Python爬虫实战——爬取新闻数据(简单的深度爬虫)
前言
又到了爬新闻的环节(好像学爬虫都要去爬爬新闻,没办法谁让新闻一般都很好爬呢XD,拿来练练手),只作为技术分享,这一次要的数据是分在了两个界面,所以试一下深度爬虫,不过是很简单的。
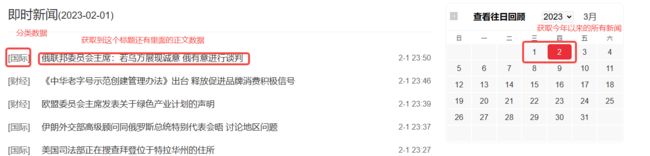
数据目标
相关库
import openpyxl
import requests
from lxml import etree
from tqdm import tqdm
数据爬取
网页url
url = 'https://www.chinanews.com.cn/scroll-news/news1.html'1.先看看网站网址的规律
![]()
发现这部分就是每一天的新闻,现在把这个链接组合一下,我暂时只拿1月份的数据
# 组合日期链接
def cnew_url():
f = open(r'D:/工作文件/cnew_url.txt', 'w', encoding='utf8')
for i in range(1, 32):
if i < 10:
url = 'https://www.chinanews.com.cn/scroll-news/2023/010' + str(i) + '/news.shtml'
else:
url = 'https://www.chinanews.com.cn/scroll-news/2023/01' + str(i) + '/news.shtml'
f.write(url + '\n')
f.close()2.接下来访问每一天的链接获取到新闻的链接还有我们需要的分类的数据,然后再对新闻链接发起request请求获取到我们需要的标题和正文数据
def cnew_data():
f = open(r'D:/工作文件/cnew_url.txt', encoding='utf8') # 读取上面已经组合好的链接
l = openpyxl.load_workbook(r'D:\工作文件\cnew_data.xlsx')
sheet = l.active
m = open(r'D:/工作文件/cnew_url1.txt', 'a', encoding='utf8') # 保存报错的链接
x = 1 # 从Excel的第几行开始写入
for i in f:
lj1 = []
# 发起请求,获取页面里面的新闻链接
req = requests.get(i.replace('\n', ''), headers=headers)
# 设置网页编码,不设置会乱码
req.encoding = 'utf8'
ht = etree.HTML(req.text)
# 获取分类的数据还有正文链接
fl = ht.xpath("//div[@class='dd_lm']/a/text()")
lj = ht.xpath("//div[@class='dd_bt']/a/@href")
# 链接有两种格式,分别组合成可以用的
for j in lj:
if j[:5] == '//www':
lj1.append('https:' + j)
else:
lj1.append('https://www.chinanews.com.cn/' + j)
n = 0 # 这是匹配文章和分类
for k in tqdm(lj1):
try:
data = []
# 发起请求
reqs = requests.get(k, headers=headers, timeout=10)
reqs.encoding = 'utf8'
ht1 = etree.HTML(reqs.text)
# 因为这网站的正文所在的xpath路径不同,现在就是拿两种路径下的文本
bt = ht1.xpath("//h1[@class='content_left_title']/text()") # 标题
if bt: # 判断标题是不是为空,不为空就走第一种xpath
data.append([fl[n]]) # 爬到第几个链接就把第几个的类别放进来
data.append(ht1.xpath("//h1[@class='content_left_title']/text()")) # 标题
data.append(ht1.xpath("//div[@class='left_zw']/p/text()")) # 简介
data.append([lj1[n]]) # 文章的链接
else:
data.append([fl[n]])
data.append(ht1.xpath("//div[@class='content_title']/div[@class='title']/text()"))
data.append(ht1.xpath("//div[@class='content_desc']/p/text()")) # 简介
data.append([lj1[n]])
# 数据写入
for y in range(len(data)):
sheet.cell(x, y + 1).value = '\n'.join(data[y])
x += 1
n += 1
except Exception as arr:
m.write(lj1[n])
continue
# 保存
l.save(r'D:\工作文件\cnew_data.xlsx')
f.close()
m.close()主函数
if __name__ == '__main__':
# cnew_url()
cnew_data()完整代码
少了一下注释,详细可看前面
import openpyxl
import requests
from lxml import etree
from tqdm import tqdm
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
# 组合日期链接
def cnew_url():
f = open(r'D:/工作文件/cnew_url.txt', 'w', encoding='utf8')
for i in range(1, 6):
if i < 10:
url = 'https://www.chinanews.com.cn/scroll-news/2023/020' + str(i) + '/news.shtml'
else:
url = 'https://www.chinanews.com.cn/scroll-news/2023/02' + str(i) + '/news.shtml'
f.write(url + '\n')
f.close()
def cnew_data():
f = open(r'D:/工作文件/cnew_url.txt', encoding='utf8') # 读取上面已经组合好的链接
l = openpyxl.load_workbook(r'D:\工作文件\cnew_data.xlsx')
sheet = l.active
m = open(r'D:/工作文件/cnew_url1.txt', 'a', encoding='utf8') # 保存报错的链接
x = 1 # 从Excel的第几行开始写入
for i in f:
lj1 = []
# 发起请求,获取页面里面的新闻链接
req = requests.get(i.replace('\n', ''), headers=headers)
# 设置网页编码,不设置会乱码
req.encoding = 'utf8'
ht = etree.HTML(req.text)
# 获取分类的数据还有正文链接
fl = ht.xpath("//div[@class='dd_lm']/a/text()")
lj = ht.xpath("//div[@class='dd_bt']/a/@href")
# 链接有两种格式,分别组合成可以用的
for j in lj:
if j[:5] == '//www':
lj1.append('https:' + j)
else:
lj1.append('https://www.chinanews.com.cn/' + j)
n = 0
for k in tqdm(lj1):
try:
data = []
reqs = requests.get(k, headers=headers, timeout=10)
reqs.encoding = 'utf8'
ht1 = etree.HTML(reqs.text)
bt = ht1.xpath("//h1[@class='content_left_title']/text()") # 标题
if bt:
data.append([fl[n]])
data.append(ht1.xpath("//h1[@class='content_left_title']/text()")) # 标题
data.append(ht1.xpath("//div[@class='left_zw']/p/text()")) # 简介
data.append([lj1[n]])
else:
data.append([fl[n]])
data.append(ht1.xpath("//div[@class='content_title']/div[@class='title']/text()"))
data.append(ht1.xpath("//div[@class='content_desc']/p/text()")) # 简介
data.append([lj1[n]])
for y in range(len(data)):
sheet.cell(x, y + 1).value = '\n'.join(data[y])
x += 1
n += 1
except Exception as arr:
m.write(lj1[n])
continue
l.save(r'D:\工作文件\cnew_data.xlsx')
f.close()
m.close()
if __name__ == '__main__':
# cnew_url()
cnew_data()