【知识图谱搭建到应用】--知识存储--04
文章目录
- Mysql+jena+fuseki
-
- 数据存储
- 数据建模
- 数据映射
- 注意事项
- py2neo+neo4j
-
- Py2neo与Neo4j的版本问题
- Py2neo导入三元组数据
- 批量导入csv文件
- rdflib库
前面几篇在讲述骗理论的内容,本片主要描述如何将清洗过的结构化数据存储在转换成三元组并存储起来,并于后续使用。
Mysql+jena+fuseki
数据存储
对于清洗后的结构化数据都会存储在Mysql等关系型数据库中,一张表相当于一个类,一列相当于一个属性;可以将多种类数据存放在一张表中,但一般会根据实际情况将不同类的数据存储的多张表中,通过外键实现表之间的连接。每张表中的一行就是一个实例,一般会给每个实例分配一个独一无二的id,然后可id指定实例之间的关系。
数据建模
前面也提到过,在数据搜集、清洗过程中,要一直基于项目范围或需求,改善、优化知识建模。到目前,这一步已不是必须的,进行建模后,后续数据映射过程会更容易理解,主要使用的工具是protégé,也就是进行本体建模,protégé导出的文件一般后缀是.owl。
数据映射
对储存在mysql中的数据进行关系映射,可以使用工具D2RQ完成。可以使用D2RQ通过jdbc访问mysql数据库,将存储的数据映射为ttl文件;基于数据建模得到的本体文件中的结构关系,对生成的ttl文件进行修改;再使用D2RQ根据修改后ttl文件生成nt文件(N-TRIPLE格式的文件),里面保存的就是RDF数据。可以借鉴此链接https://blog.csdn.net/smallsmallbright?type=blog下的文章
- 数据存入mysql后,在D2RQ的安装目录下进入终端,运行以下指令generate-mapping -u $usrname -p $passward –o 映射文件.ttl jdbc:mysql:///mysql中对应数据库的名字,生成数据库的映射文件
- 根据构建的owl文件对基于数据库生成的映射关系的ttl文件修改
- 基于修改后的ttl文件建立nt文件,可以在D2RQ的安装目录下使用以下指令:.\dump-rdf.bat –o RDF文件.nt 映射文件.ttl,生成的RDF文件.nt中存放的就是三元组信息。D2RQ输出的默认格式是N-TRIPLE,即nt,其还支持TURTLE、RDF/XML等格式的,如果需要导成nt外的其他格式,需要使用-f进行指定,如下面的指令.\dump-rdf.bat -f TURTLE -o poem_kbqa.turtle poem_demo_mapping.ttl,就是基于ttl文件将mysql里面数据转换为TURTLE格式,后缀就是小写,即.turtle。.\dump-rdf.bat -f RDF/XML -o poem_kbqa.rdf poem_demo_mapping.ttl是导出为RDF格式
- 在jena的安装目录下创建tdb文件夹用于存放tdb数据,再进入jena目录下的bat目录,启动终端,通过指令 .\tdbloader.bat --loc=“E:\apache-jena-3.8.0\tdb”“E:\d2rq-0.8.1\RDF文件.nt” 在tdb文件夹创建数据
- 再进入Fuseki文件夹,第一次需要运行fuseki-server.bat文件自动创建run文件夹,将在protégé中创建导出的本体文件.owl移动到run文件夹下面的databases中,并将后缀修改为ttl。在run文件夹下的configuration文件加中创建一个fuseki_conf.ttl的文本文件(取名随意),不同项目大体相同,但需要进行部分修改
- 最后在Fuseki文件夹下运行以下指令开启endpoint服务 .\fuseki-server.bat --loc=E:\SoftwareInstallation\jena\apache-jena-3.8.0\tdb /poem_demo (此处的poem_demo与放在run/databases文件夹下的ttl文件同名,同时在run/configuration文件夹下面的fuseki_conf.ttl也要进行相应的修改)
注意事项
