Generative AI 新世界 | 走进文生图(Text-to-Image)领域
在之前的四篇 “Generative AI 新世界” 中,我们带领大家一起探索了生成式 AI(Generative AI),以及大型语言模型(LLMs)的全新世界概览。并在文本生成(Text Generation)领域做了一些概述、相关论文解读、以及在亚马逊云科技的落地实践和动手实验。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
从本期文章开始,我们将一起探索生成式 AI(Generative AI)的另一个进步迅速的领域:文生图(Text-to-Image)领域。我们将用三个系列文章的篇幅,来一起洞察在文生图(Text-to-Image)领域的前世今生、相关论文解读、以及在亚马逊云科技的落地实践和实际代码实现展示等。
CLIP:基于对比文本-图像对的预训练
2021 年之前,在自然语言处理 (Natural Language Processing) 领域有很多预训练方法都获得了成功。例如,GPT-3 的 175B 从网上搜集了近 5 亿 tokens 进行预训练,在很多下游任务上实现 SOTA (State-of-the-Art) 性能和 Zero-Shot Learning。这说明从海量互联网数据 (web-scale) 中学习,是可以超过高质量的人工标注 NLP 数据集的。
但是在计算机视觉 (Computer Vision) 领域的预训练模型还是主要基于人工标注的 ImageNet 数据进行训练。由于人工标注的工作量巨大,许多科学家们开始设想:如何构建更为高效、便捷的方式用于训练视觉表征模型呢?
2021 年 OpenAI 发表的论文《Learning Transferable Visual Models From Natural Language Supervision》提出了 CLIP (Contrastive Language-Image Pre-training) 模型,并在论文中详细阐述了如何通过自然语言处理监督信号,来训练可迁移的视觉模型(其原理架构如下图所示)。
- 《Learning Transferable Visual Models From Natural Language Supervision》 https://cdn.openai.com/papers/Learning_Transferable_Visual_Models_From_Natural_Language_Supervision.pdf?trk=cndc-detail
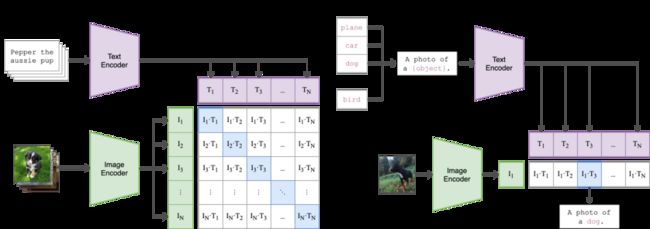
Source: GitHub - openai/CLIP: CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image
对于 CLIP,OpenAI 是在 4 亿对图像-文本对上进行训练。关于 CLIP 论文,会在下一期和其它文生图(Text-to-Image)领域的重要论文一起集中解读。以下先简单展示下论文的主要结论(如下图所示)。论文的实验经过 ImageNet 数据集的重新筛选,制作了几个变种的版本。基于 CLIP 训练出来的模型效果非常理想:

Source: GitHub - openai/CLIP: CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image
在 ImageNet 数据集上训练出来的 ResNet 101 模型准确率是 76.2%,用 CLIP 训练出来的 VIT-Large 模型准确率同样是 76.2%。然而当我们换成其它数据集,严格按照 1000 类的分类头再次训练,ResNet 101 得出的模型准确率却下降得很快。特别是使用上图中最后两行样本(素描画或者对抗性样本)时,ResNet 101 准确度仅为 25.2% 和 2.7%,基本属于随机猜测,迁移效果惨不忍睹。对比使用 CLIP 训练出来的模型,准确率仍然不错。
这说明:因为和自然语言处理的结合,所以导致 CLIP 学出来的视觉特征,和用语言所描述的某个物体,已经产生了某种强烈的联系。CLIP 这种基于文字-图像对的预训练模型对后续生成式AI的重要影响,论文的作者自己在当时都没有足够意识到,从此拉开了生成式 AI 文生图(Text-to-Image)领域波澜壮阔的大幕。
那么 CLIP 是如何训练的呢?
CLIP 是根据图像及其标题的数据集进行训练的。想象一个有 4 亿对的“图像-标题”对的数据集:

