KDD CUP 2023 多语言购物会话推荐数据竞赛正式启动
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
KDD Cup 介绍
KDD Cup是知识发现与数据挖掘国际会议(KDD)的竞赛项目,旨在提供一个平台来推动数据挖掘、机器学习和人工智能领域的研究和发展。自1997年开始,KDD Cup已成为这些领域最具影响力和最受欢迎的比赛之一。每一届KDD Cup都吸引了世界各地的数据科学家、研究人员和工程师,他们在严峻的比赛条件下,通过数据挖掘技术和算法来解决实际问题。KDD Cup的主题和任务涵盖了各种领域,包括社交网络、金融、医疗、电子商务等,参赛者需要通过数据挖掘和机器学习技术,从大规模的数据中发现规律和模式,得出有效的解决方案。KDD Cup不仅提供了一个展示最新技术和算法的平台,也为学术界和工业界之间的合作和交流提供了机会,促进了数据科学的发展。
赛事链接:https://www.aicrowd.com/challenges/amazon-kdd-cup-23-multilingual-recommendation-challenge
KDD CUP 2023 问题描述
用户购物意图建模是电子商务店铺的关键任务,它直接影响用户体验和参与度。准确地了解用户正在搜索什么,例如他们是否在搜索“苹果”这样的电子产品,对于提供个性化推荐至关重要。基于会话(Session)的推荐系统利用用户会话数据来预测他们的关心的下一个商品,随着数据挖掘和机器学习技术的快速发展,已经变得越来越重要。然而,在真实的多语言和数据不平衡情况下探索基于会话的推荐的研究还很少。
为了填补这个空白,Amazon Search Mission Understanding 团队推出了“多语言购物会话数据集”(Multilingual Shopping Session Dataset),该数据集包含来自六个不同地区的数百万用户会话,产品描述的主要语言为英语、德语、日语、法语、意大利语和西班牙语。该数据集在不同语言中很不平衡,法语、意大利语和西班牙语的产品比英语、德语和日语的产品更少。在此数据,Amazon Search Mission Understanding 团队提出了三个不同的任务:
Task 1: 预测来自英语、德语和日语的会话的下一个购买产品
Task 2: 预测来自法语、意大利语和西班牙语的会话的下一个购买产品(该任务鼓励使用迁移学习技术)
Task 3: 预测下一个购买产品的标题
主办方希望这个数据集和比赛能够鼓励多语言推荐系统的发展,从而增强个性化和了解全球趋势和偏好。通过促进数据科学的多样性和创新,这个比赛旨在提供受益于全球用户的实际解决方案。该数据集将向研究社区公开,并使用标准评估指标来评估模型的性能。
Timeline
Start Date: 15th March, 2023
End Date: 14th June, 2023 00.00 UTC
Winner Announcement: 14th June, 2023
Prizes
三个任务都有奖励。对于每个任务,排行榜上的前三名将获得以下现金奖励,并在KDD2023会议Workshop上进行汇报
First place : $4,000
Second place : $2,000
Third place : $1,000
对于每个任务,排行榜的4-10名可以获得价值$500的AWS积分
Dataset
多语言购物会话数据集(Multilingual Shopping Session Dataset)是一个包含来自六个不同地区的产品的匿名用户会话集合,即英语、德语、日语、法语、意大利语和西班牙语。它包括两个主要组成部分:用户会话和产品属性。用户会话是一个按时间顺序排列的产品列表,而产品属性包括各种细节,如产品标题、当地货币的价格、品牌、颜色和描述。(数据集已被匿名化处理,不代表实际生产特征。)
