了一个新的自注意力矩阵 Ω \Omega Ω,定义如下:

其中,σ(·)是sigmoid函数。作者称这样做的好处是新的自注意力矩阵 Ω \Omega Ω中包含了:三位相对空间位置信息(体现在 Ω s \Omega^s Ωs中)、绝对空间位置和目标外貌信息(这两者都体现在 Ω o \Omega^o Ωo中)。得到新的自注意力矩阵 Ω \Omega Ω后,再把最初的N个 o i l o^l_i oil当作是自注意力机制中的V,与 Ω \Omega Ω进行相乘就得到了输出的值 o ^ i l \hat{o}^l_i o^il。这样整个一个过程,作者称之为spatial self-attention。其实本质上,作者是设计了一个支路计算了一个spatial attention matrix,然后将它与原始的self-attention matrix使用sigsoftmax进行了融合。如果没有这样一个spatial attention matrix的话,整个流程就是正常的self-attention,然后在其之后加上了cross-attention与文本token进行注意力交互。
从一个proposal的点云 P i P_i Pi中估计目标的类别,对跨模态的alignment和spatial relation reasoning是非常重要的。因此作者使用了一个 teacher-student 网络来进行知识蒸馏。具体地,teacher网络的输入是GT目标类别+颜色+位置信息。GT目标类别是文本,用pre-trained Glove word vectors编码,这样做的好处有两个:1)以GT目标类别的语义信息作为输入,可以使得模型更好的学习推理object空间关系的知识;2)文本的GT目标类别与输入的sentence之间有着更少的跨模态间隙,可以更好地学习匹配object语义信息与sentence任务的知识。使用以下两个损失函数进行监督,使得知识从teacher model蒸馏到student model中:
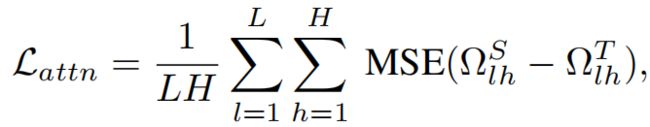
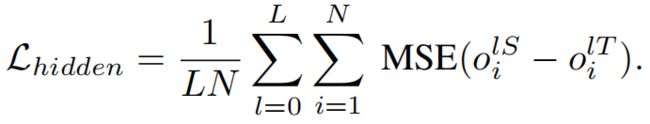
完整的损失函数如下所示,除了蒸馏的损失函数之外,还使用到了Scanrefer、Referit3d中类似的多个辅助损失。 L o g L_{og} Log是三位object grounding损失, L s e n t L_{sent} Lsent是依赖于 s c l s s_{cls} scls的sentence分类损失, L o b j u L^u_{obj} Lobju是 unimodal的目标分类损失, L o b j m L^m_{obj} Lobjm是 multimodal的目标分类损失。
![]()
实验
在两种实验设置下进行对比:
1)Nr3D和Sr3D数据集:使用ground-truth proposal,指标就是最终在proposal中选择对错的正确率。
2)ScanRefer数据集:不使用ground-truth proposal,需要模型回归出3D Bboxes,指标是预测的Bboxes与GT框IOU的 [email protected],[email protected](即预测的Bboxes中与GTIOT大于0.25和0.5的百分比)
PointNet++ 和 BERT的参数都是使用与之前工作(SAT、Multi-view)相同的预训练参数,以保证公平对比。
旋转增强是将整个点云旋转不同的角度。具体来说,本文是从四个角度[0°、90°、180°、270°]中随机选择一个。
在Nr3D数据集中,分为view-dependent和view-independent两类,view-independent sentences包含了像“next to”、"farthest from"这样的距离相关的空间关系,view-dependent sentences包含了像“in front of”、"to the left of"这样的视角相关的空间关系。
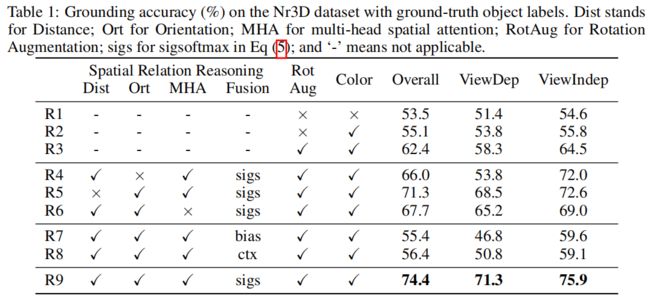
经过实验验证,在相对空间关系f中编码相对方向(θ)对view-dependent sentences是有效的,编码相对距离d对view-independent sentences是有效的。
为什么使用sigsoftmax对两个attention matrix进行融合?
