大数据基础架构总结
简介:本文是对大数据领域的基础论文的阅读总结,相关论文包括GFS,MapReduce、BigTable、Chubby、SMAQ。
大数据出现的原因:
大多数的技术突破来源于实际的产品需要,大数据最初诞生于谷歌的搜索引擎中。随着web2.0时代的发展,互联网上数据量呈献爆炸式的增长,为了满足信息搜索的需要,对大规模数据的存储提出了非常强劲的需要。基于成本的考虑,通过提升硬件来解决大批量数据的搜索越来越不切实际,于是谷歌提出了一种基于软件的可靠文件存储体系GFS,使用普通的PC机来并行支撑大规模的存储。存进去的数据是低价值的,只有对数据进行过加工才能满足实际的应用需要,于是谷歌又创造了MapReduce这一计算模型,该模型能够利用集群的力量将复杂的运算拆分到每一台普通PC上,计算完成后通过汇总得到最终的计算结果,这样就能够通过直接增加机器数量就获得更好的运算能力了。
有了GFS和MapReduce之后,文件的存储和运算得到了解决,这时候又出现了新的问题。GFS的随机读写能力很差,而谷歌有需要一种来存放格式化数据的数据库,原本通过单机的数据库就能解决的问题到了谷歌那里就悲剧了,于是神器的谷歌就又开发了一套BigTable系统,利用GFS的文件存储系统外加一个分布式的锁管理系统Chubby就设计出来了BigTable这样一个列式的数据库系统。
在谷歌完成了上述的系统后,就把其中的思想作为论文发布出来了,基于这些论文,出现了一个用JAVA写的类GFS开源项目Hadoop,最开始hadoop的赞助人是yahoo,后来这个项目成了Apche的顶级项目。
大数据的解决方案:
谷歌的那一套系统是闭源的,开源的Hadoop于是就广泛传播开来了。

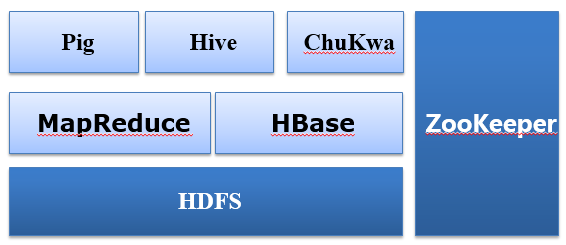
和谷歌那套系统类似,Hadoop的最核心的存储层叫做HDFS,全称是Hadoop文件存储系统,有了存储系统还要有分析系统,于是就有了开源版本的MapReduce,类似的参照BigTable就有了Hbase。一开源之后整个系统用的人就多了,于是大家都像要各种各样的特性。facebook的那些人觉得mapreduce程序太难写,于是就开发了Hive,Hive就是一套能把SQL语句转成Mapreduce的工具,有了这套工具只要你会SQL就可以来Hadoop上写mapreduce程序分析数据了。对了,参考chubby,我们有了开源的ZooKeeper来作为分布式锁服务的提供者。
由于Hadoop最开始设计是用来跑文件的,对于数据的批处理来说这没什么问题,有一天突然大家想要一个实时的查询服务,数据这么大,要满足实时查询首先要抛开的是mapreduce,因为它真的好慢。2008年的时候一家叫Cloudera的公司出现了,他们的目标是要做hadoop界的redhat,把各种外围系统打包进去组成一个完整的生态系统,后来他们开发出来了impala,impala的速度比mapreduce在实时分析上的效率有了几十倍的提升,后来hadoop的创始人Doug Cutting也加入了cloudera。这时候学院派也开始发力了,加州大学伯克利分校开发出来了Spark来做实时查询处理,刚开始Spark的语法好诡异,后来慢慢出现了Shark项目,渐渐的使得Spark向SQL语法靠近。
未来的发展趋势:
时代的发展决定了未来几乎就要变成数据的时代了,在这样的一个时代,大数据的需求越来越深,摒弃过去的抽样调查,改为全量的统计分析,从一些原本无意义的数据中挖掘价值。当前大数据已经开始逐渐服务于我们的生活,搜索、科学、用户分析。。。
为了进一步提供大数据的分析能力,内存计算的概念在未来还会持续很长的时间,通过内存计算,摒弃磁盘IO对性能的天花板作用,将运算的结果以实时的方式呈献在我们面前。