该数据集被分为三个部分:训练集、第一阶段测试集和第二阶段测试集。对于任务1和任务2,每种语言的比例大约为10:1:1。对于任务3,第一阶段测试和第二阶段测试的样本数量固定为10,000个。这三个任务共享相同的训练集,而它们的测试集根据它们的特定目标构建。任务1使用来自英语、德语和日语的数据,任务2使用来自法语、意大利语和西班牙语的数据。鼓励任务2的参与者使用迁移学习来提高其系统在测试集上的性能。对于任务3,测试集包括训练集中没有出现的产品,并要求参赛者根据用户会话生成下一个产品的标题。
表1总结了数据集的一些统计信息。作为KDD Cup比赛的一部分,该数据集将公开发布,每个产品都由唯一的亚马逊标准识别号(ASIN)标识,使得从网络中提取更多信息变得更加容易。参赛者可以自由地使用外部信息来训练他们的算法,例如开源数据集和预训练的语言模型,但必须在描述算法时指名这些信息超出了提供的数据集。

此外,主办方列出了产品属性数据的列名称及其含义:
locale:产品的区域设置代码(例如,DE)
id:产品的唯一标识符。也称为亚马逊标准产品编号(ASIN)(例如,B07WSY3MG8)
title:产品的标题(例如,“Japanese Aesthetic Sakura Flowers Vaporwave Soft Grunge Gift T-Shirt”)
price:产品在当地货币中的价格(例如,24.99)
brand:产品品牌名称(例如,“Japanese Aesthetic Flowers & Vaporwave Clothing”)
color:产品颜色(例如,“Black”)
size:产品尺寸(例如,“XXL”)
model:产品型号(例如,“iPhone 13”)
material:产品材料(例如,“cotton”)
author:产品作者(例如,“J. K. Rowling”)
desc:关于产品的主要特性的描述,通过项目符号列出(例如,“Solid colors: 100% Cotton; Heather Grey: 90% Cotton, 10% Polyester; All Other Heathers …”)
Tasks
本次比赛的主要目标是构建更好的基于会话的算法/模型,预测用户关注的下一个产品或生成其标题文本。主办方提出的三个任务如下:
·下一产品推荐(Next Product Recommendation)
·下一产品推荐(针对语言/区域的低覆盖度)(Next Product Recommendation for Underrepresented Languages/Locales)
·下一产品标题生成(Next Product Title Generation)
请注意,这三个任务共享相同的训练集。但是,这三个任务的目标不同。每个任务的详细信息如下:
任务1:
任务1旨在预测客户在会话数据和每个产品的属性的基础上,下一个可能参与的产品。任务1的测试集包含来自英语、德语和日语区域的数据。参赛者需要创建一个程序,可以预测测试集中每个会话的下一个产品。
为了提交预测结果,参赛者应提供一个单独的parquet文件,其中每行对应于测试集中的一个会话。对于每个会话,参赛者应预测100个最有可能参与的产品ID(ASIN),并基于会话中的历史参与情况进行预测。产品ID应存储在列表中,并按置信度递减的顺序列出,最有信心的预测在索引0处,最不自信的预测在索引99处。
例如,如果对于一个会话,product_25是最有信心的预测,product_100是第二有信心的预测,product_199是同一会话的最不自信的预测,参赛者的提交应首先列出product_25,接着是product_100,中间有很多其他的预测,最后是product_199。
示例输入:
locale |
example_session |
UK |
[product_1, product_2, product_3] |
DE |
[product_4, product_5] |
示例输出:
next_item |
[product_25, product_100,…, product_199] |
[product_333, product_123,…, product_231 |
任务1的评估指标是Mean Reciprocal Rank (MRR)。