答:审稿人也问了为什么使用sigsoftmax而不是softmax,作者回复说对他们都进行了尝试,结果是sigsoftmax的效果最好,给出的解释是 sigsoftmax 可以更积极地修改带有空间信息的原始自注意力权重。
此外,作者还设置了其他两种方案(参考RPE[35]):1)bias mode,将spatial attention matrix作为一个偏置项加入到standard self-attention中(R7);2)contextual mode:将spatial attention matrix作为key,将standard self-attention作为query来进行交互(R8)。结果证明都没有提出的sigsoftmax模式好。这一融合方式值得借鉴,当碰到两个attention matrix进行融合的问题时,采用本文提出的sigsoftmax方式进行融合,可以作为一个不错的baseline。
参考文献
[1] Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling
context in referring expressions. In ECCV, pages 69–85. Springer, 2016.
[7] Dave Zhenyu Chen, Angel X Chang, and Matthias Nießner. Scanrefer: 3d object localization in
rgb-d scans using natural language. In ECCV, pages 202–221. Springer, 2020.
[8] Panos Achlioptas, Ahmed Abdelreheem, Fei Xia, Mohamed Elhoseiny, and Leonidas Guibas.
Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes. In
ECCV, pages 422–440. Springer, 2020.
[9] Dailan He, Yusheng Zhao, Junyu Luo, Tianrui Hui, Shaofei Huang, Aixi Zhang, and Si Liu.
Transrefer3d: Entity-and-relation aware transformer for fine-grained 3d visual grounding. In
ACM MM, pages 2344–2352, 2021.
[10] Pin-Hao Huang, Han-Hung Lee, Hwann-Tzong Chen, and Tyng-Luh Liu. Text-guided graph
neural networks for referring 3d instance segmentation. In AAAI, volume 35, pages 1610–1618,
2021.
[11] Zhihao Yuan, Xu Yan, Yinghong Liao, Ruimao Zhang, Sheng Wang, Zhen Li, and Shuguang
Cui. Instancerefer: Cooperative holistic understanding for visual grounding on point clouds
through instance multi-level contextual referring. In ICCV, pages 1791–1800, 2021.
[12] Mingtao Feng, Zhen Li, Qi Li, Liang Zhang, XiangDong Zhang, Guangming Zhu, Hui Zhang,
Yaonan Wang, and Ajmal Mian. Free-form description guided 3d visual graph network for
object grounding in point cloud. In ICCV, pages 3722–3731, 2021.
[13] Lichen Zhao, Daigang Cai, Lu Sheng, and Dong Xu. 3dvg-transformer: Relation modeling for
visual grounding on point clouds. In ICCV, pages 2928–2937, 2021.
[14] Zhengyuan Yang, Songyang Zhang, Liwei Wang, and Jiebo Luo. Sat: 2d semantics assisted
training for 3d visual grounding. In ICCV, pages 1856–1866, 2021.
[15] Junha Roh, Karthik Desingh, Ali Farhadi, and Dieter Fox. Languagerefer: Spatial-language
model for 3d visual grounding. In CoRL, pages 1046–1056. PMLR, 2021.
[16] Shijia Huang, Yilun Chen, Jiaya Jia, and Liwei Wang. Multi-view transformer for 3d visual
grounding. In CVPR, 2022.
[18] Aishwarya Kamath, Mannat Singh, Yann LeCun, Gabriel Synnaeve, Ishan Misra, and Nicolas
Carion. Mdetr-modulated detection for end-to-end multi-modal understanding. In ICCV, pages
1780–1790, 2021.
[23] Junyu Luo, Jiahui Fu, Xianghao Kong, Chen Gao, Haibing Ren, Hao Shen, Huaxia Xia, and
Si Liu. 3d-sps: Single-stage 3d visual grounding via referred point progressive selection. In
CVPR, 2022.
[28] Ayush Jain, Nikolaos Gkanatsios, Ishita Mediratta, and Katerina Fragkiadaki. Looking outside
the box to ground language in 3d scenes. arXiv preprint arXiv:2112.08879, 2021.
[35] Kan Wu, Houwen Peng, Minghao Chen, Jianlong Fu, and Hongyang Chao. Rethinking and
improving relative position encoding for vision transformer. In ICCV, pages 10033–10041,
2021.