图像及其标题的数据集 Source:The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
实际上,CLIP 是根据从网络上抓取的图像以及其 “alt” 标签进行训练的。
CLIP 是图像编码器和文本编码器的组合,我们分别使用图像和文本编码器对图像本身、图像标题进行编码,如下图所示:

Source: The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
然后,我们使用余弦相似度(cosine similarity)比较生成的嵌入向量(embeddings)。当我们最初启动训练过程时,相似度可能会很低,即使文本实际上已经正确描述了图像的内容。
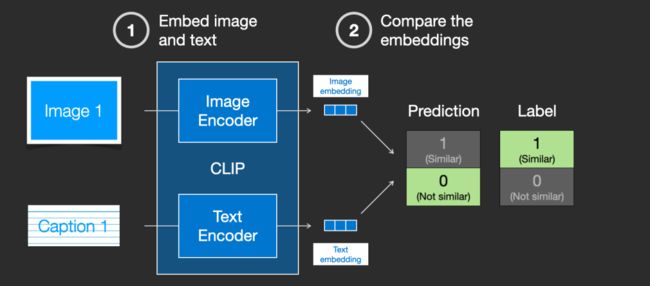
Source: The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
接下来,我们将更新这两个模型,以便下次嵌入它们时,生成的嵌入是相似的。

Source: The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
通过在数据集中重复这一点并进行大批量处理,我们最终使编码器能够生成狗的图像和 “a picture of a dog” 句子相似的嵌入向量。另外还需要考虑的是,训练过程还需要包括不匹配的图片和文本的负面示例,并且模型需要为它们分配较低的相似度分数。
OpenCLIP:CLIP 的开源实现
CLIP 使计算图像和文本的表示形式以测量它们的相似程度成为可能。CLIP 模型以自我监督的方式在数亿或数十亿图像-文本对上进行训练。例如:LAION-5B 数据集,包含 58 亿个密切相关的图像-文本对。2022 年 9 月,LAION 利用这个数据集的 OpenCLIP 项目,对 CLIP 论文完成了开源实现。
-
OpenCLIP 的 GitHub 网址:
GitHub - mlfoundations/open_clip: An open source implementation of CLIP.
LAION 使用 OpenCLIP 训练了三个大型 CLIP 模型:ViT-L/14、ViT-H/14 和 ViT-g/14(与其他模型相比,ViT-g/14 的训练周期仅为三分之一左右),并在其官方网站上称它自己是当年开源 CLIP 模型之最佳,如下图所示:
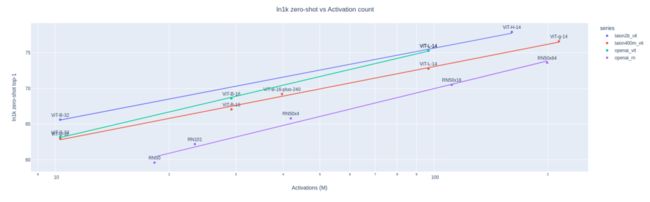
Source: Large scale openCLIP: L/14, H/14 and g/14 trained on LAION-2B | LAION
Stable Diffusion v2 版本的文本编码器就是用 OpenCLIP 训练的文生图(Text-to-Image)模型。该文本编码器由 LAION 在 Stability AI 的支持下开发,与之前的 V1 版本相比,它极大地提高了生成的图像的质量。此版本中的文生图(Text-to-Image)模型可以生成默认分辨率为 512 x 512 像素和 768 x 768 像素的图像,如下图所示:

Source: Stable Diffusion 2.0 Release — Stability AI
OpenCLIP 得以发展起来的重要原因,我觉得离不开开源这个重要话题。尽管 Open AI 的 CLIP 模型是开源的(共享了模型权重),在其包含 4 亿对图像-文本对的内部数据集上训练了许多模型变体,但没有共享用于训练的数据集。
而 OpenCLIP 这个开源实现,可以让研究人员在研究和优化模型时获得更大的透明度,这有利于生成式 AI 生态的长期健康发展。
DALL-E-2 模型概述
还记得在 2022 年 4 月,第一次读完 DALL-E-2 论文《Hierarchical Text-Conditional Image Generation with CLIP Latents》,那时的感觉是:惊为天人。只不过没想到在之后的一年里,这个文生图(Text-to-Image)领域发展得如此之快。
DALL-E-2 论文我们下集再展开分析,这次先带大家看这篇论文里结构图里面的名词,是不是有些术语我们有些熟悉呢?是的,就是 CLIP。
- 《Hierarchical Text-Conditional Image Generation with CLIP Latents》 https://arxiv.org/pdf/2204.06125.pdf?trk=cndc-detail

