【OpenMMLab AI实战营第二期】目标检测笔记
目标检测
目标检测的基本范式
-
划窗
-
使用卷积实现密集预测
-
锚框
-
多尺度检测与FPN
单阶段&无锚框检测器选讲
-
RPN
-
YOLO、SSD
-
Focal Loss与RetinaNet
-
FCOS
-
YOLO系列选讲
什么是目标检测
目标检测:给定一张图片,用矩形框框出所有感兴趣物体同时预测物体类别
目标检测与图像分类区别
图像分类通常只有一个物体,位于图像中央,占据主要面积,目标检测中这些都不固定
单阶段目标检测算法
单阶段检测算法概述
单阶段算法直接通过密集预测产生检测框,相比于两阶段算法,模型结构简单、速度快、易于在设备上部署
早期由于主干网络、多尺度技术等相关技术不成熟,单阶段算法在性能上不如两阶段算法,但因为速度和简洁的优势仍受到工业界青睐
随着单阶段算法性能逐渐提升,成为目标检测的主流算法
RPN(Region Proposal Network)
RPN 初步删除图像中包含物体的物质,不预测具体类别
RPN算“半个检测器”,是二阶算法 Faster RCNN的第一阶段
RPN是基于密集预测的
YOLO(You Only Look Once)
是最早的单阶段检测器之一,激发了单阶段算法的研究潮流
主干网络:自行设计的DarkNet结构,产生771024维的特征图
检测头:2层全连接层产生77组预测结果,对应77个空间位置上物体的类别和边界
YOLO的匹配与框编码
将原图切分成SS大小的格子,对应预测图上SS个位置
如果原图上某个物体中心位于某个格子内,则对应位置的预测值应给给出物体类别和边界框位置
其余位置应预测为背景类别,不关心边界框预测结果
优点:
速度快:在Pascal VOC数据集上,使用自己设计的DarkNet结构可以达到实时速度,使用相同的VGG可以达到3倍与Faster R-CNN的速度
缺点:
由于每个格子只能预测一个物体,因此对重叠物体,尤其是大量重叠的小物体容易产生漏检
直接回归边界框(无锚框)有难度,回归误差较大,YOLO V2开始使用锚框
SSD(Single Shot MultiBox Detector)
主干网络:使用VGG+额外卷积层,产生11级特征图
检测头:在6级特征图上进行密集预测,产生所有位置,不同尺度的预测结果
RetinaNet
特征生成:ResNet主管网络+FPN产生P3~P7共五级特征图,对应采样率8-128倍
多尺度锚框:每个特征图上设置3种尺寸*3种长宽比的锚框,覆盖82-813像素尺寸
密集预测头:两分支、5层卷积构成的检测头,针对每个锚框产生K个二类预测以及4个边界框偏移量
损失函数:Focal Loss
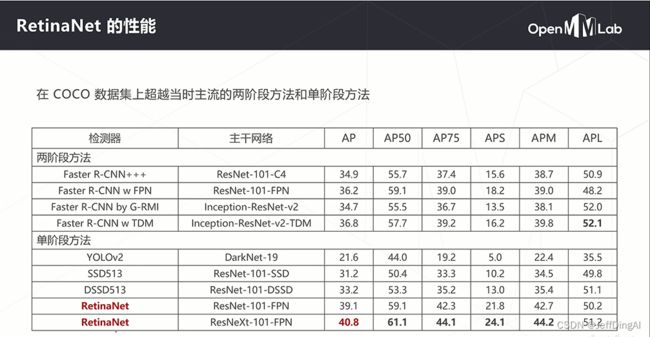
性能
单阶段算法面临的正负样本不均衡问题
单阶段算法共产生尺度数位置数锚框数个预测
而这些预测之中,只有少量锚框的真值为物体(正样本),大部分锚框的真值为背景(负样本)
使用类别不平衡的数据训练处的分类器倾向给出背景预测,导致漏检
朴素的分类损失不能驱动检测器在有限的能力下达到漏检和错检之间的平衡
YOLO V3
自定义的DarkNet-53主干网络和类FPN结构,产生1/8、1/16、1/32降采样率的3级特征图
在每级特征图上设置3个尺寸的锚框,锚框尺寸通过对真值狂聚类得到
两层卷积构成的密集检测头,在每个位置、针对每个锚框产生80个类别预测、4个边界框偏移量、1个objectness预测,每级特征图3*(80+4+1)=255通道的预测值
得益于相对轻巧的主干网络设计、YOLO V3的速度圆冠榆RetinaNet
YOLO V5
模型结构进一步改进、使用CSPNarkNet主干网络、PAFPN多尺度模块
训练时使用更多数据增强,如Mosaic、MixUP
使用自对抗训练技术(SAT)提高检测器的鲁棒性
无锚框目标检测算法
基于锚框
-
Faster R-CNN、YOLO V3/V5、RetinaNet都是基于锚框的检测算法
-
模型基于特征预测对应位置中是否有物体,以及精确位置相对于锚框的偏移量
-
实现复杂,需要手动设置锚框相关超参数(如大小、长宽比、数量等),设置不当影响检测精度
无锚框
- 不依赖锚框,模型基于特征直接预测对应位置是否有物体以及边界框的位置
- 边界框预测完全基于模型学习,不需要人工调整超参数
FOCS(Fully Convolutional One-Stage)
模型结构与RetinaNet基本相同:主干网络+FPN+两分支、5层卷积构成的密集预测头
预测目标不同:对于每个点位、预测类别、边界框位置和中心度三组数值
FCOS的预测目标&匹配规则
如果某个特征位于某个真值框的内部,且特征的层级与真值框的尺度匹配,则该特征对应正样本,应预测物体的
-
类别概率
-
边界框相对于该中心位置的偏移量
-
中心度,对于衡量预测框的优劣
如果某个特征不位于真值框内部,或与真值框尺度不匹配、对应负样本,只需预测类别为背景
对比:Anchor-Based算法基于IOU匹配,通常Anchor需要预测与之交并比大于阈值的框
FCOS的多尺度匹配
Anchor-based算法根据锚框和真值框的IoU为锚框匹配真值框通常,锚框会匹配到同尺度的真值框,小物体由底层特征预测,大物体由高层特征图预测
问题:Anchor-free 算法没有锚框,真值框如何匹配到不同尺度?
匹配方案:每层特征图只负责预测特定大小的物体,例如右图中512像素以上的物体匹配到P7上
由于重叠的物体尺度通常不同,同一位置重叠的真值框会被分配到不同的特征层,从而避免同一个位置需要预测两个物体的情形
CenterNet
针对2D检测的算法,将传统检测算法中的“以框表示物体”变成“以中心点表示物体”,将2D检测建模为关键点检测和额外的回归任务,一个框架可以同时覆盖2D检测、3D检测、姿态估计等一系列任务。
YOLO X
以YOLO V3为基准模型改进的无锚框检测器
-
Decouple Head结构
-
更多现代数据增强策略
-
SimOTA分配策略
-
从小到大的一系列模型
SOTA的精度和速度