10个最流行的可生成图像嵌入向量的预训练AI模型
迁移学习的出现进一步加速了计算机视觉——图像分类用例的快速发展。 在大型图像数据集上训练计算机视觉神经网络模型需要大量的计算资源和时间。
幸运的是,通过使用预训练模型可以缩短时间和资源。 利用预训练模型的特征表示的技术称为迁移学习。 预训练通常使用高端计算资源和海量数据集进行训练。
可以通过多种方式使用预训练模型:
- 使用预训练的权重,直接对测试数据进行预测
- 使用预训练的权重进行初始化并使用自定义数据集训练模型
- 仅使用预训练网络的架构,并在自定义数据集上从头开始训练
本文介绍了前 10 个最先进的预训练模型以获得图像嵌入。 所有这些预训练模型都可以使用 keras.application API 作为 keras 模型加载。
推荐:用 NSDT设计器 快速搭建可编程3D场景。
1、VGG
VGG-16/19 网络是在 ILSVRC 2014 会议上推出的,因为它是最受欢迎的预训练模型之一。 它是由牛津大学的视觉图形组开发的。
VGG模型有两种变体:16层和19层网络,VGG-19(19层网络)是VGG-16(16层网络)模型的改进。
1.1 VGG的架构
VGG 网络本质上是简单且顺序的,并且使用了很多过滤器。 在每个阶段,使用小型 (3*3) 过滤器来减少参数数量。

VGG-16 网络具有以下内容:
- 卷积层 = 13
- 池化层 = 5
- 完全连接的密集层 = 3
输入:图像维度 (224, 224, 3)
输出:1000维的图像嵌入
VGG-16/19 的其他详细信息:
- 论文链接:arxiv
- GitHub:VGG
- 发表于:2015 年 4 月
- ImageNet 数据集上的性能:71%(前 1 准确度),90%(前 5 准确度)
- 参数数量:~140M
- 层数:16/19
- 磁盘大小:~530MB
1.2 使用VGG
对你的输入数据调用 tf.keras.applications.vgg16.preprocess_input 以将输入图像转换为每个颜色通道的零中心 BGR。
使用下面提到的代码实例化 VGG16 模型:
tf.keras.applications.VGG16(
include_top=True,
weights="imagenet",
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
classifier_activation="softmax",
)
上述代码是针对VGG-16的实现,keras为VGG-19的实现提供了类似的API,更多细节请参考此文档。
2、Xception
Xception 是一种深度 CNN 架构,涉及深度可分离卷积。 depthwise separable convolution 可以理解为具有最大塔数的 Inception 模型。
2.1 Xception架构

输入:图像维度 (299, 299, 3)
输出:1000维的图像嵌入
Xception 的其他详细信息:
- 论文链接:arxiv
- GitHub:Xception
- 发表于:2017 年 4 月
- ImageNet 数据集上的性能:79%(前 1 准确度),94.5%(前 5 准确度)
- 参数数量:~30M
- 深度:81
- 磁盘大小:88MB
2.2 使用Xception
使用下面提到的代码实例化 Xception 模型:
tf.keras.applications.Xception(
include_top=True,
weights="imagenet",
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
classifier_activation="softmax",
)
以上代码为Xception的实现,更多细节请参考此文档。
3、ResNet
以前的 CNN 架构并不是为了扩展到许多卷积层而设计的。 在向现有架构添加新层时,它会导致消失的梯度问题和有限的性能。
ResNets 架构提供跳过连接来解决梯度消失问题。
3.1 ResNet架构

此 ResNet 模型使用 34 层网络架构,其灵感来自于添加了快捷连接的 VGG-19 模型。 然后,这些快捷连接将架构转换为残差网络。
ResNet架构有几个版本:
- ResNet50
- ResNet50V2
- ResNet101
- ResNet101V2
- ResNet152
- ResNet152V2
输入:图像维度 (224, 224, 3)
输出:1000维的图像嵌入
ResNet 模型的其他详细信息:
- 论文链接:arxiv
- GitHub:ResNet
- 发表于:2015 年 12 月
- ImageNet 数据集上的性能:75–78%(前 1 准确率),92–93%(前 5 准确率)
- 参数数量:25-60M
- 深度:107–307
- 磁盘大小:~100–230MB
3.2 使用ResNet
使用下面提到的代码实例化 ResNet50 模型:
tf.keras.applications.ResNet50(
include_top=True,
weights="imagenet",
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
**kwargs
)
上述代码是针对 ResNet50 实现的,keras 提供了与其他 ResNet 架构实现类似的 API,更多详细信息请参阅此文档。
4、Inception
多个深层卷积导致数据过拟合。 为了避免过度拟合,初始模型在同一层上使用平行层或多个不同大小的过滤器,以使模型更宽而不是更深。 Inception V1 模型由 4 个平行层组成:(11)、(33)、(55) 卷积和 (33) 最大池化。
Inception (V1/V2/V3) 是由谷歌团队开发的基于深度学习模型的 CNN 网络。 InceptionV3 是 InceptionV1 和 V2 模型的高级优化版本。
4.1 Inception架构
InceptionV3 模型由 42 层组成。 InceptionV3的架构是逐步逐步构建的:
- 分解卷积
- 更小的卷积
- 不对称卷积
- 辅助卷积
- 网格尺寸减小
所有这些概念都整合到下面提到的最终架构中:

