网络分块部署,最后图像矩阵拼接时中间有条缝隙,过渡不自然的问题解决方法
遇到的问题:
在训练好的网络上部署时,因为模型入口为256×256,预测的图片为512×512,如果resize再预测,结果分辨率低,故先裁剪成四份256×256再进行四次部署,结果进行拼接,但输出的拼接结果如下图:
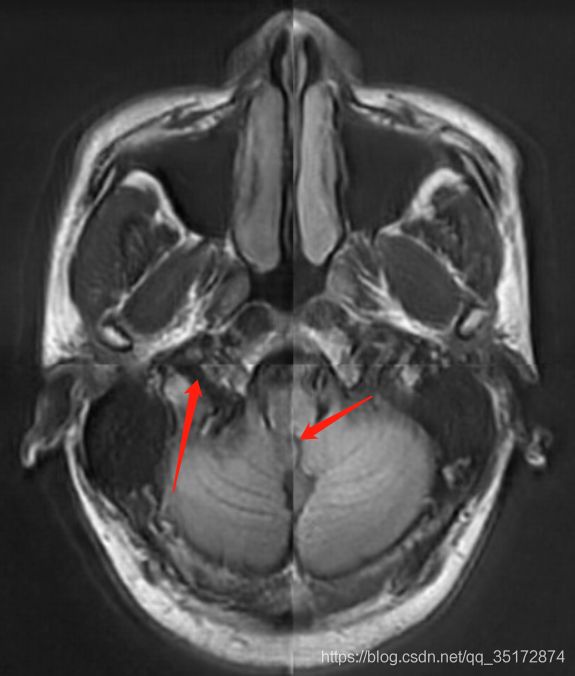
图像矩阵拼接时中间有条缝隙,过渡不自然,这大概是因为模型鲁棒性不是特别好,所以同一图像四个地方分别预测出的灰度分布不一致,致使边缘灰度出现比较大的突变
解决方法:
拼接的patch要有一定的overlap,然后取投票平均,就能弱化这种跳变问题了。一开始直接采用这位同学的方法,选择从最少量图开始,即采用了9张256×256图来组成512×512,当然这里的overlap为128,但明显的效果就是中心的过渡效果最自然,边缘较差。于是想到应该需要更多的图去做投票平均才可以达到更好的效果,所以采用25张256×256的图来组成512×512,这里的overlap为64.裁剪代码为:
def cutimg(img,num,overlap_factor):
factor = int(np.sqrt(num))
img_stacks = []
for i in range(factor):
for ii in range(factor):
img_temp = img[i*64:(i+4)*64,ii*64:(ii+4)*64]
img_stacks.append(img_temp)
return img_stacks
融合代码为:
def imgFusion(img1,img2,img3,img4,img5,overlap,left_right=True):
'''
图像加权融合
:param img1:
:param img2:
:param overlap: 重合长度
:param left_right: 是否是左右融合
:return:
'''
# 这里先暂时考虑平行向融合
if left_right: # 左右融合
col, row = img1.shape
img_new = np.zeros((row,2*col))
img_new[:,:col] = img1
img_new[:,overlap:overlap*2] = 0.5*img1[:,overlap:overlap*2]+0.5*img2[:,:overlap]
img_new[:,overlap*2:overlap*3] = 0.33*img1[:,overlap*2:overlap*3]+0.33*img2[:,overlap:overlap*2]+0.33*img3[:,:overlap]
img_new[:,overlap*3:overlap*4] = 0.25*img1[:,overlap*3:]+0.25*img2[:,overlap*2:overlap*3]+0.25*img3[:,overlap:overlap*2] + 0.25*img4[:,:overlap]
img_new[:,col:col+overlap] = 0.25*img2[:,overlap*3:]+0.25*img3[:,overlap*2:overlap*3]+0.25*img4[:,overlap:overlap*2] + 0.25*img5[:,:overlap]
img_new[:,col+overlap:col+overlap*2] = 0.33*img3[:,overlap*3:]+0.33*img4[:,overlap*2:overlap*3]+0.33*img5[:,overlap:overlap*2]
img_new[:,col+overlap*2:col+overlap*3]=0.5*img4[:,overlap*3:]+0.5*img5[:,overlap*2:overlap*3]
img_new[:,col+overlap*3:]=img5[:,overlap*3:]
else: # 上下融合
row,col = img1.shape
img_new = np.zeros((2*row,col))
img_new[:row,:] = img1
img_new[overlap:overlap*2,:] = 0.5*img1[overlap:overlap*2,:]+0.5*img2[:overlap,:]
img_new[overlap*2:overlap*3,:] = 0.33*img1[overlap*2:overlap*3,:]+0.33*img2[overlap:overlap*2,:]+0.33*img3[:overlap,:]
img_new[overlap*3:overlap*4,:] = 0.25*img1[overlap*3:,:]+0.25*img2[overlap*2:overlap*3,:]+0.25*img3[overlap:overlap*2,:] + 0.25*img4[:overlap,:]