Source: https://arxiv.org/pdf/2204.06125.pdf?trk=cndc-detail
上图是 DALL-E-2 模型主要架构。
上部是一个 CLIP,输入为文本图像对,文本信息和图像信息分别经过文本编码器和图像编码器提取文本特征 C 和图像特征 C,文本特征 C 和图像特征 C 也是成对存在。
下方作为 DALL-E-2 主体部分,主要由 prior 和 decoder 两阶段。首先,文本信息经过文本编码器提取文本特征 D,然后 prior 根据文本信息 D 生成图像特征 D。训练过程中,图像特征 C 作为图像特征 D 的 ground truth 进行训练,也就是说训练时 DALLE2 生成的图像特征 D,会参考 CLIP 生成的对应文本的图像特征 C。最后通过一个解码器 decoder 根据图像特征 D 生成图像。
为了把 DALL-E-2 说得更加通俗易懂,我找到了这样的一张图:

Source:AIGC:新世界正在到来|真格投资人专栏
概括而言,DALL-E-2 训练了 3 个模型来完成文生图(Text-to-Image):
- CLIP 模型:负责将文本和视觉图像联系起来
- GLIDE 模型:负责从视觉的描述中产生图像
- PRIOR 模型:负责把文本描述映射到视觉描述
这里再次强调我们在第一集中,就提及的 Transformer 模型的重要性。
Transformer 模型是上面提到的三个模型的知识底座。因为首先要找出图片和文字的重点,才能够搭建 CLIP 模型,然后才有之上的 PRIOR 先验模型和 GLIDE 扩散模型。
Stable Diffusion 模型概述
1.Stable Diffusion 的组件概览
来自 Stability AI 的 Stable Diffusion 是一个由多个组件和模型组成的系统。它不是一个单一的模型。其主要组件如下图所示:

Source: The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
我们从高级视图开始,我们将在本文后面详细介绍更多细节。首先,这个文本编码器其实是一种特殊的 Transformer 语言模型(技术上:CLIP 模型的文本编码器),它接受输入文本并输出代表文本中每个单词/标记的数字列表(每个标记的向量)。
然后,该信息将呈现给图像生成器,图像生成器本身由几个组件组成。

Source: The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
图像生成器经历了两个阶段。
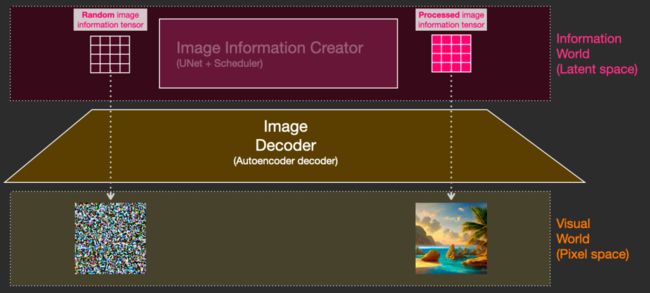
第一阶段:图像信息创建者(Image Information Creator)
这种组件是 Stable Diffusion 的秘诀。与以前的模型相比,它在性能上有很大提升。此组件运行多个步骤以生成图像信息,这是 Stable Diffusion 接口和库中的步骤参数,通常默认为 50 或 100。
图像信息创建者完全在图像信息空间中工作,这个空间还有一个更学术的词:潜在空间(latent space)。此特性使其比以前在像素空间中运行的扩散模型(Diffusion Models)更快。用技术术语来说,这个组件由一个 UNet 神经网络和一个调度算法(scheduling algorithm) 组成。
“扩散”(diffusion) 一词形象地描述了该组件的作用,即对信息的分步处理。最终将由下一个组件图像解码器(image decoder),去生成高质量的图像。

Source: The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
第二阶段:图像解码器(Image Decoder)
图像解码器根据从信息创建者那里获得的信息来绘制图片,如下图所示:

