RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs
article: Michael Niemeyer等, 《RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs》 (CVPR 2022), https://doi.org/10.48550/arXiv.2112.00724.
code:https://github.com/google-research/google-research/tree/master/regnerf
author units: Max Planck Institute for Intelligent Systems, Google research
摘要
nerf因其简单性和SOTA的表现已成为新视图合成任务的有力代表。
NeRF的输入为多个视图的图片时,能够生成新的相机视角的照片级真实感的渲染图片,但当输入视图变少时,性能会显著下降。在现实世界的应用场景,比如AR/VR、自动驾驶、机器人等,这些场景下能获取到的输入通常是稀疏的,每个场景只有很少的视图(关于特定对象或部分区域的视图),在这些场景下,NeRF渲染得到的新视图的质量显著下降,如下图。
RegNerf的作者分析认为,在稀疏输入场景中出现的大部分伪影主要是由两个原因导致的:
- 场景几何估计错误
- 训练开始时的发散行为
针对上述问题,RegNerf提出以下改进措施:
- 对从未观察到的viewpoint渲染的patches的几何形状和外观进行正则化(regularizing)
- 在训练过程中对射线采样空间进行退火(annealing)
- 使用归一化流模型(normalizing flow model)来正则化未观察到的viewpoint的颜色
1 Introduction
针对NeRF在稀疏场景下性能显著下降的问题,一些工作 [如MVSNeRF,SRF,pixelNeRF]提出了条件模型来克服这些限制。这些模型需要在具有多视图图像和相机姿势注释的许多场景的大规模数据集上训练模型,而不是针对给定测试场景从头开始进行测试时间优化,这样的预训练代价也是比较昂贵的。
上述这些模型在大数据集上完成预训练后,在泛化或者测试新场景时,就无需重新训练,而是可以通过摊销推理(amortized inference)仅从少量输入图像生成新颖的视图,结合每个场景进行短时间的微调,就可以得到比那些对这个场景重新进行训练的模型更为锐利,更有细节的效果。虽然这些改进的模型取得了一定的效果,但要先在包含多场景的大数据集进行预训练的代价是昂贵的,而且这些模型可能不能很好地泛化到新视图上,同时由于稀疏输入数据固有的模糊性,这些模型渲染得到的新视图也会出现模糊。
:::info
包含不同场景的多视图图像数据集并不总是现成的,而且获取成本可能很高;除此之外,尽管预训练时间比较长,但大多数方法在测试时都要经过一段时间的微调,且当测试数据域发生变化(可能类别和训练时的不一致),生成的新视图的质量容易下降。
:::
RegNerf这篇文章提出了一种用于正则化稀疏输入场景的NeRF模型的新方法。主要贡献有以下几点:
- 使用一个patch-based的正则化器,用于正则化从未观察到的视点渲染的patches的几何和外观,以此避免了昂贵的预训练过程
:::info
此前在正则化这个方向上的工作有DS-NeRF和Diet-NeRF。
DS-NeRF通过增加额外的深度监督来提高重建精度。相比之下,RegNeRF只使用RGB图像,不需要深度输入。
DietNeRF 比较了以低分辨率呈现的未观察到的viewpoint的CLIP嵌入。这种语义一致性损失只能提供高级信息,而不能改善稀疏输入的场景几何形状。相反,RegNeRF正则化渲染的patch的场景几何和外观,并应用场景空间退火策略。
经过实验,作者发现RegNerf可以获得更逼真的场景几何和更准确的新视图。
:::
- 使用了一个归一化流(normalizing flow model)模型,通过最大化渲染patches的对数似然,从而避免不同视图之间的颜色转移,来规范化在未见视点预测的颜色。
- 沿着射线采样点的退火策略,在扩展到整个场景边界之前,首先在小范围内对场景内容进行采样,这有效地防止了训练期间早期的发散。
3 整体模块设计
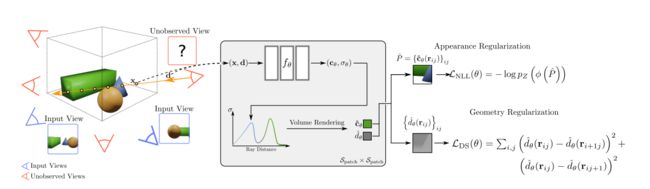
整体思路:基于已观察到的相机的viewpoint(蓝色相机),给出所有相机可能位置的边界框,然后定义未观察到的viewpoint(红色相机)(这些视图是输入图像中没有的,但是可以根据相机位置集合采样得到),从未观察到的视图投射光线,并采样(红色射线)这些射线上的点,把射线上采样得到的点喂入神经辐射场 f θ f_{\theta} fθ,渲染得到 颜色和密度,采样了一条射线上的多个点,对这些所有的点再做一个 alpha-composting (alpha 叠加),得到一个pixel对应的颜色和密度,因为对未观测的视图采样的是一个patch,对patch中的每一个像素重复上述操作,得到一个预测的RGB 颜色的patch P ^ \hat{P} P^和一个depth patch d ^ θ \hat{d}_\theta d^θ,然后对rgb patch进行外观正则化,depth patch进行场景几何正则化。外观正则化的思想是估计渲染得到的patch的颜色的可能性(本来是最大化对数似然,这里取负之后就变成了最小化负对数似然), ϕ \phi ϕ是在JFT-300M数据集的patches上训练的RealNVP归一化流模型,这个数据集是一个非结构化的2D数据集,这样 ϕ \phi ϕ就能被用在任意形式的场景下。场景几何正则化的做法是强行给渲染的depth patches加上一个深度平滑先验,作者说这样有助于减少 float artifacts (这个的意思可能是减少伪影?)且使得即使是稀疏的输入视图也能获得更真实的场景几何。
RegNerf是基于mip-nerf的基础上进行的改进,先简单介绍下nerf和mip-nerf的知识。
3.1 nerf 和 mip-nerf
3.1.1 nerf
nerf通俗来讲就是构造一个隐式的渲染流程,其输入是某个视角下发射的光线的位置o,方向d以及对应的坐标(x,y,z),送入神经辐射场Fθ得到体密度和颜色,最后再通过体渲染得到最终的图像。
Neural radiance fields
Volume Rendering
在有了3D空间的模型以后(即神经辐射场 f θ f_{\theta} fθ),需要以神经辐射场为中间载体合成图像,这个过程就是渲染。Nerf使用Volume Rendering的方法来做渲染。具体过程为,假设当前相机光心的位置为 o ∈ R 3 o\in R^3 o∈R3,将图像上任意像素与光心连线,可得到视角方向 d ∈ R 3 d \in R^3 d∈R3,根据光心及视角方向可得到一条光线 r ( t ) = o + t d r(t)=o+td r(t)=o+td,根据体渲染公式,按照如下流程,得到该像素上观测到的颜色