- 使用jena开启endpoint服务时,不要在之前启动过的tdb文件夹下开启,如果之前开启过其他项目的endpoint文件,最好把tdb文件夹删除重建或情况tdb文件夹,再在jena的bat目录重新使用指令.\tdbloader.bat --loc=“E:\apache-jena-3.8.0\tdb” “E:\d2rq-0.8.1\RDF文件.nt”(该问题待确认)
- 可以直接先以空的文件夹,用fuseki开启服务,然后访问localhost:3030地址后使用其提供的输入导入功能将创建好的nt文件导入。直接进入apache-jena-fuseki的文件夹,创建一个用以存放tdb数据的文件夹,名字可以自定义;终端也切换到apache-jena-fuseki文件夹下,使用指令:fuseki-server --loc=store --update /testds,其中sotre替换成前面创建的文件夹的名称,–update表示支持SPARQL Update数据更新操作,/tests是指定上传的数据集在服务上的名称。执行完指令后fuseki服务就启动了。
- 基于创建的nt文件使用jena启动endpoint服务前,生成tdb文件时创建的文件夹的名称不一定非要是“tdb”,任何名称都可以,只需要在上述步骤e和g中的–loc=后指定相应的路径就可以了。这样把不同图谱项目的文件存放在不同的文件夹下,并且启动时进行对应文件夹启动,就能防止知识混乱的问题
py2neo+neo4j
neo4j是目前使用最广泛的图数据库,其支持csv文件的直接导入,并且python的第三方库py2neo可以对neo4j进行访问、连接、节点和关系创建等操作。
Neo4j也支持owl、nt等RDF数据的导入,但是需要进行配置修改。首先根据安装的neo4j的版本至https://github.com/jbarrasa/neosemantics/releases网址下载对应版本的第三方的RDF文件导入库,文件后缀是.jar,将该文件放在neo4j安装目录中的plugins文件夹下;再在安装目录中conf文件夹下的neo4j.conf配置文件中的最后一行提交该语句“dbms.unmanaged_extension_classes=semantics.extension=/rdf”;保存后重启neo4j。启动后访问localhost:7474地址连接neo4j,初始密码和账号都是neo4j,运行查询语句 :GET /rdf/ping,如果返回{“ping”:“here!”}表明配置成功,可导入RDF文件了。
先执行CREATE INDEX ON :Resource(uri)语句,在数据库中创建一个名为Resource的节点,然后再执行CALL semantics.importRDF(“file:///{PROJECT_PATH}/RDF文件.nt”,“N-Triples”)语句,其中的${PROJECT_PATH}就是RDF文件.nt存放的绝对路径,到此就完成了nt文件的导入,使用call db.schema()语句,将Resource隐藏,能够看到nt文件中蕴含的schema结构。
在导入nt文件时,如果属性值存在特殊字符,如%、/等需要使用百分号编码,如%的百分号编码就是%25,不然会出现错误,使得导出失败;可以在终端进入neo4j的安装目录下的bin目录,执行neo4j.bat console开启服务,再执行导入指令,出现的错误编码会终端中输出,根据输出的错误信息进行问题定位。具体操作步骤可参考https://blog.csdn.net/ZHOUBEISI/article/details/84863503
导入RDF/XML文件的语句:CALL semantics.importRDF(“file:///E:/project5-kg-wash-function/rdf_file_20220825/xihu_with_cvt_0829_protege.rdf”, “RDF/XML”)
Neo4j的缺点:社区版本的单机系统,企业版知识高可用性集群,但是并不是真正的分布式图存储系统,其每个存储节点上都要存储完整副本,而不是将图数据划分为子图进行分布式存储。如果图数据超过一定规模,系统性能会因为磁盘、内存等限制而大幅降低
Py2neo与Neo4j的版本问题