img_new[row:row+overlap,:] = 0.25*img2[overlap*3:,:]+0.25*img3[overlap*2:overlap*3,:]+0.25*img4[overlap:overlap*2,:] + 0.25*img5[:overlap,:]
img_new[row+overlap:row+overlap*2,:] = 0.33*img3[overlap*3:,:]+0.33*img4[overlap*2:overlap*3,:]+0.33*img5[overlap:overlap*2,:]
img_new[row+overlap*2:row+overlap*3,:]=0.5*img4[overlap*3:,:]+0.5*img5[overlap*2:overlap*3,:]
img_new[row+overlap*3:,:]=img5[overlap*3:,:]
return img_new
h1 = imgFusion(dat_list[0],dat_list[1],dat_list[2],dat_list[3],dat_list[4],overlap=64,left_right=True)
h2 = imgFusion(dat_list[5],dat_list[6],dat_list[7],dat_list[8],dat_list[9],overlap=64,left_right=True)
h3 = imgFusion(dat_list[10],dat_list[11],dat_list[12],dat_list[13],dat_list[14],overlap=64,left_right=True)
h4 = imgFusion(dat_list[15],dat_list[16],dat_list[17],dat_list[18],dat_list[19],overlap=64,left_right=True)
h5 = imgFusion(dat_list[20],dat_list[21],dat_list[22],dat_list[23],dat_list[24],overlap=64,left_right=True)
dat = imgFusion(h1,h2,h3,h4,h5,overlap=64,left_right=False)
最终结果:
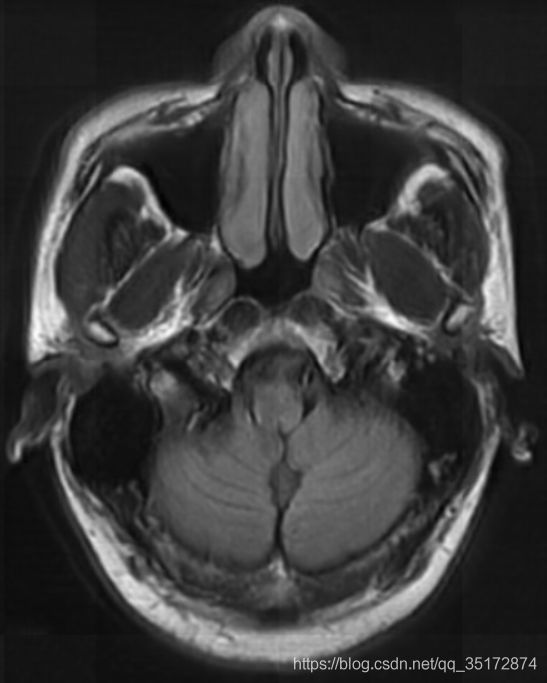
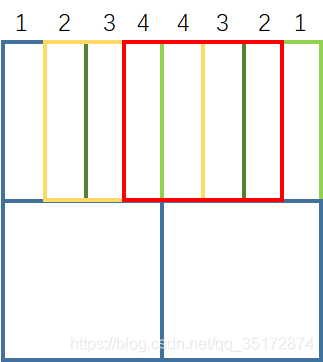
这张图用于说明下面这个代码,即最上面第一行的5个256×256的正方形的一步步的overlap,12344321表示此overlap(64)所涉及需要加权的图像个数,比如最左边的2,指的是第一个图像的64-128的地方和第二个图像的0-64overlap;最左边的3,指的是第一个图像的128-192的地方和第二个图像的64-128和第三个图像的0-64的overlap
img_new = np.zeros((row,2*col))
img_new[:,:col] = img1
img_new[:,overlap:overlap*2] = 0.5*img1[:,overlap:overlap*2]+0.5*img2[:,:overlap]
img_new[:,overlap*2:overlap*3] = 0.33*img1[:,overlap*2:overlap*3]+0.33*img2[:,overlap:overlap*2]+0.33*img3[:,:overlap]
img_new[:,overlap*3:overlap*4] = 0.25*img1[:,overlap*3:]+0.25*img2[:,overlap*2:overlap*3]+0.25*img3[:,overlap:overlap*2] + 0.25*img4[:,:overlap]
img_new[:,col:col+overlap] = 0.25*img2[:,overlap*3:]+0.25*img3[:,overlap*2:overlap*3]+0.25*img4[:,overlap:overlap*2] + 0.25*img5[:,:overlap]
img_new[:,col+overlap:col+overlap*2] = 0.33*img3[:,overlap*3:]+0.33*img4[:,overlap*2:overlap*3]+0.33*img5[:,overlap:overlap*2]
img_new[:,col+overlap*2:col+overlap*3]=0.5*img4[:,overlap*3:]+0.5*img5[:,overlap*2:overlap*3]
img_new[:,col+overlap*3:]=img5[:,overlap*3:]
意义:
一般2D图像并不需要裁剪,但3D医学图像由于显存的限制,一般会裁剪到64×64×64,所以如果分块预测再拼接,必定会遇到这种问题。
参考链接:
https://blog.csdn.net/xiaoxifei/article/details/103045958