对上述公式进行离散近似,即可完成体渲染的过程。到此为止,用已观测到的图像作为监督,选择一个 MSE loss function,就可以开始训练了。
3.1.2 Mip-nerf
:::info
Mip-NeRF提出的背景:nerf在NeRF在每个pixel用single ray来sample场景,这种方法在渲染过程中,只对相机位置固定、改变观察方向的视角生成上表现较好,如果拉近或者拉远图像,(NeRF在做渲染时)会出现模糊(blurred)和锯齿(aliased)的情况。这种情况通常由于输入的同一个场景对应的多个图片清晰度(resolution)不一致而导致的。
补充:锯齿产生的本质是采样频率低于真实原始信号的频率,即信号处理中的“混叠”现象(可参考:)。解决锯齿有两种方法:一是尽可能提高采样率,如图形学中抗锯齿用到的SSAA/MSAA;二是尽可能去除高频分量,如使用低通滤波器对边缘进行模糊处理。
mip-nerf的思路是:nerf对每个pixel只发射single ray,如果每个pixel下用multiple rays,提高采样率,在一定程度上能够解决锯齿化的问题。但是对NeRF来说并不现实;因为沿着一条ray渲染就需要querying一个MLP几百次,计算量大增且效率低下。于是mip-nerf提出了用圆锥体取代光线的方案。如下图所示。
:::