输入:图像维度(299, 299, 3)
输出:1000维的图像嵌入
InceptionV3 模型的其他详细信息:
- 论文链接:arxiv
- GitHub:InceptionV3
- 发表于:2015 年 12 月
- ImageNet 数据集上的性能:78%(前 1 准确度),94%(前 5 准确度)
- 参数数量:24M
- 深度:189
- 磁盘大小:92MB
4.2 使用Inception
使用下面提到的代码实例化 InceptionV3 模型:
tf.keras.applications.InceptionV3(
include_top=True,
weights="imagenet",
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
classifier_activation="softmax",
)
以上代码为InceptionV3实现,更多细节请参考此文档。
5、InceptionResNet
InceptionResNet-v2 是谷歌研究人员开发的 CNN 模型。 该模型的目标是降低InceptionV3的复杂度,探索在Inception模型上使用残差网络的可能性。
5.1 InceptionResNet架构
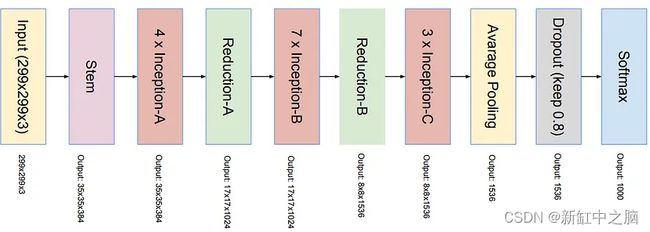
输入:图像维度 (299, 299, 3)
输出:1000维的图像嵌入
Inception-ResNet-V2 模型的其他详细信息:
- 论文链接:arxiv
- GitHub:Inception-ResNet-V2
- 发表于:2016 年 8 月
- ImageNet 数据集上的性能:80%(前 1 准确度),95%(前 5 准确度)
- 参数数量:56M
- 深度:189
- 磁盘大小:215MB
5.2 使用InceptionResNet
使用下面提到的代码实例化 Inception-ResNet-V2 模型:
tf.keras.applications.InceptionResNetV2(
include_top=True,
weights="imagenet",
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
classifier_activation="softmax",
**kwargs
)
以上代码为Inception-ResNet-V2的实现,更多细节请参考此文档。
6、MobileNet
MobileNet 是一种流线型架构,它使用深度可分离卷积构建深度卷积神经网络,并为移动和嵌入式视觉应用程序提供高效模型。
6.1 MobileNet架构

输入:图像维度 (224, 224, 3)
输出:1000维的图像嵌入
MobileNet 模型的其他详细信息:
- 论文链接:arxiv
- GitHub: MobileNet-V3, MobileNet-V2
- 发表于:2017 年 4 月
- ImageNet 数据集上的性能:71%(前 1 准确度),90%(前 5 准确度)
- 参数数量:3.5–4.3M
- 深度:55–105
- 磁盘大小:14–16MB
6.2 使用MobileNet
使用下面提到的代码实例化 MobileNet 模型:
tf.keras.applications.MobileNet(
input_shape=None,
alpha=1.0,
depth_multiplier=1,
dropout=0.001,
include_top=True,
weights="imagenet",
input_tensor=None,
pooling=None,
classes=1000,
classifier_activation="softmax",
**kwargs
)
上述代码是针对MobileNet的实现,keras为其他MobileNet架构(MobileNet-V2、MobileNet-V3)的实现提供了类似的API,更多细节请参考此文档。
7、DenseNet
DenseNet 是一种 CNN 模型,旨在提高高级神经网络中由于输入层和输出层之间的距离较长而导致的梯度消失以及信息在到达目的地之前消失而导致的准确性。
7.1 DenseNet架构
DenseNet 架构有 3 个密集块。 两个相邻块之间的层称为过渡层,并通过卷积和池化改变特征图大小。

