【读论文】MUFusion
【读论文】MUFusion
- 介绍
- 损失函数
-
- 存储单元
- 内容损失
- 网络架构
- 总结
- 参考
论文: https://www.sciencedirect.com/science/article/abs/pii/S1566253522002202
如有侵权请联系博主
介绍
这次介绍的还是发表在imformation fusion的一篇论文,文中介绍的方法是一种可以用于多模态图像融合的统用融合算法。
这篇文章中提出了一种记忆单元,即将训练过程中产生的图像存储下来,与当前训练阶段产生的图像一起来训练网络,从而达到一个更好的效果,整个过程如下图所示。

要是看着有点懵,那就一起往下看看吧。

损失函数
这一次与以往的博客不同,我们先介绍损失函数,先了解损失函数,之后的网络结构就很简单了。
存储单元

回收下文章开头的那张图,我们先看下左边,这就是我们常规的计算损失的方式,这里先说下,net就是我们自己的网络,y是输出图像,x是输入图像,直接将x与y来计算损失。
然后再看右边,emmmmmmm。。。。。这是嘛呀
我们先大概讲一下思想,带着这个思想我们在具体去看
整个过程可以理解为在训练的时候我们会保存上一个epoch产生的输出图像,然后此时我们在计算损失来调整网络参数时,不仅仅考虑现在的输出图像和源图像之间的损失,也会考虑上一个epoch的输出图像和原图像的损失,这两个损失之间要有一个权重,是根据图像自身生成。
大概知道流程之后,我们开始详细来看
保存上一个epoch产生的输出图像没有什么好说的,我么先看下两个损失的权重是怎么计算的。

这里的O是当前的输出图像,Opre是上一个epoch的输出图像,I1,I2是源图像。SA和SB就是对应的权重。
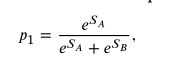
![]()
而后使用SA和SB来进行softmax计算,产生两个损失的权重,然后再代入总损失函数中,损失函数的具体内容我们下一部分再详细去讲。
![]()
这时我们和上图右半部分对一下,这里注意Yi-1其实就是Opre,Xi就是I1,I2,此时你会发现就和上图完全的对上了。
那么为什么要加这个损失呢?
先看下原文作者中的描述(直接翻译成中文)
我们利用训练过程中获得的中间融合结果来进一步协作监督融合图像。这样,我们的融合结果不仅可以从原始输入图像中学习,还可以从网络本身的中间输出中受益。
在我个人粗浅的理解来看,可以认为作者加入这个记忆单元是来帮助网络中的参数可以朝着期望的方向去变化,前文中已经提到了作者使用SSIM来确定两个损失函数的权重,也就是说哪一个融合图像与源图像的亮度,对比度和结构的相似度越高,那么就偏向于朝着哪一类图像发展,在训练过程中难免会出现训练结果偏向非期望的方向训练的情况,通过作者设置的权重,记忆单元损失可以促使网络中的参数朝着期望的方向变化。
该损失的具体内容如下

不需要掩码,直接算,这个好理解多了
到现在为止,我们只介绍了文章中损失函数的一部分,接下来我们再来看看他是怎么做的显著性目标提取的
内容损失

看到这里,你会发现,是不是有点熟,当你看到在计算损失时在输入图像和输出图像上乘以一个相同的w,你会想到啥?
是不是会想到掩码,毕竟现在用的确实很多。各种各样的掩码花里胡哨的。很巧的是,文章中的w也是掩码,我们来看看她是怎么计算这个掩码的。

文章中计算掩码是先通过预训练的vgg19来提取图像的特征,然后将提取到的特征上采样至与源图像相同大小。
接下来就是提取出显著性特征了,首先需要将提取的特征图按通道将每个点的绝对值相加(即L1范式),即多个通道相加之后生成一个通道,该通道中每个值都是原来多通道的对应值的L1范式的结果。公司如下

而后将单通道数据进行处理,处理方式如下,其实就是将该值附近的值相加起来,来替换当前值。
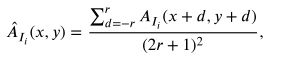
最后在进行以下操作,这里是不是有点迷糊了,咋又出来个k?嘎嘎这么多字母。
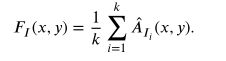
这里的k对应的是vgg19网络中的每一个下采样(max-pooling),即将每一个下采样产生的特征图进行上述操作之后,在求每个下采样结果的均值,产生的均值我们称为活动水平特征,就使用这个产生的活动水平特征计算决策图就可以了。
**那么怎么计算这个决策图呢?**来看个更迷的
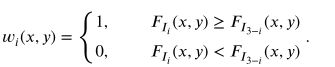
决策图的计算方式如上图所示,是不是有点迷,这个3是啥。。。。

ok ok ok,言归正传,我们看下下面的这个损失函数,这里j有1,2两个值,分别代表红外和可视图像,我们把j的值带入到上面的公式中,你就会发现,就是将F1与F2比,F2和F1比。

简单来说就是比较红外图像和可视图像的活动水平特征,谁大我就留那一部分(像素级的),即对应像素的活动水平特征相比较,哪一个像素的活动水平特征值大,我就留下哪一个像素。
到现在为止,我们就知道掩码是怎么来的了。
最后补充一下怎么计算的损失

网络架构

先看下整体架构,你会发现,唉~~ 这也不难呀,也就先这样,在那样,然后再那样
算了,说实话吧,确实不简单

接下来我们详细的看下这个网络架构。
这次我们就不单独去讲每个部分,直接讲比较容易懂一些。
从图上我们就可以看出来,首先是将两个图象按通道连接起来,而后就是卷积了。在C3这里作者做了一个很有趣的操作,**就是将步长设成了2,**而后再通过设置其他的参数,就可以生成另一个尺度的特征了,这样的好处就是避免了直接下采样导致的信息丢失问题。
其他的就是类似U-Net的跳跃连接,这种连接方式可以尽量的减少卷积过程中特征的丢失,可以看到编码部分和解码部分对应的块之间都有跳跃连接。
解码部分也有一个上采样,最终通过解码部分就生成了融合图像。
总结
整篇文章最让我惊艳的就是该网络采用了一个记忆单元,这和我们之前看到的大多数网络都不一样,通过这种方式来促使网络残生最优解,很有趣的一个地方。
其他融合图像论文解读
==》读论文专栏,快来点我呀《==
【读论文】DIVFusion: Darkness-free infrared and visible image fusion
【读论文】RFN-Nest: An end-to-end residual fusion network for infrared and visible images
【读论文】DDcGAN
【读论文】Self-supervised feature adaption for infrared and visible image fusion
【读论文】FusionGAN: A generative adversarial network for infrared and visible image fusion
【读论文】DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs
【读论文】DenseFuse: A Fusion Approach to Infrared and Visible Images
参考
[1] MUFusion: A general unsupervised image fusion network based on memory unit