Midjourney劲敌来了! 谷歌发布文生图模型StyleDrop,可生成任意风格
来源 | 新智元
Midjourney强敌来了!谷歌定制大师StyleDrop,将一张图片作为参考,不论多复杂的艺术风格都能复刻。
谷歌StyleDrop一出,瞬间在网上刷屏了。
给定梵高的星空,AI化身梵高大师,对这种抽象风格顶级理解后,做出无数幅类似的画作。

再来一张卡通风,想要绘制的物体呆萌了许多。

甚至,它还能精准把控细节,设计出原风格的logo。

StyleDrop的魅力在于,只需要一张图作为参考,无论多么复杂的艺术风格,都能解构再复刻。
网友纷纷表示,又是淘汰设计师的那种AI工具。

StyleDrop爆火研究便是来自谷歌研究团队最新出品。

论文地址:
https://arxiv.org/pdf/2306.00983.pdf
大模型研究测试传送门
GPT-4能力研究传送门(遇浏览器警告点高级/继续访问即可):
https://gpt4test.com
现在,有了StyleDrop这样的工具,不但可以更可控地绘画,还可以完成之前难以想象的精细工作,比如绘制logo。
就连英伟达科学家将其称为「现象级」成果。

「定制」大师
论文作者介绍道,StyleDrop的灵感来源Eyedropper(吸色/取色工具)。
同样,StyleDrop同样希望大家可以快速、毫不费力地从单个/少数参考图像中「挑选」样式,以生成该样式的图像。

一只树懒能够有18种风格:
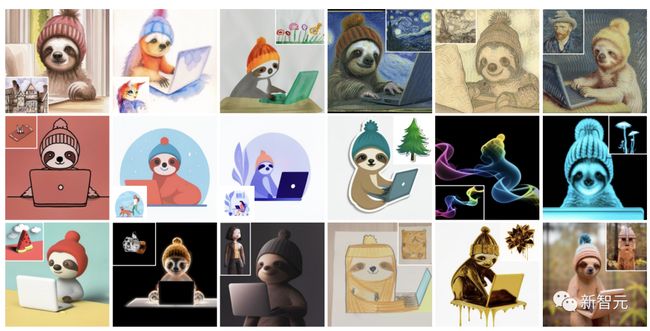
一只熊猫有24种风格:

小朋友画的水彩画,StyleDrop完美把控,甚至连纸张的褶皱都还原出来了。
不得不说,太强了。

还有StyleDrop参考不同风格对英文字母的设计:

同样是梵高风的字母。

还有线条画。线条画是对图像的高度抽象,对画面生成构成合理性要求非常高,过去的方法一直很难成功。

原图中奶酪阴影的笔触还原到每种图片的物体上。

参考安卓LOGO创作。

此外,研究人员还拓展了StyleDrop的能力,不仅能定制风格,结合DreamBooth,还能定制内容。
比如,还是梵高风,给小柯基生成类似风格的画作:

再来一个,下面这只柯基有种埃及金字塔上的「狮身人面像」的感觉。

如何工作?
StyleDrop基于Muse构建,由两个关键部分组成:
一个是生成视觉Transformer的参数有效微调,另一个是带反馈的迭代训练。
之后,研究人员再从两个微调模型中合成图像。
Muse是一种基于掩码生成图像Transformer最新的文本到图像的合成模型。它包含两个用于基础图像生成(256 × 256)和超分辨率(512 × 512或1024 × 1024)的合成模块。

每个模块都由一个文本编码器T,一个transformer G,一个采样器S,一个图像编码器E和解码器D组成。
T将文本提示t∈T映射到连续嵌入空间E。G处理文本嵌入e∈E以生成视觉token序列的对数l∈L。S通过迭代解码从对数中提取视觉token序列v∈V,该迭代解码运行几步的transformer推理,条件是文本嵌入e和从前面步骤解码的视觉token。
最后,D将离散token序列映射到像素空间I。总的来说,给定一个文本提示t,图像I的合成如下:
![]()
图2是一个简化了的Muse transformer层的架构,它进行了部分修改,为的是支持参数高效微调(PEFT)与适配器。
使用L层的transformer处理在文本嵌入e的条件下以绿色显示的视觉token序列。学习参数θ被用于构建适配器调优的权重。

为了训练θ,在许多情况下,研究人员可能只给出图片作为风格参考。
研究人员需要手动附加文本提示。他们提出了一个简单的、模板化的方法来构建文本提示,包括对内容的描述,后面跟着描述风格的短语。
例如,研究人员在表1中用「猫」描述一个对象,并附加「水彩画」作为风格描述。

在文本提示中包含内容和风格的描述至关重要,因为它有助于从风格中分离出内容,这是研究人员的主要目标。
图3则是带反馈的迭代训练。
当在单一风格参考图像(橙色框)上进行训练时,StyleDrop生成的一些图像可能会展示出从风格参考图像中提取出的内容(红色框,图像背景中含有与风格图像类似的房子)。
其他图像(蓝色框)则能更好地从内容中拆分出风格。对StyleDrop进行好样本(蓝色框)的迭代训练,结果在风格和文本保真度之间取得了更好的平衡(绿色框)。