MRR是信息检索和推荐系统中用于衡量模型提供相关结果效果的指标。MRR的计算分为两步:(1)计算倒数排名。倒数排名是指第一个相关项目出现在推荐列表中的位置的倒数。如果在列表中没有找到相关项,则倒数排名被认为是0。(2)计算每个会话的第一个相关项的倒数排名的平均值。
其中Rank(t)是测试会话t的前K个结果排名列表中基准真相的排名,如果在前K个排名列表中没有基准真相,则将1Rank(t)设置为0。MRR值的范围为0到1,值越高表示性能越好。完美的MRR得分为1,表示模型总是将第一个相关项放在推荐列表的顶部。MRR得分为0表示在任何查询或用户的推荐列表中都没有找到相关项。
任务2:
任务2的目标与任务1类似,但测试集是由法语、意大利语和西班牙语构建的。任务2主要关注这三种低覆盖语言的表现。鼓励参赛者将从拥有足够数据的语言(如英语、德语和日语)中获得的知识转移,以提高对法语、意大利语和西班牙语的推荐质量。
输入/输出和评估指标与任务1相同。
任务3:
任务3要求参赛者根据客户的会话数据,预测下一个产品的标题。与任务1和任务2侧重推荐现有产品不同,预测新的或“冷启动”产品提出了独特的挑战。生成的标题有可能改善各种下游任务,包括冷启动推荐和导航。任务3的测试集包括来自所有六个地区的数据,参赛者应提交一个包含每个输入文件的行/会话生成标题的单个parquet文件。标题应以字符串格式保存。
示例输入:
locale |
example_session |
UK |
[product_1, product_2, product_3] |
DE |
[product_4, product_5] |
示例输出:
next_item_title |
"toilet paper tube" |
"bottle of ink" |
对于这个任务,主办方使用bilingual evaluation understudy(BLEU)作为评估指标。BLEU是一种用于评估自然语言生成质量的指标,通过将生成的候选项与一个或多个参考项进行比较来计算。BLEU使用了一组n-gram修正精度进行计算。具体而言,
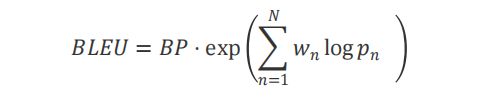
其中,N表示n-gram的最大阶数,w_n是n-gram的权重,p_n是参考翻译中n-gram在候选翻译中出现的频率,BP是短语惩罚项(Brevity Penalty),用于惩罚候选翻译长度较短的情况。exp是指数函数。p_n是每个n-gram的精度分数。精度分数是候选项中出现在任何参考项中的n-gram数与候选项中的总n-gram数之比。数学上,p_n的计算如下:

其中,count_n^C(s) 是候选项C中n-gram s的数量。count_n^r(s)是在n-grams的数量,其中R是一组参考项。短语惩罚项brevity penalty(BP)是一种修正因子,惩罚生成的候选项与参考项相比太短的情况。长度惩罚项的计算如下:
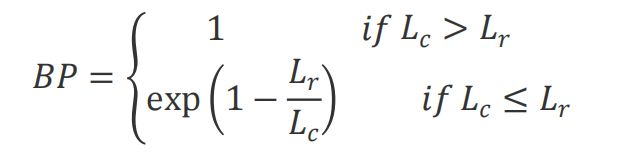
Leaderboard & Evaluations
每个任务都将有单独的排行榜,在竞赛期间对公共测试集上评估的模型将被维护在该排行榜上。在竞赛结束时,将针对私有测试集上评估的模型维护一份私人排行榜。后者排行榜将用于决定竞赛中每个任务的获胜者。公共测试集上的排行榜旨在指导参与者评估其模型性能并与其他参与者进行比较。
KDD Cup Workshop
KDD Cup是由计算机协会的知识发现和数据挖掘特别兴趣小组(ACM SIGKDD)组织的年度数据挖掘和知识发现竞赛。该竞赛旨在通过为研究人员和从业人员提供平台,分享各个领域中的具有挑战性问题的创新解决方案,促进数据挖掘和知识发现的研究和发展。
赛事链接:https://www.aicrowd.com/challenges/amazon-kdd-cup-23-multilingual-recommendation-challenge
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1000多位海内外讲者,举办了逾500场活动,超500万人次观看。

我知道你
在看
哦
~
![]()
点击 阅读原文 查看赛事!