当前本地安装的neo4j版本是3.5.30,使用4.0.0和2020版本的py2neo可以进行操作,2021.2.3版本的py2neo就不能操作该版本的neo4j。当neo4j版本升级为4.0以上版本时,前面列举的两个版本的py2neo又不能对该版本的neo4j进行操作;2021.2.3版本的py2neo可以对4.0版本的neo4j进行操作,但是该版本的py2neo又不能对3.5.30版本的neo4j进行操作。并且当使用2021.2.3版本的py2neo时,使用run函数执行cypher代码时,会报错不能将neo4j返回的数据解析为json类型数据,使得运行不成功;但是4.0.0和2020版本的py2neo却可以正常解析。使用2020.1.0版本的neo4j后可以解决上述问题,对当前3.5.30和4.0以上版本的neo4j都能进行操作,并且也能正常返回索引内容,推荐使用该版本的py2neo。
Py2neo导入三元组数据
- 针对项目要求,构建好本体架构,要确定一个知识图谱展开的中心类;如医疗问答的知识图谱的中心应该是疾病,而诗歌类型的知识图谱的中心应该是诗人等
- 节点的抽象定义相当于是一个class,而该类型的节点下的一个实体就相当于该class的一个实例;节点与节点之间的关系就是对象属性,而节点与一个单纯的值之间的关系就是数值属性。处理好数据后,要根据本体架构,提炼出所有节点的类型、节点与节点之间的关系(就是对象属性)以及每个节点拥有的属性(就是数值属性,如name)
- 遍历数据,将所有的节点、关系归纳保存,同时将中心类的所有数值属性单独保存,如果非中心类节点除了name还有以外的数值属性,也最好针对每个节点实例保存其所有的数值属性。使用py2neo先创建所有的中心类的节点实例,再创建其他非中心类的节点实例
- 再基于提取出的节点实例之间的对象属性即节点之间的关系,结合cypher查询语言进行关系创建,到此基本完成知识导入。在neo4j中可通过call db.schema()查看neo4j中存储的所有数据的scheme,即本体架构。
批量导入csv文件
除上述的三元组导入方式外,Neo4j支持直接从csv文件中导入
-
首先将csv文件的编码格式设置为utf-8,否则易出现中文乱码情况
-
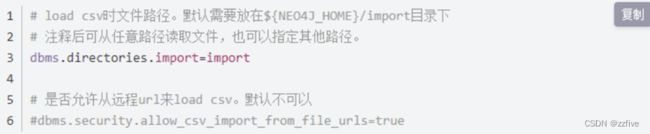
正常情况下,要将csv文件放置在neo4j安装目录的import目录下,如果需要从远程或者本地其他目录下导入数据,要将安装目录中conf下的neo4j.conf文件中进行一下修改
-
同样如使用py2neo导入数据一样,需要先从原始数据中提取出实体和关系,一般是将相同类存储在同一个csv文件中,第一列是ID,其实必须要的,后续的字段就相当于是给类的属性,也就是数值属性,不同的类存储在不同的csv文件中。然后将所有的关系存储在一个独立的csv文件中,一般是存储关系开始实体ID,关系结束实体ID,以及对应关系的类型
-
将实体和关系存储为csv文件后,就可以使用cypher语言或者apoc进行数据的批量导入,需要注意的是一般csv文件的第一行的字段名,使用cypher导入时语句添加with headers,就可使用line.value 或line[value]来获取每行即一个实体每个属性对用的值。如果一个实体拥有两个表示,就是属于两个类,最好是将该数据分别存在两个不同类的csv文件中。详情可参考此链接:
https://blog.csdn.net/sinat_36226553/article/details/108547440
rdflib库
如前面介绍所示,rdflib库可以直接创建rdf文件,也能解析已存在的rdf文件,然后在其上进行修改。如果构建好了csv的结构化文件,可以使用rdflib创建图,在其中声明类、实例、对象属性和数值属性,然后将图序列化为所需的rdf文件格式,目前其支持所有常用的rdf文件格式,如turtle、nt、n3、xml等(xml等价与‘RDF/XML’)。
使用rdflib创建实体节点时,需要在Namespace中声明唯一标识符,一定要注意不同实体节点的唯一标识符不能相同,实体的name属性可以相同,或者说所有属性都可以相同,但如果是两个不同的实体节点,就要赋予不同的唯一标识符。
在导入之前,可以先使用protégé将使用rdflib生成的rdf文件打开查看一下本体、关系是否正确合理,也可以进行一次转存,即使用protégé另存为所需的格式。如果所需的格式是protégé中不支持的,可以先保存为“RDF/XML”格式,再使用rdflib解析保存为所需格式。目前经过实践,按照前文“py2neo+neo4j“中描述的方法,Neo4j支持N-Triples、RDF/XML、Tutle格式的文件导入。