mip-nerf相对于nerf而言主要有两个改进:
- 用圆锥取代光线
- 把nerf的coarse和fine这两个MLP用一个multiscale MLP替代,从而提高训练速度并减小模型大小。
当用圆锥体表示后,采样的就不再是离散的点集,而是一个连续的圆锥横截面(conical frustum),这能够解决NeRF中忽略了光线观察范围体积与大小的问题。对应的区域表示为:
此时positional encoding也相应地转化为积分形式:
3.2 patch-based Regularization
:::info
作者在这首先回顾了为什么输入视图的数量是稀疏的会导致NeRF的性能显著下降?
:::
NeRF仅仅从稀疏的输入视图中受到上面的(3)式中重建损失函数的监督,虽然它可以学会完美地重建输入视图,但对于新视图可能会退化,因为在这种稀疏的输入场景中,模型没有偏向于学习3D一致性的解决方案。
为了解决上述问题,RegNerf对没有观察到的相机视点进行正则化。具体而言,RegNerf定义了一个没有观察到但和已有的viewpoint相关的viewpoint 空间,并渲染从这些viewpoint随机采样的patch。
论文的主要想法是这些patch可以正则化,以产生平滑的几何图形和high-likelihood的颜色。
unobserved viewpoint selection
要把正则化应用到未观察到的viewpoint上,首先必须定义一个未观测相机pose的样本空间,先假设一组已知的目标姿态 { P t a r g e t i } \{P^i_{target}\} {Ptargeti},其中:
这些target pose可以被认为是希望在测试时从中渲染新视图的pose的集合的边界。作者将可能的相机位置的空间定义为所有已给定的目标相机位置的边界框:![]()
其中, t m i n 和 t m a x t_{min}和t_{max} tmin和tmax分别是 { t t a r g e t i } i \{t^i_{target}\}_i {ttargeti}i中元素的最小值和最大值。
[R|t]的含义?
https://www.jianshu.com/p/2341da36aa8e
SE(3) 特殊欧式群
李群 的介绍 参考:https://zhuanlan.zhihu.com/p/460985235
简单理解为R是33正交阵且行列式为1,t 是31平移阵

为了获得相机旋转的采样空间,作者假设所有相机大致聚焦在中心场景点上。通过计算所有target pose的上轴上的归一化平均值来定义一个共同的“上”轴 P ˉ u \bar{P}_u Pˉu。然后,通过求解最小二乘问题来计算平均焦点 P ˉ f \bar{P}_f Pˉf,以确定到所有目标姿态的光轴具有最小平方距离的3D点。为了学习更稳健的表示,在计算相机旋转矩阵之前向焦点添加随机抖动。作者将所有可能的相机旋转的集合(给定采样位置t)定义为:![]()
其中 R ( ⋅ , ⋅ , ⋅ ) R(·,·,·) R(⋅,⋅,⋅)表示由此产生的“look-at”相机旋转矩阵(聚焦在中心场景点的相机), ϵ \epsilon ϵ是添加到焦点的小抖动,服从均值为0,方差为0.0125的正态分布。 通过对位置和旋转进行采样来获得随机camera pose:
Geometry Regularization
一个普遍认可的事实是,现实世界的几何结构往往是分段平滑的,即平面结构比高频结构更可能。
:::info
图像的低频、高频信息是什么?
:::
低频就是颜色缓慢地变化,也就是灰度缓慢地变化,就代表着那是连续渐变的一块区域,这部分就是低频. 对于一幅图像来说,除去高频的就是低频了,也就是边缘以内的内容为低频,而边缘内的内容就是图像的大部分信息,即图像的大致概貌和轮廓,是图像的近似信息。
高频就是频率变化快.图像中什么时候灰度变化快?就是相邻区域之间灰度相差很大,这就是变化得快.图像中,一个影像与背景的边缘部位,通常会有明显的差别,也就是说变化那条边线那里,灰度变化很快,也即是变化频率高的部位.因此,图像边缘的灰度值变化快,就对应着频率高,即高频显示图像边缘。图像的细节处也是属于灰度值急剧变化的区域,正是因为灰度值的急剧变化,才会出现细节。
如下图,1所处位置即为低频区域,2所处位置即为高频区