输入:图像维度 (224, 224, 3)
输出:1000维的图像嵌入
DenseNet 模型的其他详细信息:
- 论文链接:arxiv
- GitHub:DenseNet-169、DenseNet-201、DenseNet-264
- 发表于:2018 年 1 月
- ImageNet 数据集上的性能:75–77%(前 1 准确率),92–94%(前 5 准确率)
- 参数数量:8-20M
- 深度:240–400
- 磁盘大小:33–80MB
7.2 使用DenseNet
使用下面提到的代码实例化 DenseNet121 模型:
tf.keras.applications.DenseNet121(
include_top=True,
weights="imagenet",
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
classifier_activation="softmax",
)
上述代码是针对DenseNet的实现,keras为其他DenseNet架构(DenseNet-169、DenseNet-201)的实现提供了类似的API,更多细节请参考此文档。
8、NasNet
谷歌研究人员设计了一个 NasNet 模型,该模型将问题框定为寻找最佳 CNN 架构作为强化学习方法。 这个想法是在给定的层数、过滤器大小、步幅、输出通道等的给定搜索空间中搜索参数的最佳组合。
8.1 NasNet架构
输入:维度图像 (331, 331, 3)
NasNet 模型的其他详细信息:
- 论文链接:arxiv
- 发表于:2018 年 4 月
- ImageNet 数据集上的性能:75–83%(前 1 准确率),92–96%(前 5 准确率)
- 参数数量:5–90M
- 深度:389–533
- 磁盘大小:23–343MB
8.2 使用NasNet
使用下面提到的代码实例化 NesNetLarge 模型:
tf.keras.applications.NASNetLarge(
input_shape=None,
include_top=True,
weights="imagenet",
input_tensor=None,
pooling=None,
classes=1000,
classifier_activation="softmax",
)
上述代码是针对NesNet的实现,keras提供了类似的API来实现其他NasNet架构(NasNetLarge、NasNetMobile),更多细节请参考此文档。
9、EfficientNet
EfficientNet 是来自谷歌研究人员的 CNN 架构,它可以通过一种称为复合缩放的缩放方法获得更好的性能。 这种缩放方法将深度/宽度/分辨率的所有维度统一缩放一个固定的量(复合系数)。
9.1 EfficientNet架构

EfficientNet 模型的其他详细信息:
- 论文链接:arxiv
- GitHub:EfficientNet
- 发表于:2020 年 9 月
- ImageNet 数据集上的性能:77–84%(前 1 准确率),93–97%(前 5 准确率)
- 参数数量:5–67M
- 深度:132–438
- 磁盘大小:29–256MB
9.2 使用EfficientNet
使用下面提到的代码实例化 EfficientNet-B0 模型:
tf.keras.applications.EfficientNetB0(
include_top=True,
weights="imagenet",
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
classifier_activation="softmax",
**kwargs
)
上述代码是针对EfficientNet-B0的实现,keras为其他EfficientNet架构(EfficientNet-B0到B7,EfficientNet-V2-B0到B3)的实现提供了类似的API,更多细节参考文档1以及文档2。
10、ConvNeXt
ConvNeXt CNN 模型是作为纯卷积模型 (ConvNet) 提出的,其灵感来自 Vision Transformers 的设计,声称其性能优于它们。
10.1 ConvNeXt架构
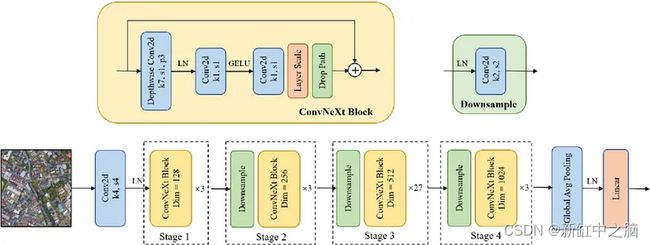
ConvNeXt 模型的其他详细信息:
- 论文链接:arxiv
- GitHub:ConvNeXt
- 发表于:2022 年 3 月
- ImageNet 数据集上的性能:81–87%(准确率前 1)
- 参数数量:29–350M
- 磁盘大小:110–1310MB
10.2 使用ConvNeXt
使用下面提到的代码实例化 ConvNeXt-Tiny 模型:
tf.keras.applications.ConvNeXtTiny(
model_name="convnext_tiny",
include_top=True,
include_preprocessing=True,
weights="imagenet",
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
classifier_activation="softmax",
)
上述代码是针对ConvNeXt-Tiny的实现,keras提供了其他EfficientNet架构(ConvNeXt-Small、ConvNeXt-Base、ConvNeXt-Large、ConvNeXt-XLarge)实现的类似API,更多细节请参考此文档。
11、结束语
本文讨论了 10 种流行的 CNN 架构,它们可以使用迁移学习生成嵌入。 这些预训练的 CNN 模型已经超越了 ImageNet 数据集,并被证明是最好的。 Keras 库提供 API 来加载所讨论的预训练模型的架构和权重。 从这些模型生成的图像嵌入可用于各种用例。
然而,这是一个不断发展的领域,总有一种新的 CNN 架构值得期待。
原文链接:TOP10图像嵌入预训练模型 — BimAnt