这里研究人员还用到了两个方法:
-CLIP得分
该方法用于测量图像和文本的对齐程度。因此,它可以通过测量CLIP得分(即视觉和文本CLIP嵌入的余弦相似度)来评估生成图像的质量。
研究人员可以选择得分最高的CLIP图像。他们称这种方法为CLIP反馈的迭代训练(CF)。
在实验中,研究人员发现,使用CLIP得分来评估合成图像的质量是提高召回率(即文本保真度)的有效方式,而不会过多损失风格保真度。
然而从另一方面看,CLIP得分可能不能完全与人类的意图对齐,也无法捕捉到微妙的风格属性。
-HF
人工反馈(HF)是一种将用户意图直接注入到合成图像质量评估中的更直接的方式。
在强化学习的LLM微调中,HF已经证明了它的强大和有效。
HF可以用来补偿CLIP得分无法捕捉到微妙风格属性的问题。
目前,已有大量研究关注了文本到图像的扩散模型的个性化问题,以合成包含多种个人风格的图像。
研究人员展示了如何以简单的方式将DreamBooth和StyleDrop结合起来,从而使风格和内容都能实现个性化。
这是通过从两个修改后的生成分布中采样来完成的,分别由风格的θs和内容的θc指导,分别是在风格和内容参考图像上独立训练的适配器参数。
与现有的成品不同,该团队的方法不需要在多个概念上对可学习的参数进行联合训练,这就带来了更大的组合能力,因为预训练的适配器是分别在单个主题和风格上进行训练的。
研究人员的整体采样过程遵循等式(1)的迭代解码,每个解码步骤中采样对数的方式有所不同。
设t为文本提示,c为无风格描述符的文本提示,在步骤k计算对数如下:
![]()

其中:γ用于平衡StyleDrop和DreamBooth——如果γ为0,我们得到StyleDrop,如果为1,我们得到DreamBooth。
通过合理设置γ,我们就可以得到合适的图像。
实验设置
目前为止,还没有对文本-图像生成模型的风格调整进行广泛的研究。
因此,研究人员提出了一个全新实验方案:
- 数据收集
研究者收集了几十张不同风格的图片,从水彩和油画,平面插图,3D渲到不同材质的雕塑。
- 模型配置
研究人员使用适配器调优基于Muse的StyleDrop 。对于所有实验,使用Adam优化器更新1000步的适配器权重,学习速率为0.00003。除非另有说明,研究人员使用StyleDrop来表示第二轮模型,该模型在10多个带有人工反馈的合成图像上进行训练。
- 评估
研究报告的定量评估基于CLIP,衡量风格一致性和文本对齐。此外,研究人员进行了用户偏好研究,以评估风格一致性和文本对齐。
如图,研究人员收集的18个不同风格的图片,StyleDrop处理的结果。
可以看到,StyleDrop能够捕捉各种样式的纹理、阴影和结构的细微差别,能够比以前更好地控制风格。

为了进行比较,研究人员还介绍了DreamBooth在Imagen上的结果,DreamBooth在Stable Diffusion上的LoRA实现和文本反演的结果。
具体结果如表所示,图像-文本对齐(Text)和视觉风格对齐(Style)的人类评分(上)和CLIP评分(下)的评价指标。
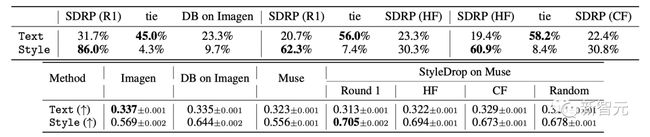
(a) DreamBooth,(b) StyleDrop,和 © DreamBooth + StyleDrop的定性比较:

这里,研究人员应用了上面提到的CLIP分数的两个指标——文本和风格得分。
对于文本得分,研究人员测量图像和文本嵌入之间的余弦相似度。对于风格得分,研究人员测量风格参考和合成图像嵌入之间的余弦相似度。
研究人员为190个文本提示生成总共1520个图像。虽然研究人员希望最终得分能高一些,但其实这些指标并不完美。
而迭代训练(IT)提高了文本得分,这符合研究人员的目标。
然而,作为权衡,它们在第一轮模型上的风格得分有所降低,因为它们是在合成图像上训练的,风格可能因选择偏见而偏移。
Imagen上的DreamBooth在风格得分上不及StyleDrop(HF的0.644对比0.694)。
研究人员注意到,Imagen上的DreamBooth的风格得分增加并不明显(0.569 → 0.644),而Muse上的StyleDrop的增加更加明显(0.556 →0.694)。
研究人员分析,Muse上的风格微调比Imagen上的更有效。
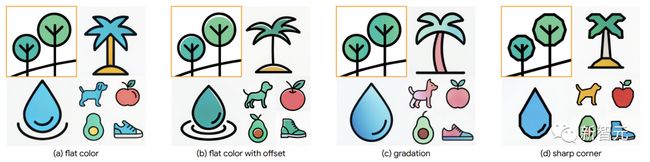
另外,在细粒度控制上, StyleDrop捕捉微妙的风格差异,如颜色偏移,层次,或锐角的把控。
网友热评
要是设计师有了StyleDrop,10倍速工作效率,已经起飞。
AI一天,人间10年,AIGC正在以光速发展,那种晃瞎人眼的光速!
工具只是顺应了潮流,该被淘汰的已经早被淘汰了。
对于制作Logo来说这个工具比Midjourney好用得多。