作者从未观察到的viewpoint鼓励 depth smoothness,并把这一先验知识纳入模型中,类似于(2)中像素颜色的渲染公式,深度的计算公式为(仿照nerf):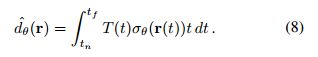
深度平滑损失公式为:
其中, R r R_r Rr表示从相机姿势 S P S_P SP采样的一组光线, r i j r_{ij} rij是从像素 ( i , j ) (i,j) (i,j)穿过以 r r r为中心的patch的光线, S p a t c h S_{patch} Spatch是被渲染的patch的大小。
Color Regularization
作者提到,对于稀疏输入,大多数伪影是由不正确的场景几何体引起的。然而,即使具有正确的几何结构,由于输入的稀疏性,优化NeRF模型仍然可能导致场景外观预测中的颜色偏移或其他错误。为了避免退化的颜色并确保稳定的优化,Regnerf还对颜色预测进行了正则化。其关键思想是estimate the likelihood of rendered patches(估计被渲染的patch的可能性),并在优化过程中最大化它。为此,文中利用了现成的非结构化2D图像数据集。
结构化数据也被成为定量数据,是能够用数据或统一的结构加以表示的信息,如数字、符号。典型的结构化数据包括:信用卡号码、日期、财务金额、电话号码、地址、产品名称等。
非结构化数据是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。包括所有格式的办公文档、文本、图片, HTML、各类报表、图像和音频/视频信息等等。
尽管姿态多视图图像的数据集收集起来需要花费极大的代价,但非结构化自然图像的集合却很丰富,文中对数据集的唯一标准是,它包含不同的自然图像,使得能够对重建的任何类型的真实世界场景重复使用相同的流模型。
论文在JFT-300M数据集的patches上训练RealNVP归一化流模型。使用这个训练的流模型,估计渲染的patches的对数似然性(LL),并在优化过程中使其最大化。![]() 是将大小为 S p a t c h = 8 S_{patch}=8 Spatch=8的patch映射到 R d R^d Rd, d = S p a t c h ⋅ S p a t c h ⋅ 3 d=S_{patch}\cdot S_{patch} \cdot 3 d=Spatch⋅Spatch⋅3的学习双射(learned bijection)
是将大小为 S p a t c h = 8 S_{patch}=8 Spatch=8的patch映射到 R d R^d Rd, d = S p a t c h ⋅ S p a t c h ⋅ 3 d=S_{patch}\cdot S_{patch} \cdot 3 d=Spatch⋅Spatch⋅3的学习双射(learned bijection)
bijection:双射映射:如果一个集合的每个元素只与第二个集合的一个元素配对,并且第二个集合的每个元素只与第一个集合的一个元素配对,则函数对于两个集合是双射的。这意味着所有元素都配对且配对一次。参考:https://brilliant.org/wiki/bijection-injection-and-surjection/
定义颜色正则化损失为:
R r R_r Rr表示从 S P S_P SP采样的一组射线,其中, P ^ r \hat{P}_r P^r是预测的RGB 颜色的patch,它 以 r r r为中心, − l o g p Z −log p_Z −logpZ表示高斯 p Z p_Z pZ的负对数似然(“NLL”)。
Total Loss
每次迭代中优化的总损失函数为:![]()
其中 R i R_i Ri表示来自输入poses的一组射线, R r R_r Rr表示来自随机pose S P S_P SP的一组射线
总的损失函数就是nerf原本的MSE loss + geometry regularization loss + color regularization loss
文中这三个损失的权重分别是 1,0.1,10^-6,同时为了训练更稳健,把深度平滑损失的权重在前512个优化步骤中从400退火到0.1
3.3 采样空间退火
对于非常稀疏的场景(例如,3或6个输入视图),作者发现导致nerf效果不好的另一个原因是:训练开始时的发散行为。这会导致光线原点处的密度值较高。当输入视图被正确重建时,由于没有恢复3D一致性表示,新视图会退化。在优化过程中,通过早期迭代对采样场景空间进行快速退火有助于避免这个问题。通过将场景采样空间限制在为所有输入图像定义的较小区域,作者引入了归纳偏差来解释场景中心具有几何结构的输入图像。
退火算法:为了解决局部最优解问题, 1983年,Kirkpatrick等提出了模拟退火算法(SA)能有效的解决局部最优解问题。模拟退火算法包含两个部分即Metropolis算法和退火过程。Metropolis算法就是如何在局部最优解的情况下让其跳出来,是退火的基础。1953年Metropolis提出重要性采样方法,即以概率来接受新状态,而不是使用完全确定的规则,称为Metropolis准则,计算量较低。参考:https://blog.csdn.net/weixin_42398658/article/details/84031235
回顾公式(2)(原始nerf的颜色渲染公式), t n , t f t_n,t_f tn,tf分别是相机的近平面和远平面,并让 t m t_m tm是定义的中心点(通常是 t n 和 t f t_n和t_f tn和tf之间的中点)。定义:
其中, i i i表示当前训练迭代, N t N_t Nt表示迭代次数,直到达到全范围, p s p_s ps表示开始范围(例如0.5)。此退火应用于来自输入pose和采样的未观的viewpoint的渲染。作者发现,这种退火策略确保了早期训练期间的稳定性,并避免了退化解。
场景采样空间在3/6个输入视图的第一次迭代中进行退火。具体而言,在最初的Nt=256次迭代中对采样空间进行线性退火,从tn和tf之间的中间点tm开始,初始范围为ps=0.5。而对于使用NDC射线参数化的LLFF数据集,使用512步,从远处的平面tm = tf开始,初始范围ps = 0.0001。
疑问:如果设置ps=0.5,根据上面计算公式,从0.5到1这段貌似也没起作用
3.4 训练细节
regnerf是在mip-nerf的基础上构建regnerf的代码,使用的是JAX框架
JAX是什么?
简单的说就是GPU加速、支持自动微分(autodiff)的numpy。
JAX的主要出发点就是将numpy的以上优势与硬件加速结合。现在已经开源的JAX ( https://github.com/google/jax) 就是通过GPU (CUDA)来实现硬件加速。
优化器:Adam,使用 2 ⋅ 1 0 − 3 t o 2 ⋅ 1 0 − 5 2 \cdot 10^{-3} to 2\cdot 10^{-5} 2⋅10−3to2⋅10−5的指数学习率衰减
基于深度学习的优化和推理是导致高能耗的计算密集型过程。为了遏制不必要的能源使用,文中使用了上述较大的学习率来减少优化时间。在几次迭代中找到最佳权重会是进一步解决该问题的可探索的一个方向。
神经辐射场被参数化为一个具有8层且隐藏层维度为256的全连接的ReLU网络。
对于3/6/9个输入视图的每一条射线,都沿射线采样128个点
按0.1的值剪裁梯度,然后按0.1的范数剪裁梯度。(We clip gradients by value at 0.1 and then by norm at 0.1.)
论文训练500个像素的epoches,batch-size为4096,在DTU上分别针对3/6/9的输入视图进行44K、88K、132K次迭代,但都少于mip-nerf默认的250K迭代次数。
4 实验
- 数据集
两个真实世界多视图数据集:
DTU:包含放置在桌子上的物体的图像;
LLFF:包含复杂的前向场景。
- 评价指标
PSNR (Peak Signal-to-Noise Ratio) 峰值信噪比

结构相似性指数(SSIM)

(Learned Perceptual Image Patch Similarity, LPIPS)也称为“感知损失”(perceptual loss)
用于度量两张图像之间的差别。来源于CVPR2018的一篇论文《The Unreasonable Effectiveness of Deep Features as a Perceptual Metric》,该度量标准学习生成图像到Ground Truth的反向映射强制生成器学习从假图像中重构真实图像的反向映射,并优先处理它们之间的感知相似度。LPIPS 比传统方法(比如L2/PSNR, SSIM, FSIM)更符合人类的感知情况。LPIPS的值越低表示两张图像越相似,反之,则差异越大。
给定Ground Truth图像参照块x和含噪声图像失真块x0,感知相似度度量公式如下:
其中,d为 x0与x之间的距离。从L层提取特征堆(feature stack)并在通道维度中进行单位规格化(unit-normalize)。利用向量 w l ∈ R C l w_l \in R^{C_l} wl∈RCl 来放缩激活通道数,最终计算L2距离。最后在空间上平均,在通道上求和。

为了便于比较,还使用了 M S E = 1 0 − P S N R / 10 MSE=10^{-PSNR/10} MSE=10−PSNR/10, 1 − S S I M \sqrt{1-SSIM} 1−SSIM,以及 LPIPS的平均值
- Baselines
与当时最先进的PixelNeRF、SRF、MVSNeRF进行比较

4.3 消融实验


上表3 中作者对文中提出的各种方法进行了消融实验,对于稀疏的输入视图,场景空间退火策略以及几何正则化都发挥了重要作用,相比之下,外观正则化的效果几乎没有,感觉这个就是作者为了创新点凑出来的一个方法。
表4展示了作者研究的其他几何正则化技术的性能,发现自己提出的方法是最好的。