Source: The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
接下来,我们来看看构成稳定扩散的三个主要组成部分(每个组成部分都有自己的神经网络):
-
ClipText:用于文本编码
输入: 文字/文本
输出: 77 个 token 嵌入向量(embeddings vectors),每个向量的维度为 768
-
UNet + Scheduler:逐步处理/扩散信息(潜在)空间的信息
输入: 文本嵌入(text embeddings)信息,和由噪声组成的起始多维数组(数字的结构化列表,也称为张量 tensor )
输出: 经过处理的信息数组
-
Autoencoder Decoder:使用处理后的信息数组绘制最终图像
输入: 处理后的信息数组(维度:(4,64,64))
输出: 生成的图像 (维度: (3, 512, 512) which are (红/绿/蓝, 宽 ,高)

Source: The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
2.扩散(Diffusion)概览
写到这里,可能有读者会问:在 Stable Diffusion 中提及的扩散(Diffusion),到底是什么呢?
扩散是发生在粉红色 “图像信息创建器” 组件内部的过程,如下图所示:
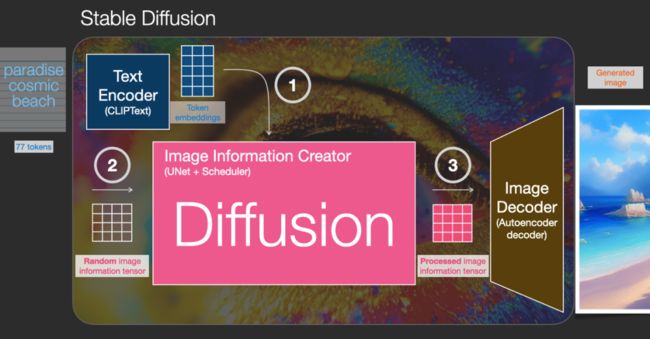
Source: The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
通过使用表示输入文本的标记嵌入和随机的起始图像信息数组(image information array),也称为潜在数组(latents)。该过程会生成一个信息数组,图像解码器使用该数组来绘制最终图像。
这个过程是分步进行的,每个步骤都会添加更多相关信息。为了直观地了解这个过程,我们可以检查随机潜在数组(random latents array),看看它是否会转化为视觉噪声(visual noise)。在这种情况下,视觉检查是通过图像解码器(image decoder)进行的,如下图所示:
Source: The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
扩散分多个步骤进行,每个步骤都对一个输入潜在数组(latents array)进行操作,然后生成另一个潜在数组,该数组希望更相似于输入文本和从模型训练的所有图像中获得的视觉信息,如下图所示:

Source: The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
我们可以将其中一组潜在数组可视化,以查看在每个步骤中添加了哪些信息。

Source: The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
关于 Diffusion Model 背后的工作原理,会涉及到一系列的论文研究成果,比如:DDPM、DDIM、Stable Diffusion 的论文等,我们会在下一篇的论文解读专题中做详细探讨。
![]()
本期文章,我们开始探讨生成式 AI(Generative AI)的另一个进步迅速的领域:文生图(Text-to-Image)领域。本期简述了 CLIP、OpenCLIP、扩散模型、DALL-E-2 模型、Stable Diffusion 模型等基本内容,希望读者对接下来对我们详细解读相关论文,以及最后进行文生图(Text-to-Image)领域的动手实验,有一个原理上的初步了解和基础知识储备。
下一期内容将进行文生图(Text-to-Image)方向的主要论文解读,敬请期待。
请持续关注 Build On Cloud 微信公众号,了解更多面向开发者的技术分享和云开发动态!
往期推荐
#机器学习洞察
#开发者生态
#亚马逊的开源文化

作者黄浩文
亚马逊云科技资深开发者布道师,专注于 AI/ML、Data Science 等。拥有 20 多年电信、移动互联网以及云计算等行业架构设计、技术及创业管理等丰富经验,曾就职于 Microsoft、Sun Microsystems、中国电信等企业,专注为游戏、电商、媒体和广告等企业客户提供 AI/ML、数据分析和企业数字化转型等解决方案咨询服务。
文章来源:https://dev.amazoncloud.cn/column/article/645c5c3f4b2abb2a7506e229?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN